3.kafka-rocketmq对比-MQ
底层存储
kafka
Kafka部分名词解释如下:
Broker:消息中间件处理结点,一个Kafka节点就是一个broker,多个broker可以组成一个Kafka集群。
Topic:一类消息,例如page view日志、click日志等都可以以topic的形式存在,Kafka集群能够同时负责多个topic的分发。
Partition:topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列。
Segment:partition物理上由多个segment组成。
offset:每个partition都由一系列有序的、不可变的消息组成,这些消息被连续的追加到partition中。partition中的每个消息都有一个连续的序列号叫做offset,用于partition唯一标识一条消息.(只在partition下唯一)
同一个topic下有多个不同partition,每个partition为一个目录,命名规则为topic名称+partition的有序序号
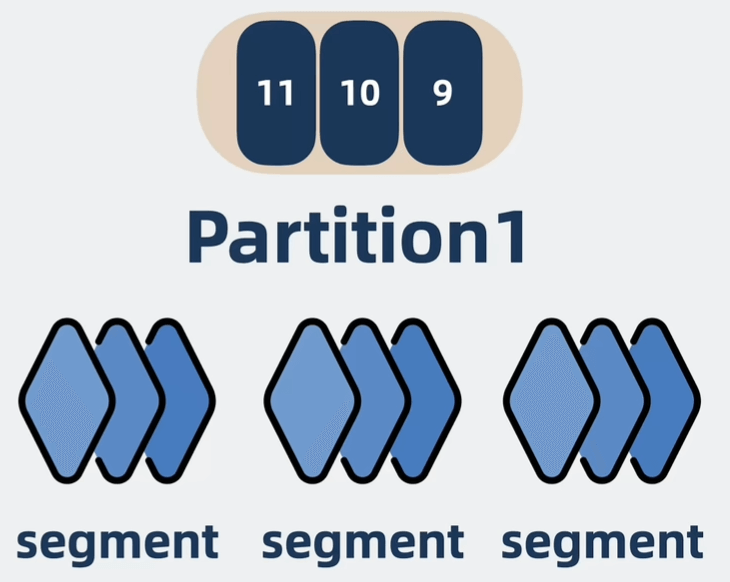
一个partition相当于一个巨型文件,被顺序分配到了多个segment文件中,文件名为当前第一条消息的offset

segment文件组成
- xxxx.log:日志数据文件,按照固定的格式存储生产者分送过来的消息数据
- xxxx.index:索引文件,该文件主要记录了哪条消息(offset)写在对应的xxxx.log文件中的哪个位置(position),查询消息时首先查询该文件,然后再去日志数据文件中读取对应的消息数据。(稀疏索引存储的,也就是每隔几条消息数据建一条索引。所以在查找该条消息时只需要找到对应的消息编号最近的索引位置,然后再在数据文件中顺序查找。)
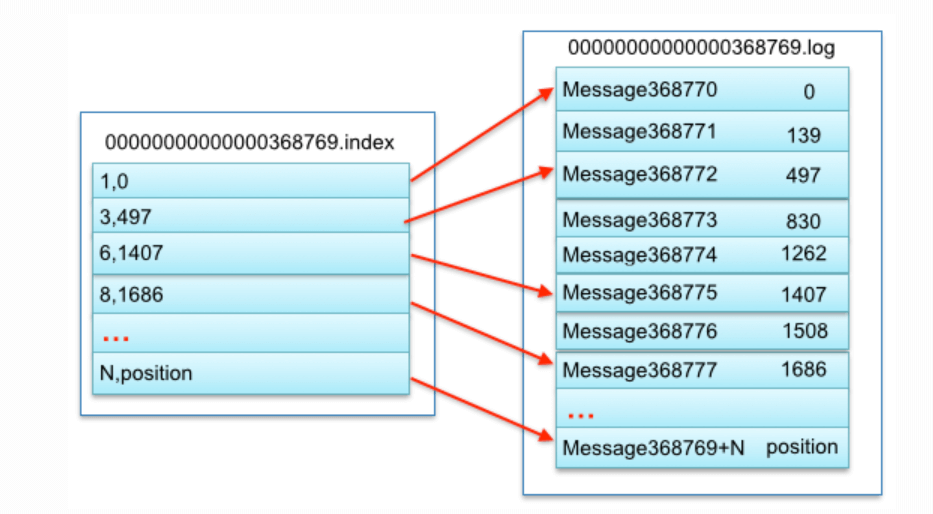
当消费者给出一个offset,需要查找该消息:
例如读取offset=368776的message,需要通过下面2个步骤查找。
- 第一步二分查找segment文件,因为文件名是按照offset来命名的
- 找到正确的
.index文件后,Kafka 使用该索引文件中的记录,定位消息在.log文件中的大致物理位置。由于 Kafka 的索引是稀疏的,可能并不会直接定位到目标offset对应的精确位置,因此 Kafka 会从索引定位的物理地址开始,顺序读取.log文件,直到找到目标offset的消息。
为什么需要index文件:
segment.log文件中存储的每一条消息长度是不一样的,因此如果直接查找需要遍历整个大的log文件,一条一条对比offset,而有了index文件后,变成了O(log n)(二分查找索引)+ O(k)(扫描少量消息)
写(生产)消息:
- index文件较小,可以直接用mmap进行内存映射
- segment文件较大,可以采用普通的write(FileChannel.write),由于是顺序写PageCache,可以达到很高的性能
读(消费)消息:
- index文件仍然通过mmap读,缺页中断的可能性较小
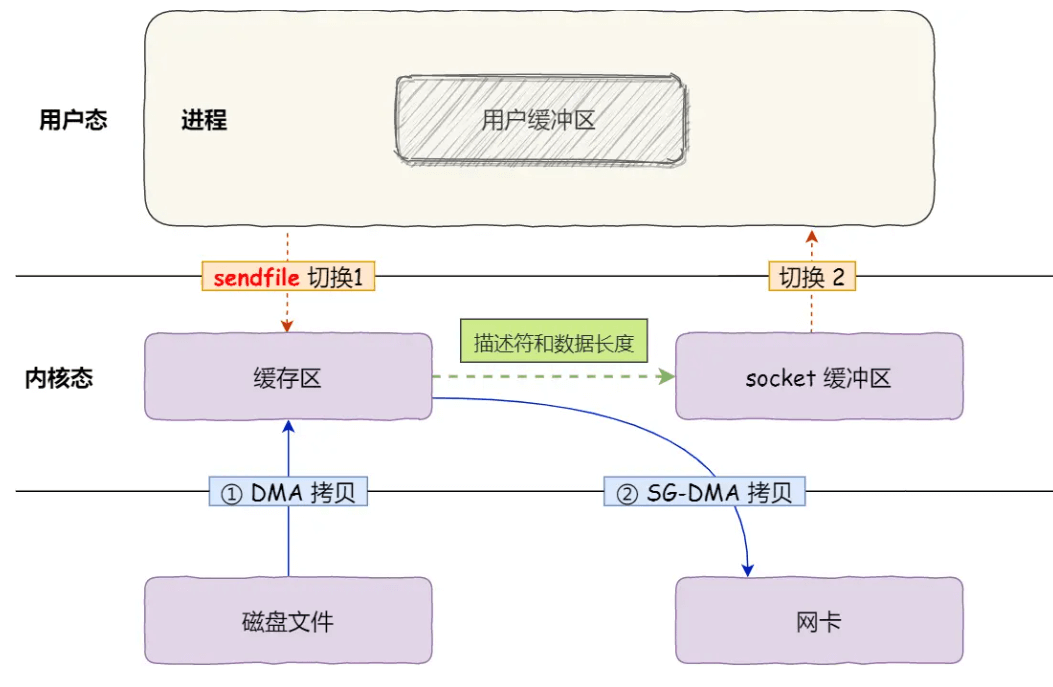
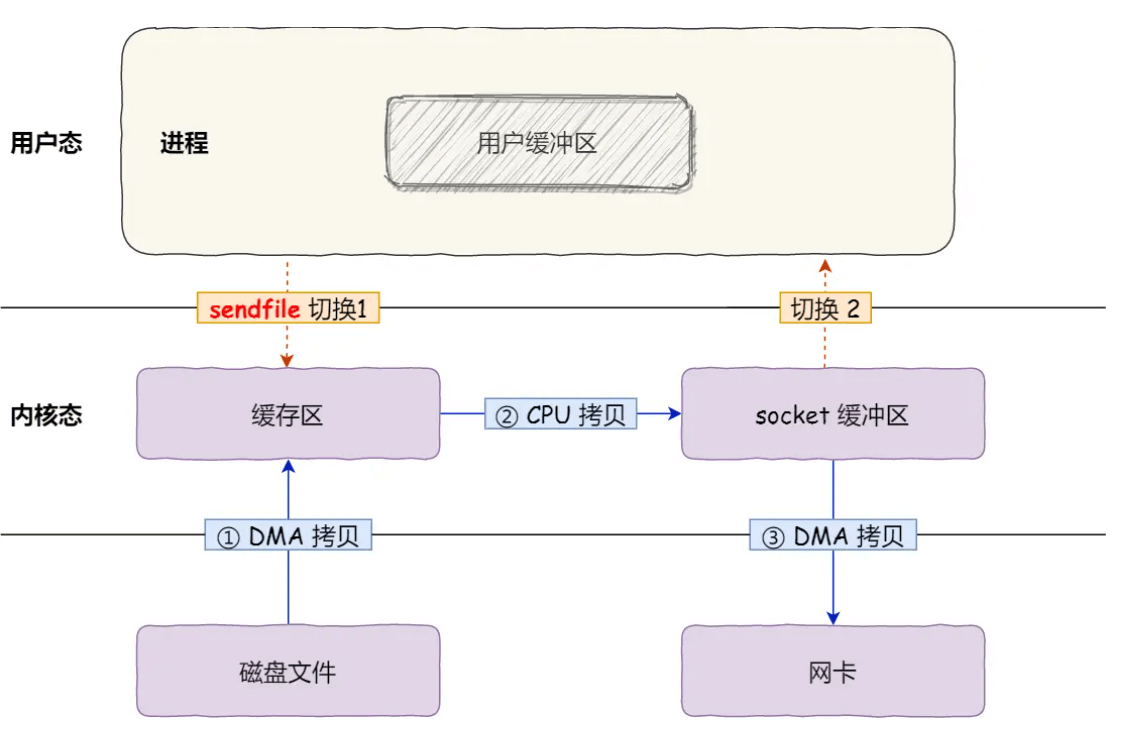
- segment可以使用sendfile进行零拷贝的发送给消费者,达到非常高的性能
1 | |
存在问题:
在Kafka文件读写中,针对segment文件写入是采用顺序write的,但是如果topic数量以及下面parition数量一多,从操作系统的角度看就变成了随机写入,导致写入性能下降。
rocketmq
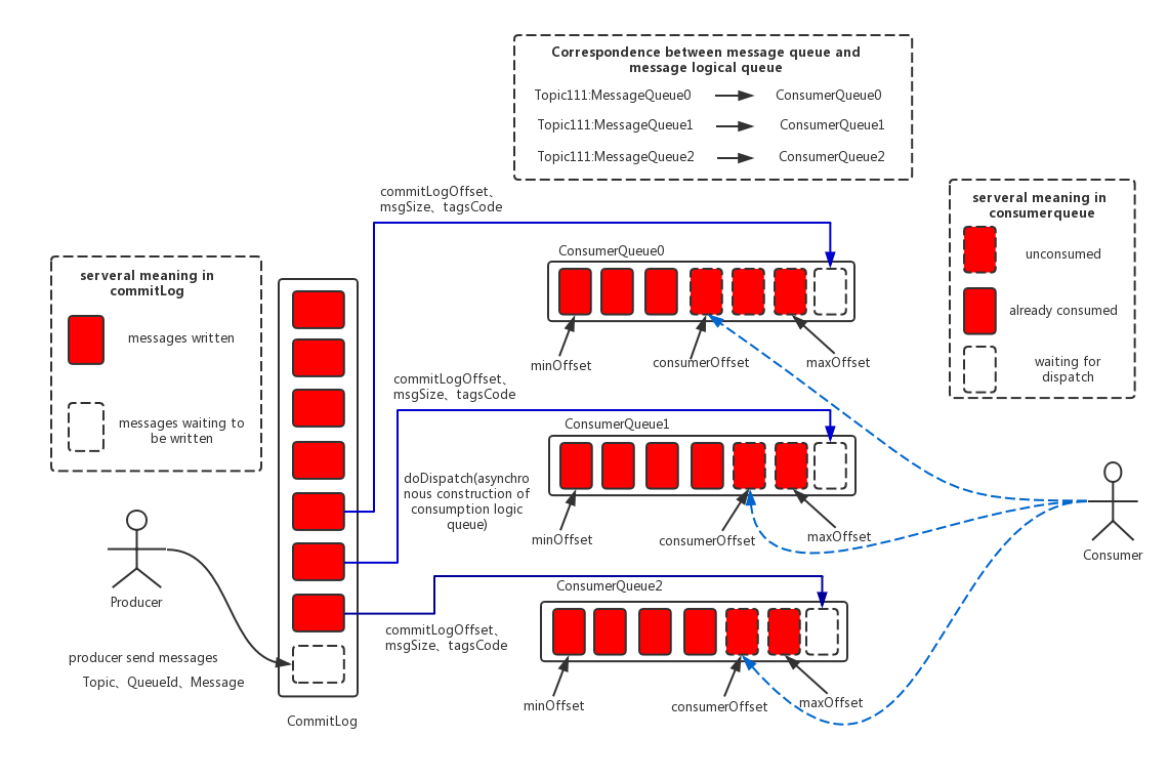
- 所有的消息数据(不同topic、不同队列)都写入同一个文件(当然物理存储时还是会以固定大小进行文件切割),这个文件称之为CommitLog
- 为了加速消费消息,建立轻量级索引,为每个队列新增ConsumeQueue文件,存储消息在CommitLog中的文件偏移量,而不是像kafka一样存储完整的消息内容 topic/queue/file
- 现在读取变成了两次,先去queue读偏移,再去CommitLog读数据
写(生产)消息:
- 无论是ConsumeQueue还是CommitLog都使用mmap进行写
读(消费)消息:
- 无论是ConsumeQueue还是CommitLog都使用mmap进行读
1 | |
小结
| Kafka | RocketMQ | |
|---|---|---|
| 文件结构 | 1.index索引文件 +log文件 2.多个队列多个segment消息文件 |
1.ConsumeQueue索引文件 2.多个队列一个CommitLog消息文件 |
| IO写 | 1.index文件采用mmap 2.segment采用write | 均采用mmap |
| IO读 | 1.index文件采用mmap 2.segment采用sendfile | 均采用mmap |
| 优点 | 1.每个topic的队列互不影响 2.数据量较大(>4kb)时写入性能更高 3.消费时可以利用sendfile+DMA零拷贝机制 |
1.commitLog完全顺序写 2.单机可以配置更多队列 |
| 缺点 | 1.单机队列配置较多时,有性能损失 | 1.随机读遇到缺页中断成本高 2.不能利用sendfile机制 |
架构上做减法
功能
rocketmq
- tag过滤
- 支持事务
- 延时队列
- 死信队列
sendfile更快,为什么rocketmq不使用?
sendfile 更适用于简单的文件传输,而 RocketMQ 需要对消息数据进行一定的处理和转换(例如死信队列)。mmap 允许直接在用户态中对文件数据进行操作,提供了更大的灵活性。