1.为什么要引入MQ-MQ
MQ有哪些优点,为什么需要MQ?
优点
异步
一个秒杀系统包含很多步骤,有的很重要,有的不重要。借助MQ可以只保留核心流程,提升系统性能
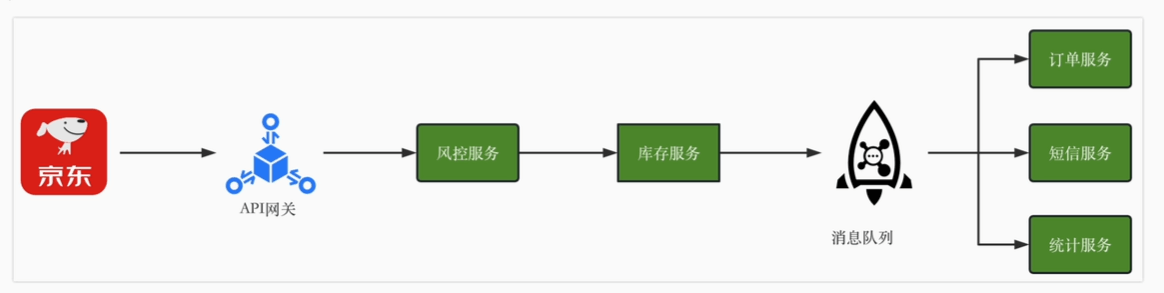
流量扩展
流量:web前端可以上千万请求,但数据库(分库分表)是万级别水平
简单实现,压测评估流量,并引入限流算法:
- 固定窗口
- 滑动窗口
- 漏桶算法
- 令牌桶算法
加入异步后,秒杀流程
- 收到请求后,将整个请求加入MQ
- MQ消费者异步完成秒杀过程,处理响应
- 轮询秒杀结果
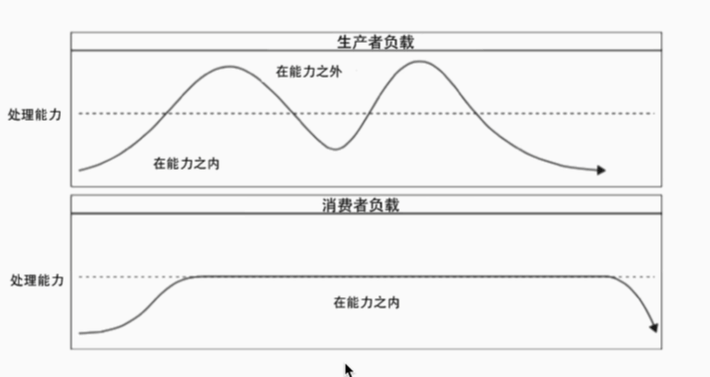
增加MQ可以削峰填谷
代价:
- 增加了系统调用环节,总体响应时间延长
- 同步->异步 增加了系统复杂度
- 成本问题:MQ的高性能 高可用
服务解耦
微服务之间如何通信?
调用链模式

聚合器模式
- 一调多
基于事件的异步
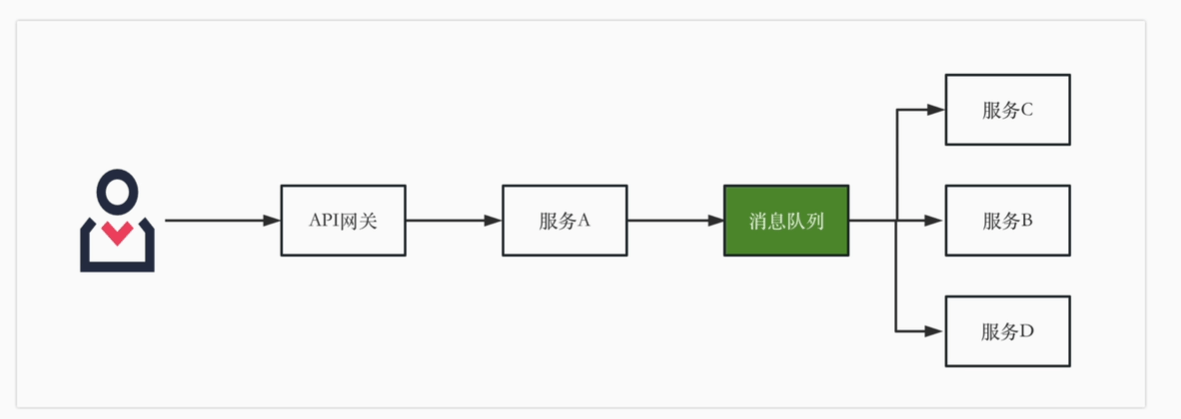
电商系统,订单信息变动后上游发出消息,对于下游服务来说,只需要订阅相关的主题的消息,下游就可以收到消息,增加或者减少下游,上游服务都不需要变化,实现了上游服务和其他服务的解耦
如何选型
基本特性
- 可靠性:消息不丢失
- 高可用:可用集群,某个宕机整体还可以运行
- 高性能
Rabbitmq
特点:
- Erlang语言编写,轻量级,基于AMQP 协议
- 灵活的路由机制:交换机
- 客户端支持多
问题:
- 消息堆积支持不好
- 性能较差(几万~十万)
RocketMQ
- 经历过双十一考验,速度快
Kafka
- 处理海量日志,大数据和流计算场景,周边生态好
- 几十万条消息
- 异步批量设计(可能会影响实时性)
选型
- 简单易用,性能不需要很高:RabbitMQ
- RocketMQ一致性良好、低延时、稳定
- 例如订单完成后通知物流,实现解耦
- 最终一致性的分布式事务
- Kafka:大数据、日志
- 数据埋点:电商用户行为日志(点击、购买),收集后提供给计算引擎进行实时计算分析,得出营销活动的转化率
- 监控、大数据分析:收集监控系统、传感器、日志信息进行实时分析和处理
消息队列模型
队列模型
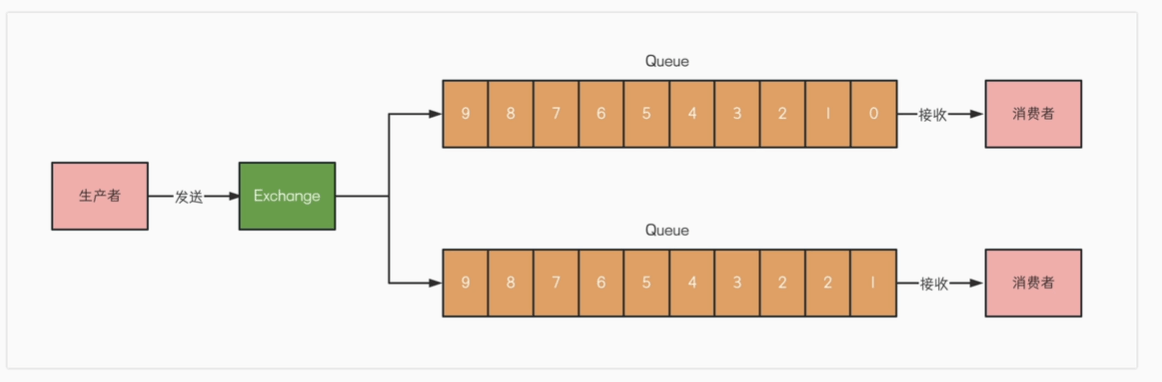
最初的消息模型:队列模型
生产者Producer发送消息就是入队,消费者Consumer消费消息就是出队
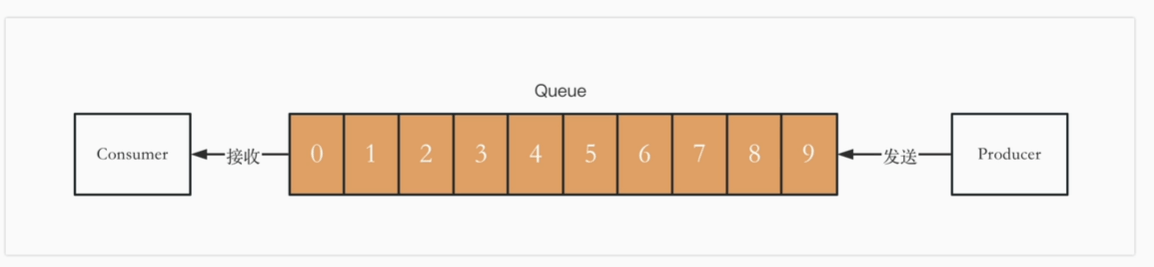
默认所有消费者共同消费所有消息
如何让多个消费者收到呢? 交换机exchange根据策略转发到多个队列
发布订阅模型
发布者Publisher、接收者Subscriber、主题Topic
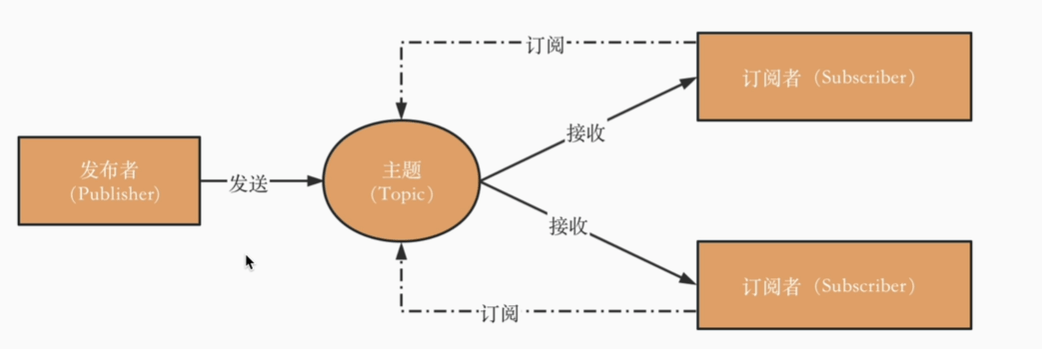
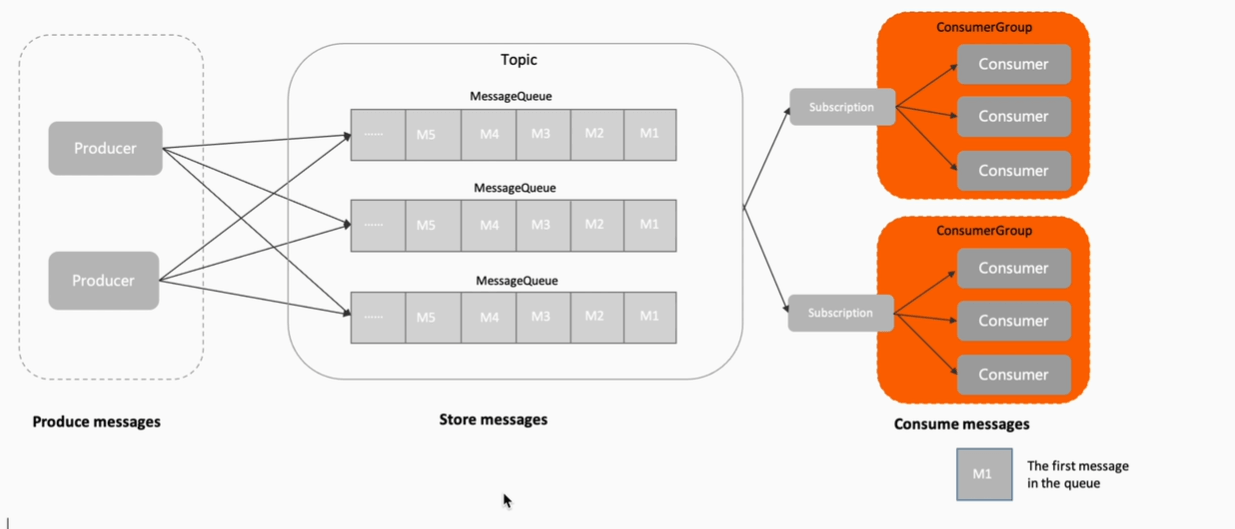
默认订阅者都可以接受完整的消息,rocketmq中是消费组可以消费完整消息,组内是竞争关系
- 如何保证有序性?topic中引入队列,队列中消息有序(Orderly模式下、Concurrently不保证)
- 每一个消费组中每一个queue都会维护一个offset
几乎所有MQ都是“请求-确认机制”
- broker接收到消息后,会发送确认,如果生产者没有收到确认,会重新发送
- 消费者消费后,会发送确认消息,否者MQ会重新发送消息
消费模式&重复消费问题
1. 至少一次(At-Least-Once)
- 定义:消息会被至少消费一次,即消费者可能会收到重复的消息。
- 原理:消息队列会在消息投递后,等待消费者的确认(ACK)。如果消费者处理失败或ACK没有及时收到,消息队列会重新投递该消息。因此,消费者可能会处理同一条消息多次(消费组幂等性)。
- 特点
- 可靠性高:消息不会丢失,但可能会重复。
- 应用场景:适用于对消息丢失敏感的场景,但允许重复消费的场景,比如日志系统、支付系统(必须通过幂等性保证结果一致)。
2. 仅一次(Exactly-Once)
- 定义:消息会被准确消费一次,即不会重复投递或消费。
- 原理:这是最复杂的交付模式,通常通过消费者的幂等性处理或者分布式事务保证。消息队列和消费者之间需要实现严格的幂等性机制或事务机制,确保每条消息只被处理一次且不会遗漏。
- 特点
- 高可靠性且无重复:不会丢失或重复消息,保证消息精确传递和处理。
- 应用场景:适用于对数据处理准确性要求极高的场景,比如银行交易、库存管理系统。
- 实现难度:通常实现较为复杂,性能也可能较低,因为要处理事务、幂等和重试机制等。
3. 最多一次(At-Most-Once)
- 定义:消息会被最多消费一次,即消费者可能会漏掉一些消息。
- 原理:消息在传递给消费者后,不需要等待确认,即使消费者处理失败,消息也不会重发。这种模式保证不会重复消费,但可能会导致消息丢失。
- 特点
- 低可靠性:消息可能丢失,但绝不重复。
- 应用场景:适用于对消息丢失不敏感的场景,如缓存更新、临时通知等。
最佳实践:At-Least-Once + 消费者幂等
- 消费者更新前检查版本,有点像
- 全局唯一ID + 状态检查 + 分布式锁
消息可靠性

生产者:发送确认
- 刷盘策略 影响可靠性
- rocketmq FlushDiskType调整为同步刷盘,刷盘后ack
- 复制策略 影响可用性
- 同步复制:也叫 “同步双写”,也就是说,只有消息同步双写到主从节点上时才返回写入成功 。
- 异步复制:消息写入主节点之后就直接返回写入成功 。
- DLedger 模式下复制到集群中半数以上的节点,才返回ack
- kafka: acks=all 全部、 ack=0 发送立即返回、 ack=1 主写入成功后返回
消费者:手动提交
消息挤压
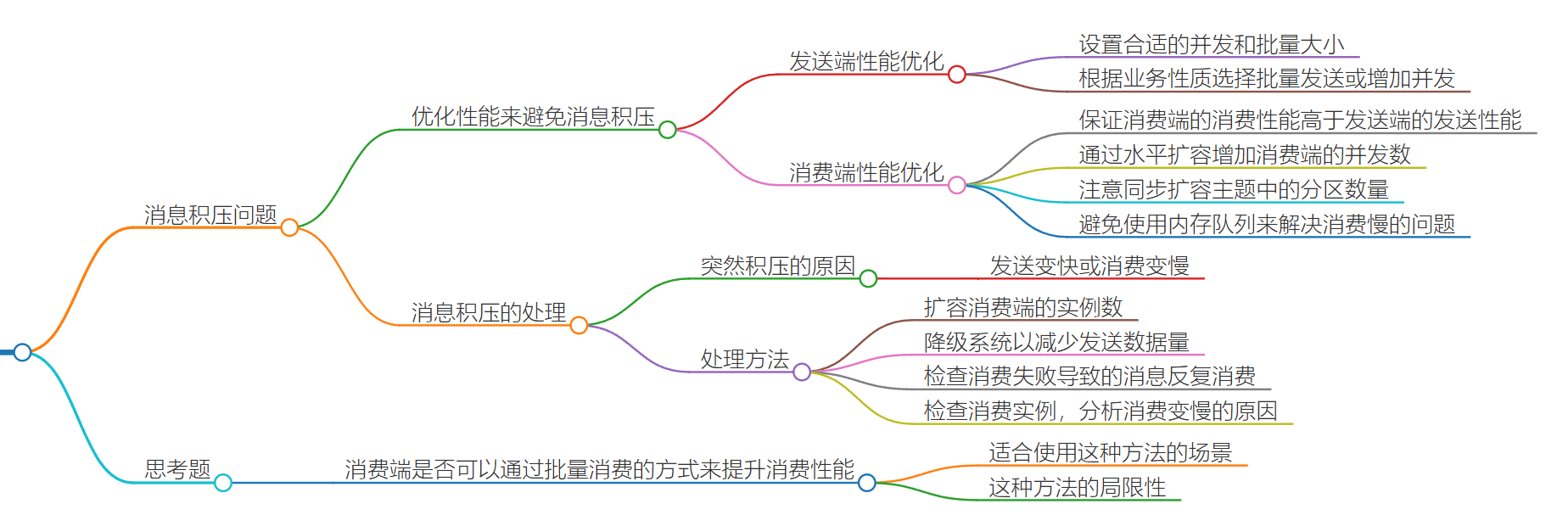
1.和消息生产者无关
2.和消息队列本身无关,消息队列可以十万QPS 还可以扩容,性能远高于业务
突发问题:应急处理 扩容增加消费者数量、降级系统(关闭不重要的业务)以减少发送数据量
后续:扩充消费者数量以及topic分区数量、消费端代码性能(是不是死锁、资源卡死)
顺序消费


业务实现

- 消息发送时给一个唯一递增ID,消费时id必须递增; 不保证有序但可以递增
- ID换成时间戳