IO模型介绍
引入
什么是IO?:输入输出模型,常见包含磁盘IO、网络IO
流程
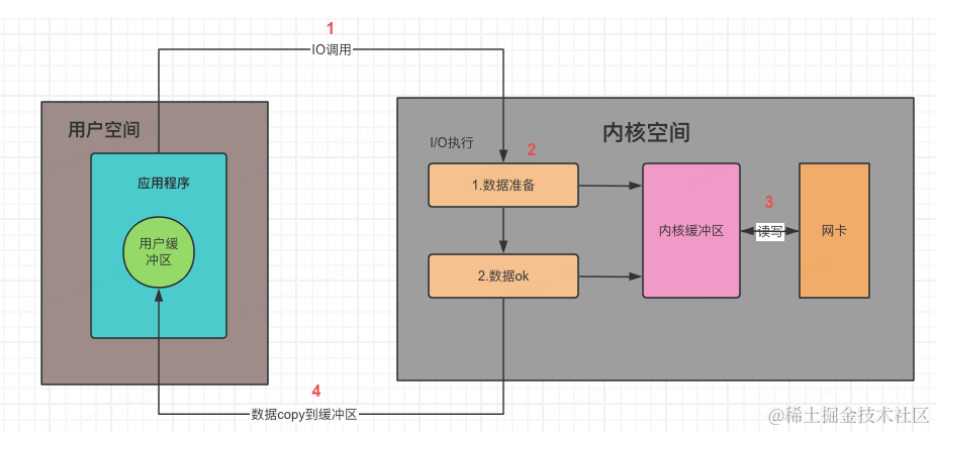
一次IO包含以下过程:
- 应用程序向操作系统发起IO请求,等待数据就绪(等待到网卡&网卡到达内核缓冲区)
- 操作系统拷贝内核数据到用户缓冲区
分类
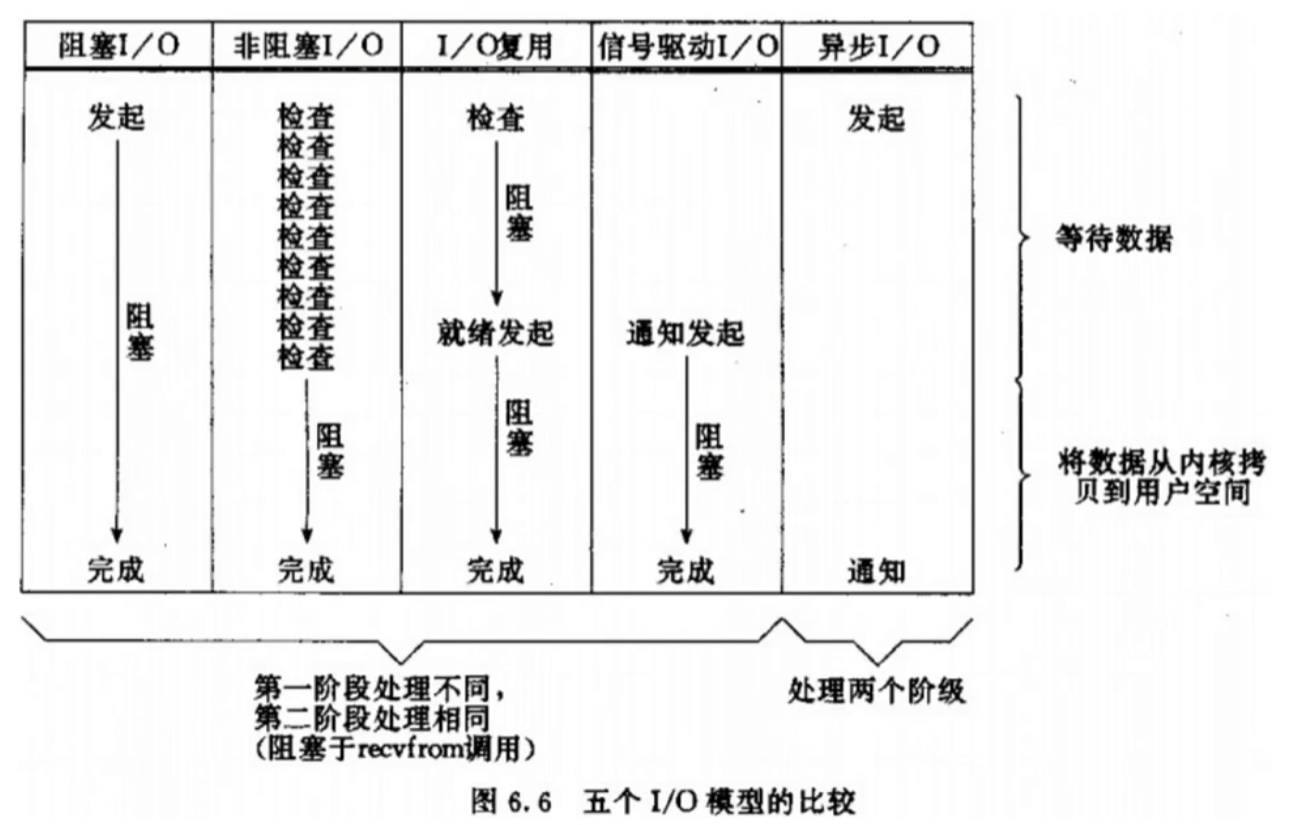
同步和异步关注的是消息通信机制.
- 同步:就是在发出一个调用时,自己需要参与等待结果的过程,则为同步,前面四个 IO 都自己参与了,所以也称为同步 IO.
- 异步:则指出发出调用以后,到数据准备完成,自己都未参与,则为异步 IO。
1.阻塞IO
1 | |
流程如下:
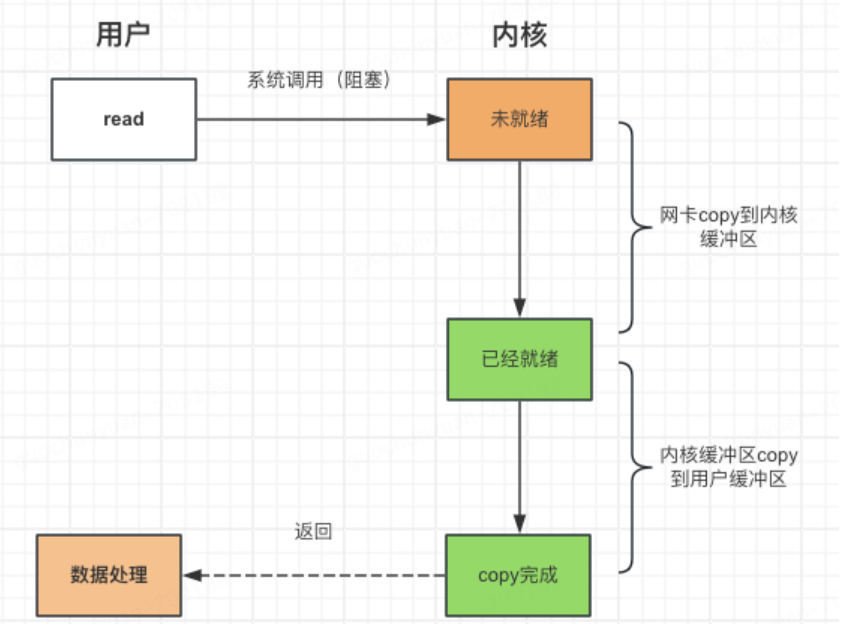
- 第一阶段如果阻塞了,当前线程会进入睡眠状态,直到数据就绪后唤醒
- 没有cpu空转,但一个线程只能处理一个fd
缺点:单一线程无法同时处理多个FD,如果需要处理多个FD需要开启多个线程,线程消耗比较大,线程切换开销也大
1 | |
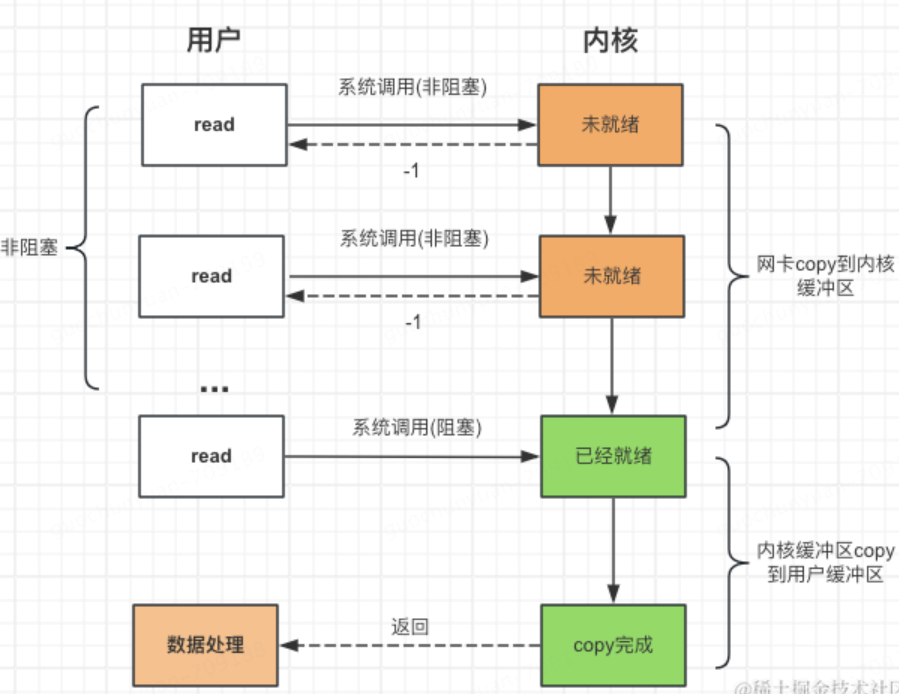
2.非阻塞IO
提供一个read函数,在数据未就绪时返回-1,因此可以通过轮询来处理
1 | |
- 非阻塞IO不会等待数据到达内核的这个阶段,提供了我们在一个线程内管理多个FD的能力
- for轮询会消耗大量的CPU,read进行系统调用也十分消耗资源
多路IO复用
1 个线程处理 多个 fd 的模式,并且避免无效的工作,要把所有的时间都用在处理句柄的 IO 上,不能有任何空转,sleep 的时间浪费。
如何实现?: 依靠内核,把想要处理的fd告诉内核,然后线程就休眠,之后只要有一个fd就绪,线程就被唤醒处理
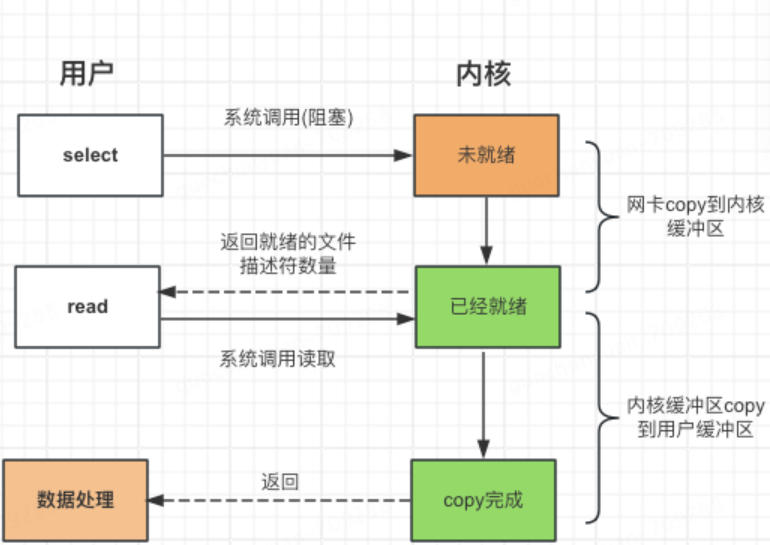
3.select
select 是操作系统提供的系统函数,通过它我们可以将文件描述符发送给系统,让系统内核帮我们遍历检测是否可读,并告诉我们进行读取数据。
1 | |
优点:
- 同时给操作系统多个fd,然后自己阻塞休眠,由操作系统负责检查是否可读,并通知唤醒我们
缺点:
- fd_set需要拷贝两次,用户->内核->用户
- 内核检测文件描述符可读还是通过遍历实现,当文件描述符数组很长时,遍历操作耗时也很长。
- 内核检测完文件描述符数组后,当存在可读的文件描述符数组时,用户态需要再遍历检测一遍。
- 最多1024个
4.poll
去掉了最大 1024 个文件描述符的限制
- select 使用固定长度的 BitsMap,表示文件描述符集合,而且所支持的文件描述符的个数是有限制的,在 Linux 系统中,由内核中的 FD_SETSIZE 限制, 默认最大值为 1024,只能监听 0~1023 的文件描述符。
- poll 不再用 BitsMap 来存储所关注的文件描述符,取而代之用动态数组,以链表形式来组织,突破了 select 的文件描述符个数限制,当然还会受到系统文件描述符限制。
5.epoll
1.每次调用需要在用户态和内核态之间拷贝文件描述符数组,但高并发场景下这个拷贝的消耗是很大的。
方案:内核中保存一份文件描述符,无需用户每次传入,而是仅同步修改部分。2.内核检测文件描述符可读还是通过遍历实现,当文件描述符数组很长时,遍历操作耗时也很长。
方案:通过事件唤醒机制唤醒替代遍历。3.内核检测完文件描述符数组后,当存在可读的文件描述符数组时,用户态需要再遍历检测一遍。
方案:仅将可读部分文件描述符同步给用户态,不需要用户态再次遍历。
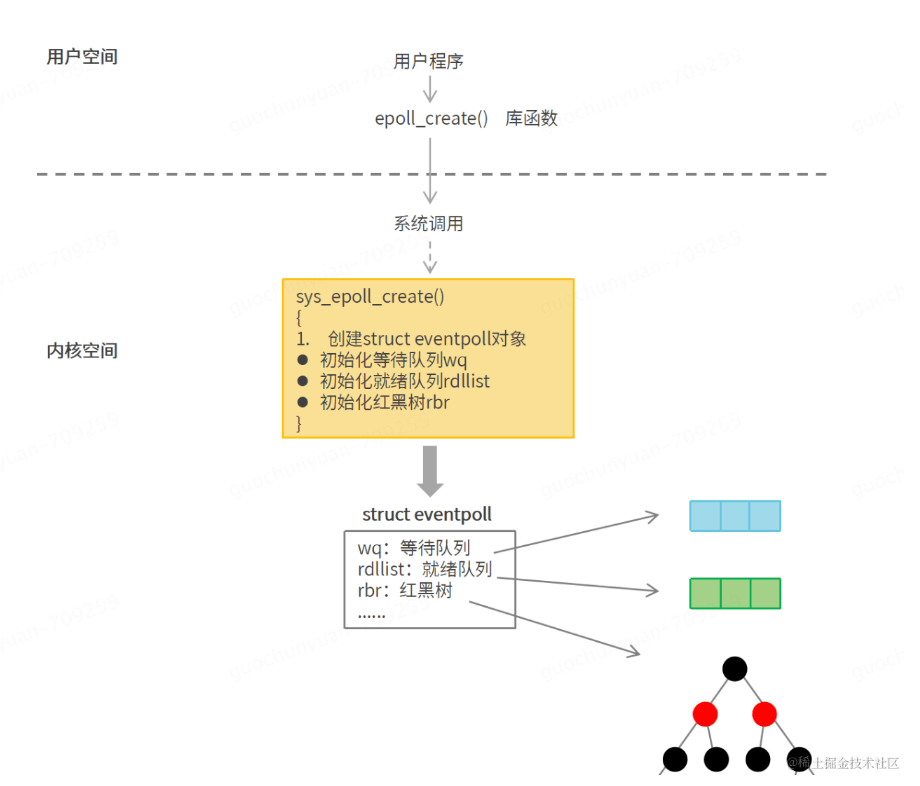
epoll_create:
用于创建 epoll 文件描述符,该文件描述符用于后续的 epoll 操作,参数 size 目前还没有实际用处,我们只要填一个大于 0 的数就行。
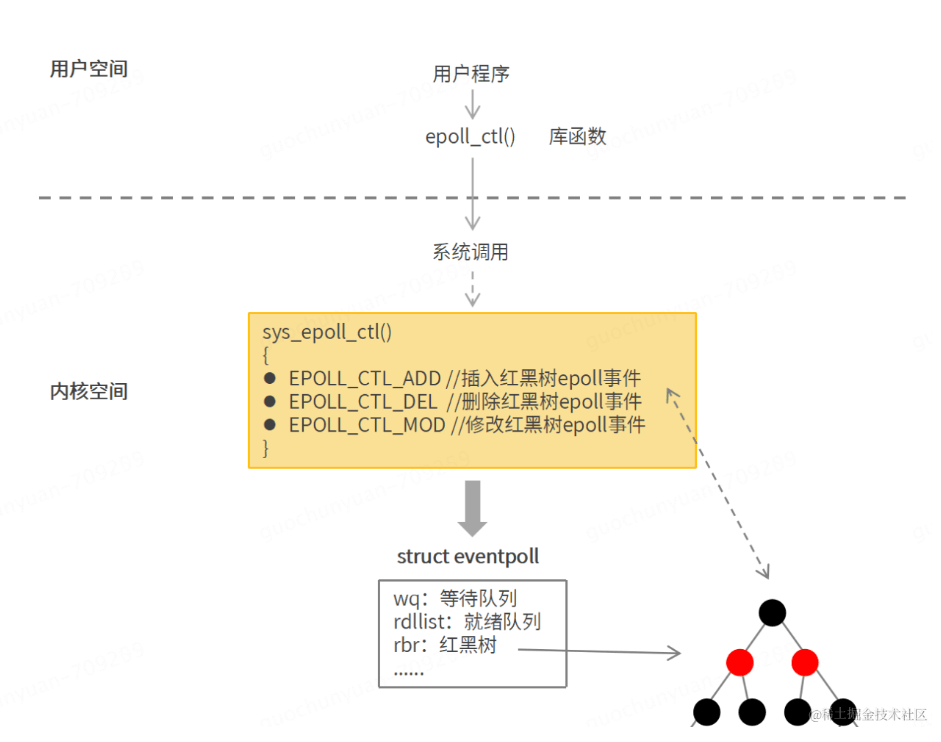
epoll_ctl:
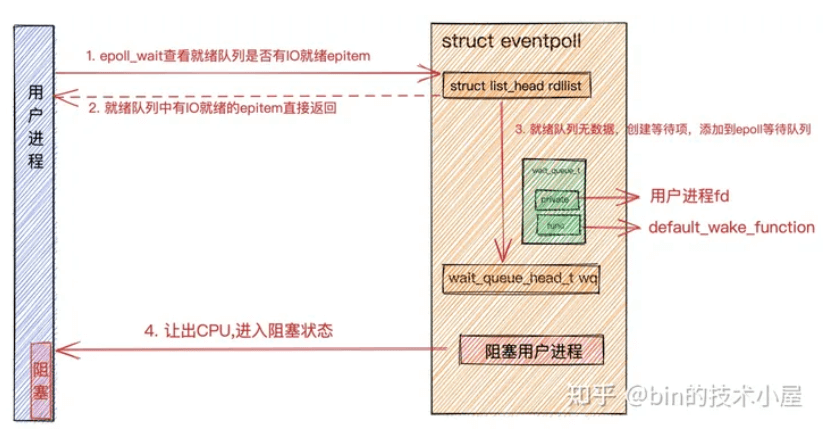
epoll_ctl 函数用于增加,删除,修改 epoll 事件,epoll 事件会存储于内核 epoll 结构体红黑树中.
会注册fd的就绪回调函数为ep_poll_callback,就绪时添加到rdllist,并唤醒wq中等待的线程
epoll_wait :
epoll_wait 用于监听套接字事件,可以通过设置超时时间 timeout 来控制监听的行为为阻塞模式还是超时模式。
详细的原理实现可以看另一篇文章:从FD到socketFD再到epoll原理
信号驱动 IO:
多路转接解决了一个线程可以监控多个 fd 的问题,但是 select 采用无脑的轮询就显得有点暴力,因为大部分情况下的轮询都是无效的,所以有人就想,别让我总去问数据是否准备就绪,而是等你准备就绪后主动通知我,这边是信号驱动 IO。
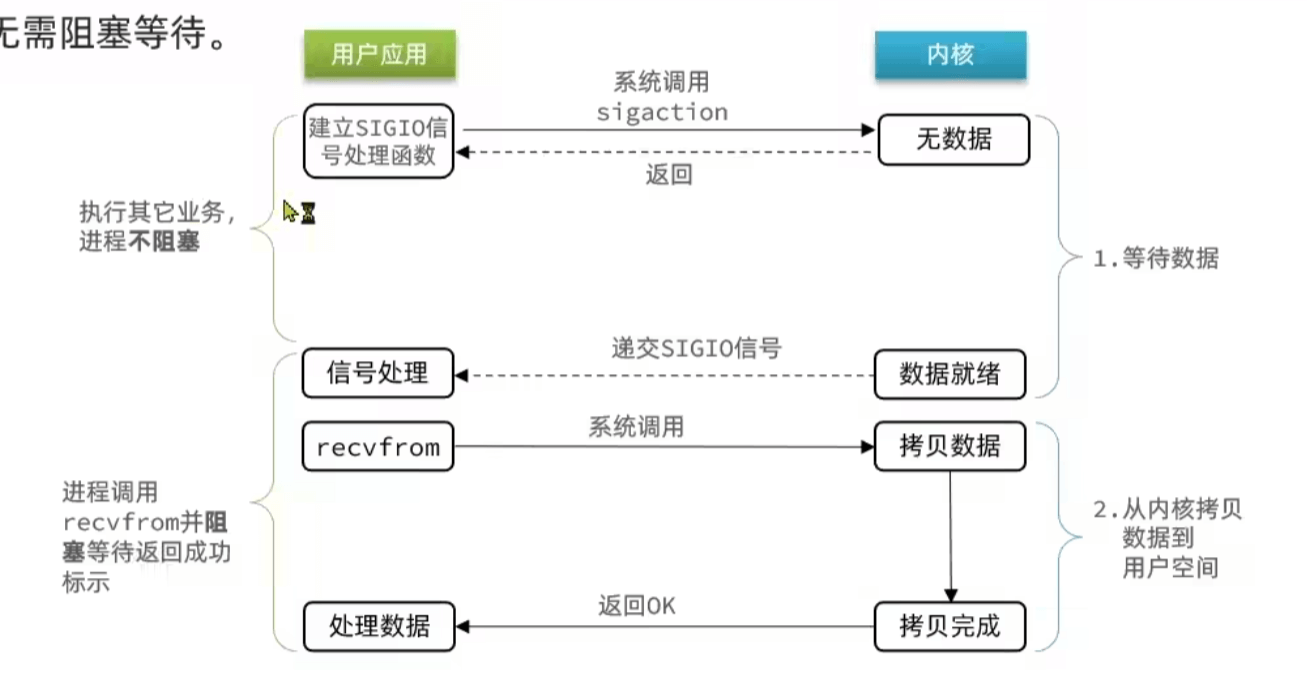
信号驱动 IO 是在调用 sigaction 时候建立一个 SIGIO 的信号联系,当内核准备好数据之后再通过 SIGIO 信号通知线程,此 fd 准备就绪,当线程收到可读信号后,此时再向内核发起 recvfrom 读取数据的请求,因为信号驱动 IO 的模型下,应用线程在发出信号监控后即可返回,不会阻塞,所以一个应用线程也可以同时监控多个 fd。
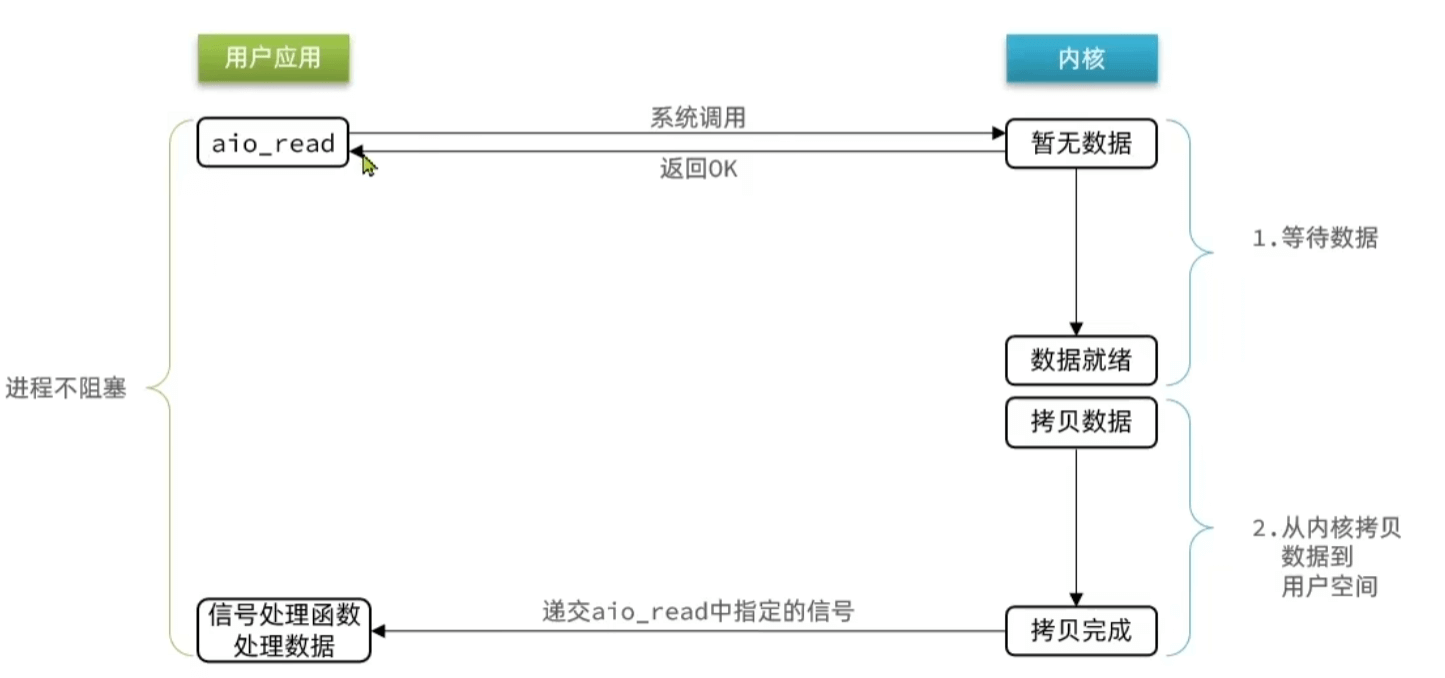
异步 IO
应用只需要向内核发送一个读取请求,告诉内核它要读取数据后即刻返回;内核收到请求后会建立一个信号联系,当数据准备就绪,内核会主动把数据从内核复制到用户空间,等所有操作都完成之后,内核会发起一个通知告诉应用,我们称这种模式为异步 IO 模型。
异步 IO 的优化思路是解决应用程序需要先后发送询问请求、接收数据请求两个阶段的模式,在异步 IO 的模式下,只需要向内核发送一次请求就可以完成状态询问和数拷贝的所有操作。