从FD到socketFD再到epoll原理
FD
fd 是什么?
fd 是 File descriptor 的缩写,中文名叫做:文件描述符。文件描述符是一个非负整数,本质上是一个进程相关的索引值
什么时候拿到的 fd ?
当打开一个文件时,内核向进程返回一个文件描述符( open 系统调用得到 ),后续 read、write 这个文件时,则只需要用这个文件描述符来标识该文件,将其作为参数传入 read、write 。
fd 的值范围是什么?
在 POSIX 语义中,0,1,2 这三个 fd 值已经被赋予特殊含义,分别是标准输入( STDIN_FILENO ),标准输出( STDOUT_FILENO ),标准错误( STDERR_FILENO )。
文件描述符是有一个范围的:0 ~ OPEN_MAX-1 ,最早期的 UNIX 系统中范围很小,现在的主流系统单就这个值来说,变化范围是几乎不受限制的,只受到系统硬件配置和系统管理员配置的约束。
你可以通过 ulimit 命令查看当前系统的配置:
1 | |
窥探 Linux 内核
用户使用系统调用 open 或者 creat 来打开或创建一个文件,用户态得到的结果值就是 fd;
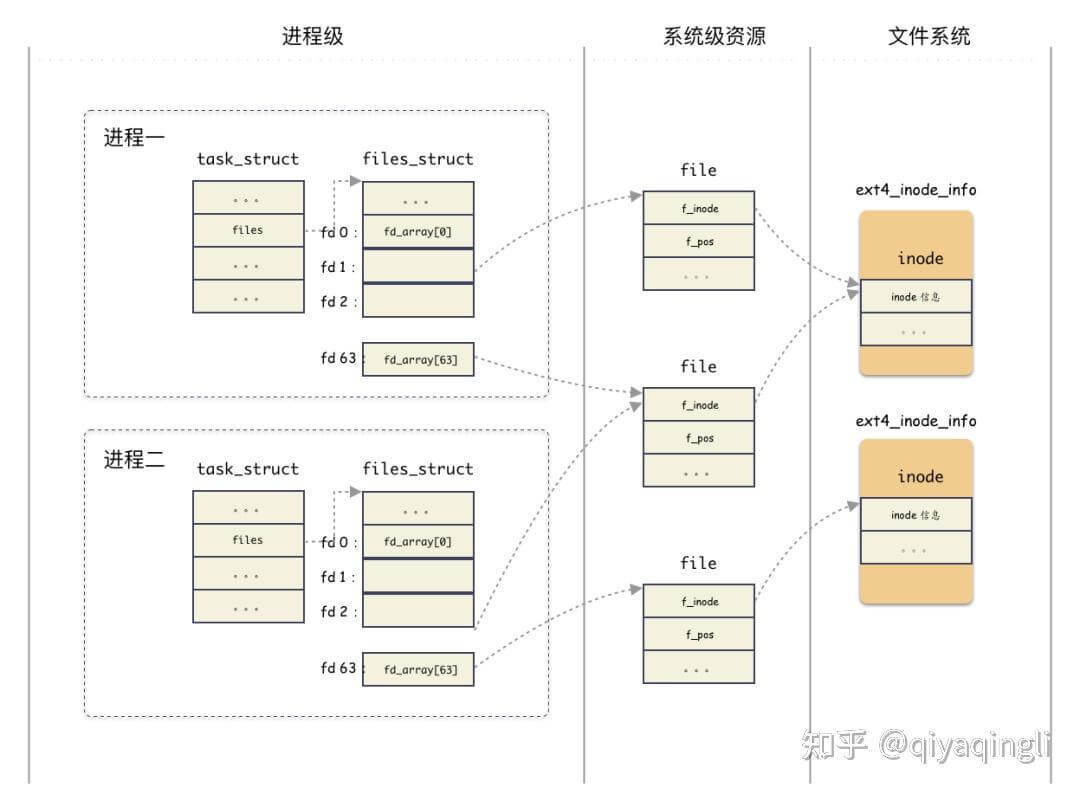
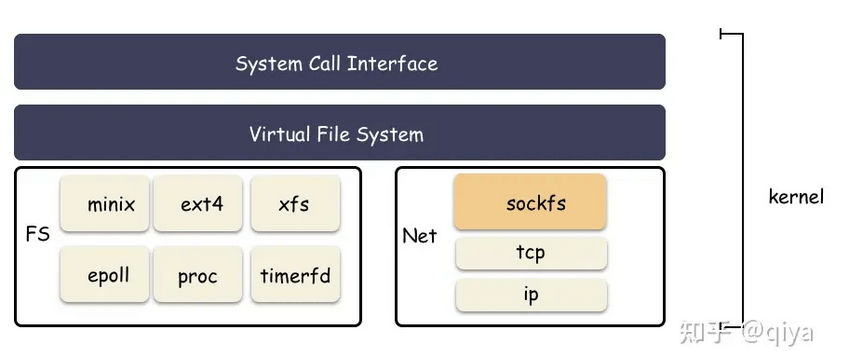
task_struct
首先,我们知道进程的抽象是基于 struct task_struct 结构体,当创建一个进程,其实也就是 new 一个 struct task_struct 出来,这是 Linux 里面最复杂的结构体之一 ,成员字段非常多,我们今天不需要详解这个结构体,我稍微简化一下,只提取我们今天需要理解的字段如下:
1 | |
files 这个字段就是今天的主角之一, 管理着该进程打开的所有文件
files_struct
1 | |
既然管理进程打开所有的文件,那当然需要一个数组,有两个地方存储了数组:
struct file * fd_array[NR_OPEN_DEFAULT]是一个静态数组,随着files_struct结构体分配出来的,在 64 位系统上,静态数组大小为 64;struct fdtable也是个数组管理结构,只不过这个是一个动态数组,数组边界是用字段描述的;思考:为什么会有这种静态 + 动态的方式?
性能和资源的权衡 !大部分进程只会打开少量的文件,所以静态数组就够了,这样就不用另外分配内存。如果超过了静态数组的阈值,那么就动态扩展。
为什么说fd就是一个索引:**fd 其实就是就是这个数组的索引,也就是数组的槽位编号而已。**
file
也就是fd指向的对象,表示当前进程打开的某个文件;关键信息:当前文件偏移,inode 结构地址;
1 | |
f_path:标识文件名f_inode:非常重要的一个字段,inode这个是 vfs 的inode类型,是基于具体文件系统之上的抽象封装;(文件系统共享)f_pos: 这个字段非常重要,偏移,对,就是当前文件偏移。还记得上一篇 IO 基础里也提过偏移对吧,指的就是这个,f_pos在open的时候会设置成默认值,seek的时候可以更改,从而影响到write/read的位置;f_op:根据你的“文件”类型赋值的(也就是指向了struct inode中的i_fop),比如 ext2 的文件,那么就是ext2_file_operationsfile是当前进程打开的某个文件,那会进程间共享吗? 一般不会,但会 fork时
在同一个进程中,多个
fd可能指向同一个 file 结构吗?dup命令
inode
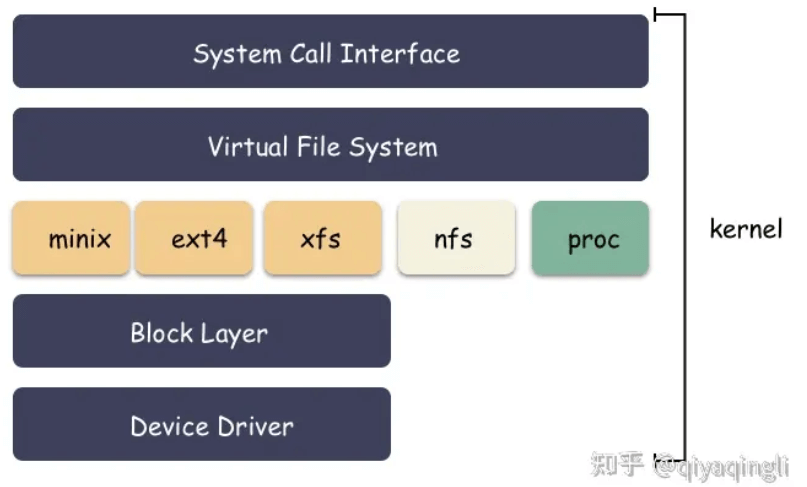
struct file 结构体里面有一个 inode 的指针,这个指向的 inode 并没有直接指向具体文件系统的 inode ,而是操作系统抽象出来的一层虚拟文件系统,叫做 VFS ( Virtual File System ),然后在 VFS 之下才是真正的文件系统,比如 ext4 之类的。
1 | |
i_fop 回调函数在构造 inode 的时候,就注册成了后端的文件系统函数,假设有一个名为 ext4_file_operations 的结构体,它包含了针对 ext4 文件系统的操作函数的指针。那么,i_fop 指针可以被设置为指向这个结构体,从而允许操作 ext4 文件系统中的文件。
1 | |
vfs inode 是下一层的抽象(如ext4_inode_info), 所有文件系统共性的东西抽象到 vfs inode ,不同文件系统差异的东西放在各自的 inode 结构体中。c语言中的继承是通过结构体的组合实现的:
1 | |
分配 inode 的时候,其实分配的是 ext4_inode_info 结构体,包含了 vfs inode,然后对外给出去 vfs_inode 字段的地址即可。VFS 层拿 inode 的地址使用,底下文件系统强转类型后(struct ext4_inode_info *)(vfs_inode地址 - vfs_inode在ext4_inode_info中的偏移),取外层的 ext4_inode_info 地址使用。
小节
- 用户操作文件时,open会得到一个FD
- FD本质来讲是一个数组索引,结构体
task_struct对应一个抽象的进程,files_struct是这个进程管理该进程打开的文件数组管理器。也就是fd是进程中的task_struct.files_struct.fd_array的下标,指向file结构体 file结构:表征一个打开的文件,内部包含关键的字段有:当前文件偏移,inode 结构地址;该结构虽然由进程触发创建,但是file结构可以在进程间共享;(fork)inode属于文件系统级别的概念,只由文件系统管理维护,进程间共享 (当多个进程写同一个文件的时候,由于一个文件最终是落到全局唯一的一个inode上,这种并发场景则可能产生用户不可预期的结果;)
socket FD
socket 可能你还没反应过来,中文名:套接字
socket是为了方便网络编程设计出的接口,视为应用程序与传输层之间的桥梁,它为应用程序提供了一个通用的、与底层传输协议无关的接口,使得不同应用程序可以方便地进行网络通信。实现可以是基于TCP、UDP的,使我们不用考虑tcp udp 以及内核网络的传输功能
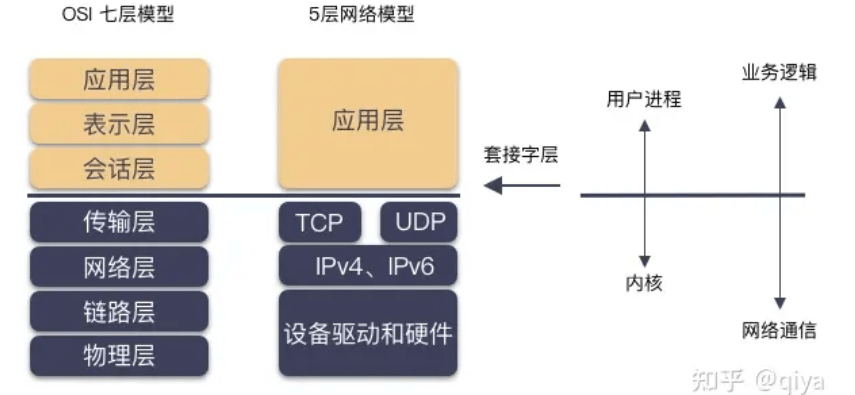
- 客户端和服务端都用
socket调用创建套接字; - 服务端用
bind绑定监听地址,用listen把套接字转化为监听套接字,用accept捞取一个客户端来的连接; - 客户端用
connect进行建连,用write/read进行网络 IO;(这里connect就像open一个本地文件一样,这就是socket给我们带来的方便)
我们可以基于socket 构建我们想要的应用层协议 例如http resp, 写一个resp读取redis
1 | |
socket fd 的类型
上面我们提到了套接字,这是我们网络编程的主体,套接字由 socket() 系统调用创建,但你可知套接字其实可分为两种类型,监听套接字和普通套接字。而监听套接字是由 listen() 把 socket fd 转化而成。
监听套接字
对于监听套接字,不走数据流,只管理连接的建立。accept 将从全连接队列获取一个创建好的 socket( 3 次握手完成),对于监听套接字的可读事件就是全连接队列非空。
对于监听套接字,我们只在乎可读事件。
普通套接字
普通套接字就是走数据流的,也就是网络 IO,针对普通套接字我们关注可读可写事件。在说 socket 的可读可写事件之前,我们先捋顺套接字的读写大概是什么样子吧。
套接字层是内核提供给程序员用来网络编程的,程序猿读写都是针对套接字而言,那么 write( socketfd, /* 参数 */) 和 read( socketfd, /* 参数 */) 都会发生什么呢?
- write 数据到 socketfd,大部分情况下,数据写到 socket 的内存 buffer,就结束了,并没有发送到对端网络(异步发送);
- read socketfd 的数据,也只是从 socket 的 内存 buffer 里读数据而已,而不是从网卡读(虽然数据是从网卡一层层递上来的);
也就是说,程序猿而言,是跟 socket 打交道,内核屏蔽了底层的细节。
那说回来 socket 的可读可写事件就很容易理解了。
- socketfd 可读:其实就是 socket buffer 内有数据(超过阈值 SO_RCLOWAT );
- socketfd 可写:就是 socket buffer 还有空间让你写(阈值 SO_SNDLOWAT );
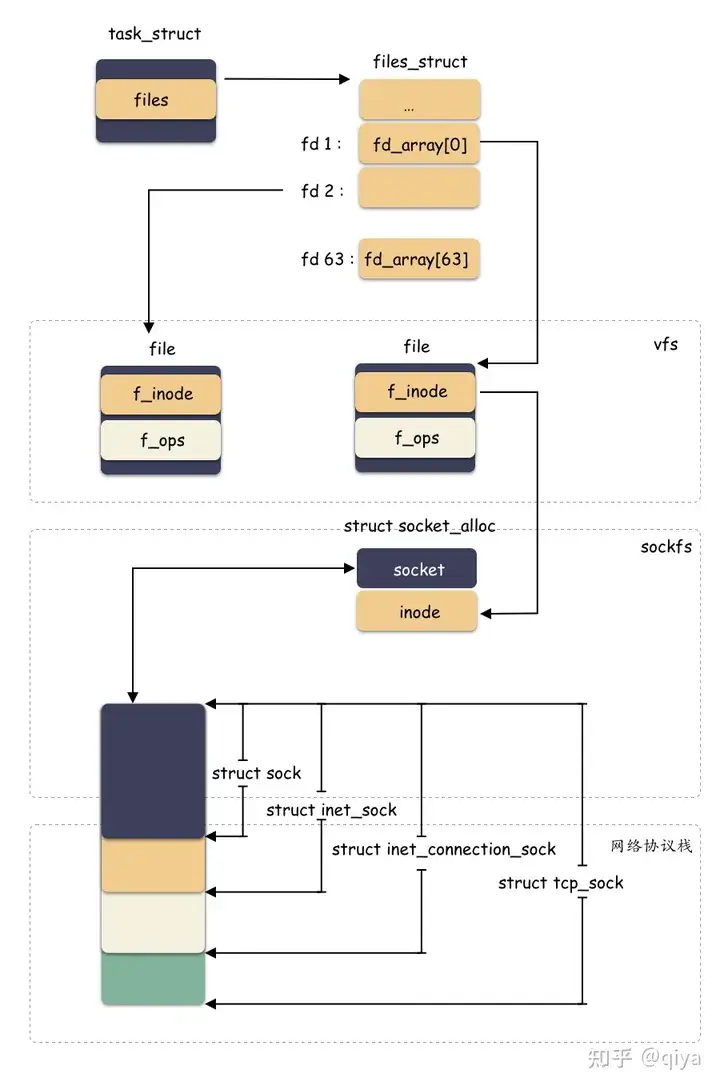
sockfs 文件系统
之前在fd中提到,vfs 层使用的是 inode,ext4 层使用的是 ext4_inode_info ,不同层次通过地址的强制转化类型来切换结构体。
那么类似,sockfs 也是如此,sockfs 作为文件系统,也有自己特色的 “inode”,这个类型就是 struct socket_alloc ,如下:
1 | |
这个结构体关联 socket 和 inode 两个角色,是“文件”抽象的核心之一。分配 struct socket 结构体其实是分配了 struct socket_alloc 结构体,然后返回了 socket_alloc->socket 字段的地址而已。但还是可以通过地址的偏移拿到整个socket_alloc
struct socket是内核抽象出的一个通用结构体,主要作用是放置了一些跟 fs 相关的字段,而真正跟网络通信相关的字段结构体是struct sock。它们内部有相互的指针,可以获取到对方的地址。
2
3
4
5
6
7struct socket {
int type; // 套接字类型 (SOCK_STREAM, SOCK_DGRAM, etc.)
int state; // 套接字状态 (ESTABLISHED, LISTEN, etc.)
struct sock *sk; // 指向关联的底层套接字对象的指针
struct file *file; // 与套接字关联的文件
// 其他成员...
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28struct sock {
struct socket *sk_socket; // 指向上层 socket 结构体的指针
/* 套接字状态 */
unsigned short sk_family; // 地址族 (AF_INET, AF_INET6, etc.)
unsigned char sk_state; // 套接字状态 (TCP: ESTABLISHED, LISTEN, etc.)
/* 通用信息 */
struct proto *sk_prot; // 指向协议特定信息的指针 tcp_prot udp_prot
struct sock *sk_peer; // 对等套接字 (用于连接套接字)
/* 地址信息 */
struct sockaddr_storage sk_rcvaddr; // 接收地址信息
struct sockaddr_storage sk_daddr; // 目的地址信息
/* 数据缓冲区 */
struct sk_buff_head sk_receive_queue; // 接收队列 指向sk_buff
struct sk_buff_head sk_write_queue; // 发送队列
/* 套接字选项 */
int sk_rcvbuf; // 接收缓冲区大小
int sk_sndbuf; // 发送缓冲区大小
struct socket_wq __rcu *sk_wq; // 新版本通过sk_sleep() 间接访问
/* 其他成员 */
// ...
};
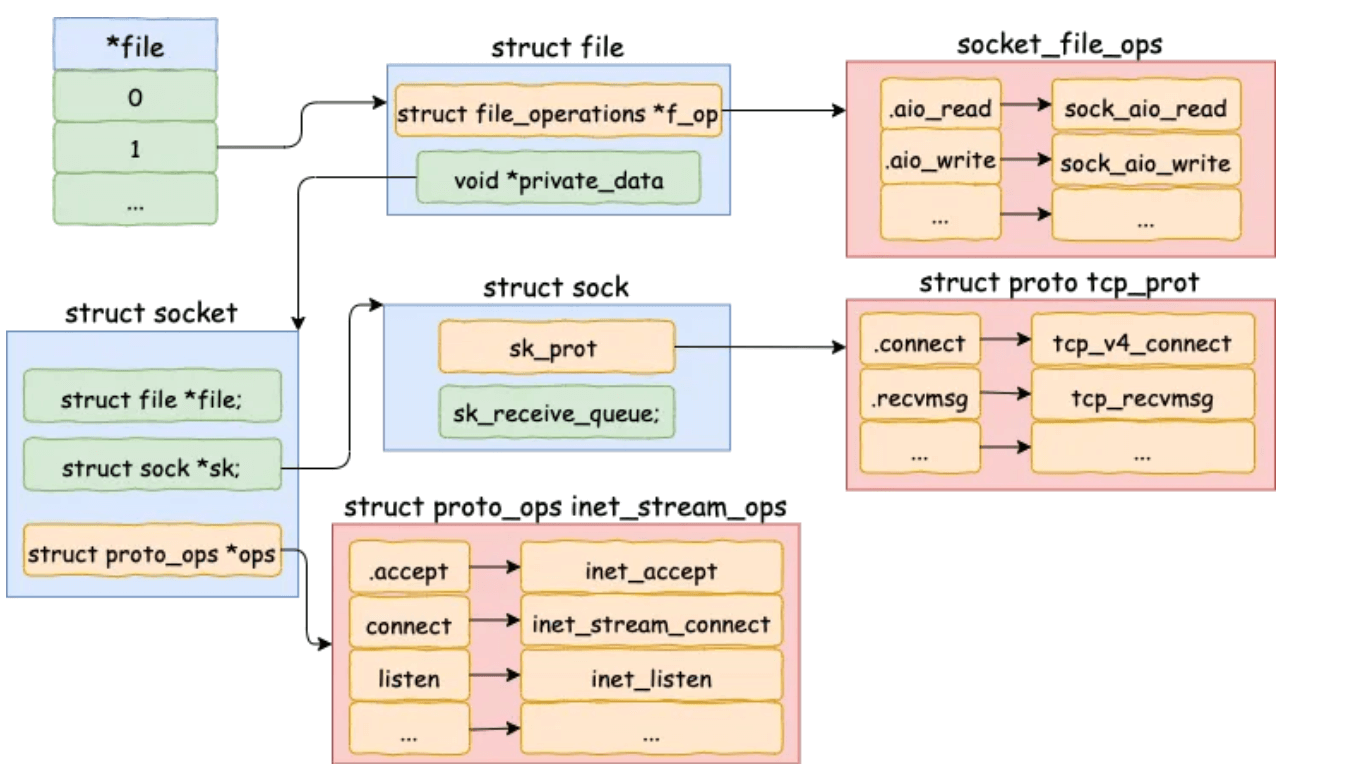
vfs 层用的时候给 inode 字段的地址,socket 层的时候给 socket 字段的地址。不同抽象层面对于同一个内存块的理解不同,强制转化类型,然后各自使用
socket创建
socket 系统调用对应了 __sys_socket 这个函数。这个函数主要做两件事情:
- 第一件事:调用
socket_create函数创建好 socket 相关的结构体,主要是struct socket,还有与之关联的socket sock结构,再往下就是具体网络协议对应的结构体(旁白:这里实现细节过于复杂,不在文章主干,故略去 10 万字); - 第二件事:调用
sock_map_fd函数创建好struct file这个结构体,并与第一步创建出的struct socket关联起来;
1 | |
socket( )函数只负责创建出适配具体网络协议的资源(内存、结构体、队列等),并没有和具体地址绑定;socket( )返回的是非负整数的 fd,与struct file对应,而struct file则与具体的struct socket关联,从而实现一切皆文件的封装的一部分(另一部分 inode 的创建处理在 sock_alloc 的函数里体现);
IO
阻塞IO
阻塞IO中用户进程阻塞以及唤醒原理
用户进程发起系统IO调用时,这里我们拿read举例,用户进程会在内核态查看对应Socket接收缓冲区是否有数据到来。
Socket接收缓冲区有数据,则拷贝数据到用户空间,系统调用返回。Socket接收缓冲区没有数据,则用户进程让出CPU进入阻塞状态,当数据到达接收缓冲区时,用户进程会被唤醒,从阻塞状态进入就绪状态,等待CPU调度。
本小节我们就来看下用户进程是如何阻塞在Socket上,又是如何在Socket上被唤醒的。理解这个过程很重要,对我们理解epoll的事件通知过程很有帮助
- 首先我们在用户进程中对
Socket进行read系统调用时,用户进程会从用户态转为内核态。 - 在进程的
struct task_struct结构找到fd_array,并根据Socket的文件描述符fd找到对应的struct file,调用struct file中的文件操作函数结合file_operations,read系统调用对应的是sock_read_iter。 - 在
sock_read_iter函数中找到struct file指向的struct socket,并调用socket->ops->recvmsg,这里我们知道调用的是inet_stream_ops集合中定义的inet_recvmsg。在inet_recvmsg中会找到struct sock,并调用sock->skprot->recvmsg,这里调用的是tcp_prot集合中定义的tcp_recvmsg函数。
进入等待
当调用fd.read并且没有足够数据时, 创建一个wait_queue_t 对象(包含当前线程,回调函数)挂接到这个 socket 的 sk->sk_wq 中
1 | |
等待类型wait_queue_t中的private用来关联阻塞在当前socket上的用户进程fd。func用来关联等待项上注册的回调函数。这里注册的是autoremove_wake_function。
唤醒
当网络数据包到达网卡时,网卡通过
DMA的方式将数据放到RingBuffer中。然后向CPU发起硬中断,在硬中断响应程序中创建
sk_buffer,并将网络数据拷贝至sk_buffer中。随后发起软中断,内核线程
ksoftirqd响应软中断,调用poll函数将sk_buffer送往内核协议栈做层层协议处理。在传输层
tcp_rcv 函数中,去掉TCP头,根据四元组(源IP,源端口,目的IP,目的端口)查找对应的Socket。最后将
sk_buffer放到Socket中的接收队列sk_receive_queue里。接着就会调用
数据就绪函数回调指针sk_data_ready,前边我们提到,这个函数指针在初始化的时候指向了sock_def_readable函数。- 获取
socket->sock->sk_wq等待队列。在wake_up_common函数中从等待队列sk_wq中找出一个等待项wait_queue_t,回调注册在该等待项上的func回调函数(wait_queue_t->func),创建等待项wait_queue_t是我们提到,这里注册的回调函数是autoremove_wake_function(等待项wait_queue_t上的private关联的阻塞进程fd调用try_to_wake_up唤醒阻塞在该Socket上的进程)。
- 获取
epoll
创建epoll对象
epoll_create是内核提供给我们创建epoll对象的一个系统调用,当我们在用户进程中调用epoll_create时,内核会为我们创建一个struct eventpoll对象,并且也有相应的struct file与之关联,同样需要把这个struct eventpoll对象所关联的struct file放入进程打开的文件列表fd_array中管理。
熟悉了
Socket的创建逻辑,epoll的创建逻辑也就不难理解了。
struct eventpoll对象关联的struct file中的file_operations 指针指向的是eventpoll_fops操作函数集合。
1 | |
1 | |
wait_queue_head_t wq:epoll中的等待队列,队列里存放的是阻塞在epoll上的用户进程。在IO就绪的时候epoll可以通过这个队列找到这些阻塞的进程并唤醒它们,从而执行IO调用读写Socket上的数据。
这里注意与
Socket中的等待队列区分!!!
struct list_head rdllist:epoll中的就绪队列,队列里存放的是都是IO就绪的Socket,被唤醒的用户进程可以直接读取这个队列获取IO活跃的Socket。无需再次遍历整个Socket集合。
这里正是
epoll比select ,poll高效之处,select ,poll返回的是全部的socket连接,我们需要在用户空间再次遍历找出真正IO活跃的Socket连接。 而epoll只是返回IO活跃的Socket连接。用户进程可以直接进行IO操作。
struct rb_root rbr :由于红黑树在查找,插入,删除等综合性能方面是最优的,所以epoll内部使用一颗红黑树来管理海量的Socket连接。
select用数组管理连接,poll用链表管理连接。
添加socket
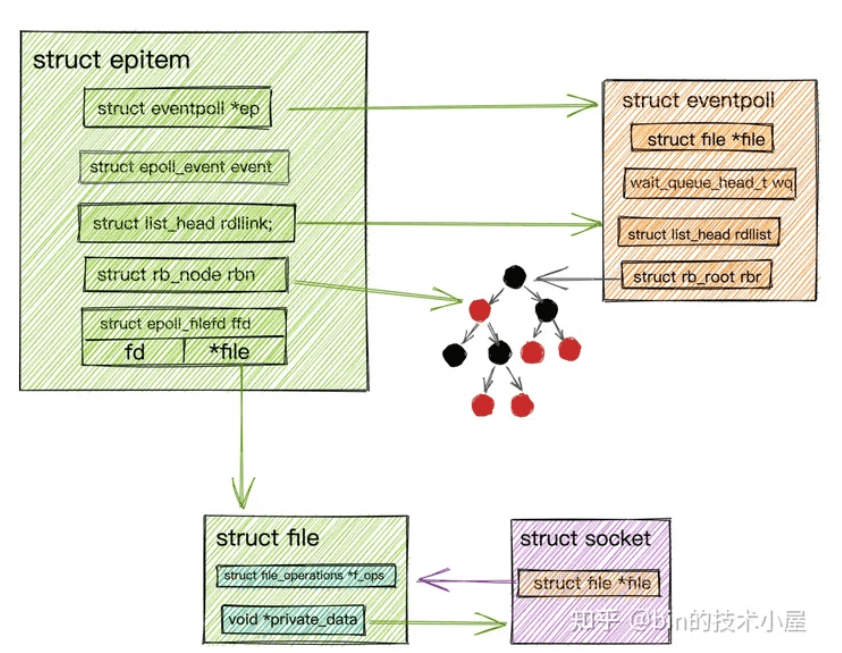
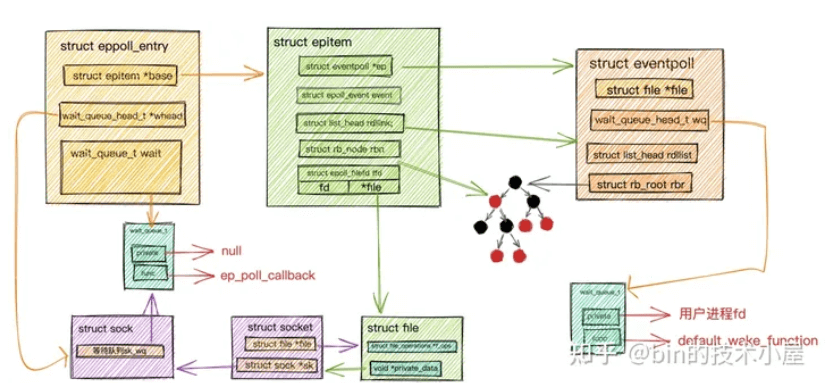
首先要在epoll内核中创建一个表示Socket连接的数据结构struct epitem,而在epoll中为了综合性能的考虑,采用一颗红黑树来管理这些海量socket连接。所以struct epitem是一个红黑树节点。
1 | |
在内核中创建完表示Socket连接的数据结构struct epitem后,我们就需要在Socket中的等待队列上创建等待项wait_queue_t并且注册epoll的回调函数ep_poll_callback。
通过
《阻塞IO中用户进程阻塞以及唤醒原理》小节的铺垫,我想大家已经猜到这一步的意义所在了吧!当时在等待项wait_queue_t中注册的是autoremove_wake_function回调函数。而在这里注册的就是epoll的回调函数ep_poll_callback
- 之前如果当前socket就绪了,会根据wq中
autoremove_wake_function激活private 也就是被阻塞的线程- 现在是
ep_poll_callback:找到当前当前socket的epitem,放入epoll中的就绪队列中。
如何找到epitem呢?wait_queue_t只有一个回调函数和一个null指针
为什么private为null
因为这里
Socket是交给epoll来管理的,阻塞在Socket上的进程是也由epoll来唤醒。在等待项wait_queue_t注册的func是ep_poll_callback而不是autoremove_wake_function,阻塞进程并不需要autoremove_wake_function来唤醒,所以这里设置private为null
如何找到epitem呢?
2
3
4
5
6
7
8
9
10
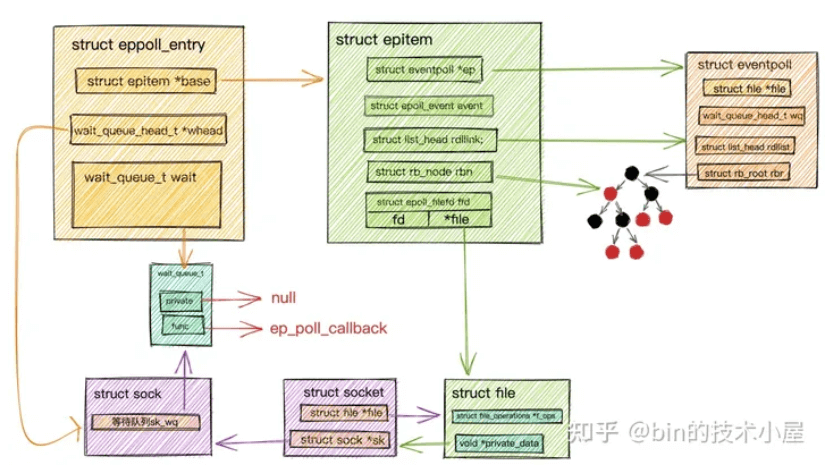
11struct eppoll_entry {
//指向关联的epitem
struct epitem *base;
// 关联监听socket中等待队列中的等待项 (private = null func = ep_poll_callback)
wait_queue_t wait;
// 监听socket中等待队列头指针
wait_queue_head_t *whead;
.........
};引入一个eppoll_entry包裹住wait_queue_t,通过
container_of宏找到eppoll_entry,继而找到epitem了。(
container_of在Linux内核中是一个常用的宏,用于从包含在某个结构中的指针获得结构本身的指针,通俗地讲就是通过结构体变量中某个成员的首地址-偏移量进而获得整个结构体变量的首地址。)
epoll_wait
用户程序调用epoll_wait后,内核首先会查找epoll中的就绪队列eventpoll->rdllist是否有IO就绪的epitem。epitem里封装了socket的信息。如果就绪队列中有就绪的epitem,就将就绪的socket信息封装到epoll_event返回。
如果eventpoll->rdllist就绪队列中没有IO就绪的epitem,则会创建等待项wait_queue_t,将用户进程的fd关联到wait_queue_t->private上,并在等待项wait_queue_t->func上注册回调函数default_wake_function。最后将等待项添加到epoll中的等待队列中。用户进程让出CPU,进入阻塞状态。
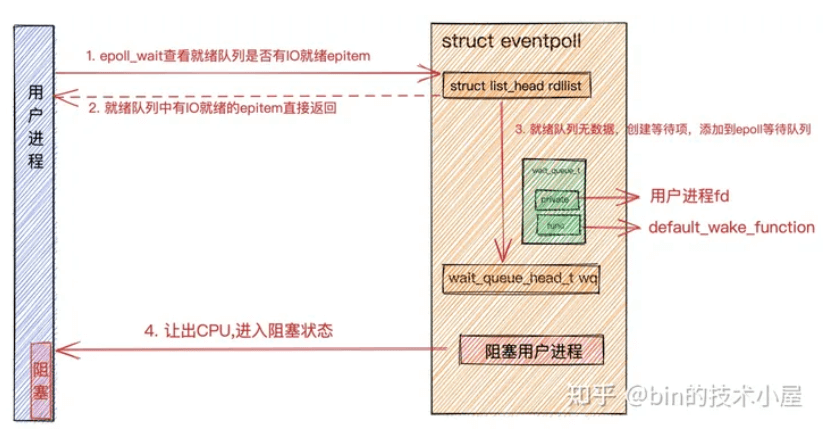
这里和
阻塞IO模型中的阻塞原理是一样的,只不过在阻塞IO模型中注册到等待项wait_queue_t->func上的是autoremove_wake_function,并将等待项添加到socket中的等待队列中。这里注册的是default_wake_function,将等待项添加到epoll中的等待队列上。
至此,整个epoll变成了:
当网络数据包在软中断中经过内核协议栈的处理到达socket的接收缓冲区时,紧接着会调用socket的数据就绪回调指针sk_data_ready,回调函数为sock_def_readable。在socket的等待队列中找出等待项,其中等待项中注册的回调函数为ep_poll_callback。
在回调函数ep_poll_callback中,根据struct eppoll_entry中的struct wait_queue_t wait通过container_of宏找到eppoll_entry对象并通过它的base指针找到封装socket的数据结构struct epitem,并将它加入到epoll中的就绪队列rdllist中。
随后查看epoll中的等待队列中是否有等待项,也就是说查看是否有进程阻塞在epoll_wait上等待IO就绪的socket。如果没有等待项,则软中断处理完成
小结
sk_wq是sock结构中的一个重要部分,表示的是socket等待队列。代表着有哪些对象(线程读、epoll_ctl)关注着当前的socket,当前socket可读或可写时,就要通知wq上的对象,通知的方法挂载时设置的回调函数sk_wq主要用于以下几种情形:- 发送操作时的阻塞管理:当发送缓冲区不够用时,试图发送数据的进程将会被放入等待队列
- 接收操作时的阻塞管理:当接收缓冲区没有数据时,试图读取数据的进程将会被放入等待队列
- 异步IO和事件通知:
sk_wq也与异步IO操作和某些类型的事件通知机制(如epoll)相关,使得应用程序能够有效地等待多个IO事件。
在阻塞io中,如果数据没有就绪,创建
wait_queue_t{当前线程、唤醒的回调}加入到socket->sock->sk_wq,在就绪时会调用回调唤醒该线程在epoll中,创建了一个epoll同时对象管理多个socket,epoll对象也是文件,也包含
wq,记录着所有epoll_wait等待的线程以及default_wake_function;epoll对象使用红黑树管理全部socket,
rdllist为就序列表,当添加一个socket时- 添加到红黑树中
epitem节点 - 在
Socket中的等待队列上创建等待项wait_queue_t并且注册epoll的回调函数ep_poll_callback, 这里之前代表着被阻塞的进程,就绪时需要去唤醒;现在代表着你就绪了来通知我epoll就行(把epitem加入到rdllist,同时检查epoll的wq,有就回调唤醒)
- 添加到红黑树中