对账体系建设
原文链接:https://tech.meituan.com/2018/03/21/balance-accounts.html
引入
业务复杂性高:场景多、链路长、数据量大,给资金安全带来了巨大挑战
可能出现问题的场景:
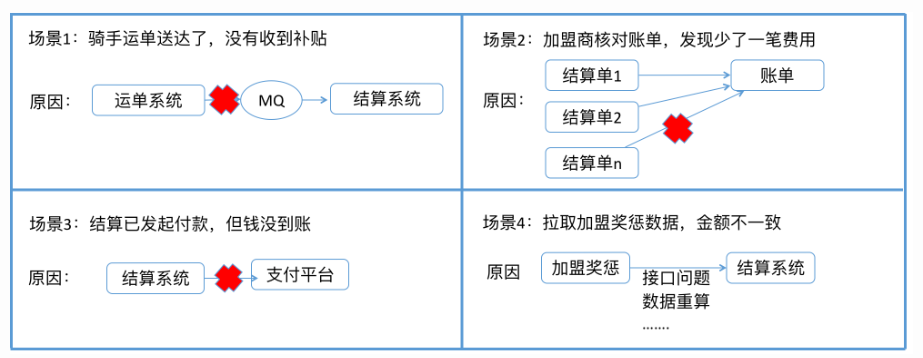
可以看出,这些都是一些上下游交互的边界场景,以及遇到的问题。当然不仅限于这些场景,凡是有系统交互、数据交互边界的场景,都会出现此类问题,我们称之为“一致性问题”。经粗略统计,我们清结算系统建立以来有70%左右的问题都属于一致性问题。
解决一致性问题的方法:目标都是在事中避免问题的发生。
- 强一致性协议: 两阶段提交、三阶段提交、TCC (Try-Confirm-Cancel)等
- 最终一致性: 主动轮询、异步确保、可靠消息、消息事务等
但是在实际场景中,导致一致性问题的原因有很多,无论是系统的内部逻辑还是外部环境都十分复杂多变、不可预知,我们很难完全避免问题:
- 幂等、并发控制不当。
- 基础环境故障:比如网络、数据库、消息中间将发生故障。
- 其他代码bug。
因此事后对于问题数据的发现以及修复就显得尤为重要。这就是对账系统
设计思路
- 数据准备
- 数据核对(轧账)
- 差错处理(平账)
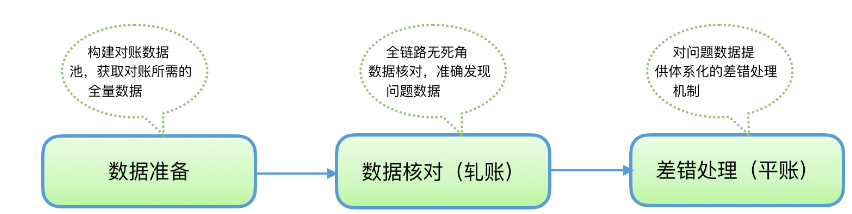
数据准备
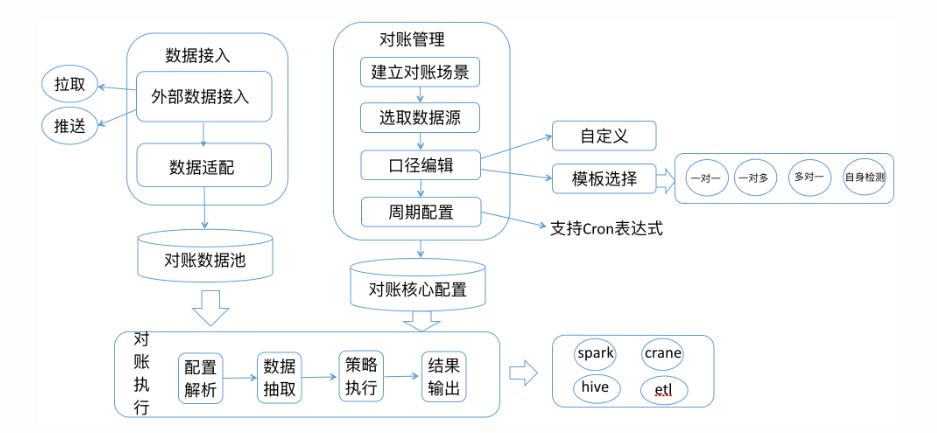
将对账所需的全部数据,接入到我们的对账系统
- 数据拉取:我们主动拉取数据,并通过数据适配的方式,将数据存储到对账数据池中。
- 数据推送:由数据接入方将数据通过ETL(Extract-Transform-Load)等方式直接推送到我们的对账数据池中,数据格式由数据接入方自行适配。
- 文件上传:我们会提供标准的文件模板,由数据接入方填充数据,通过文件上传的方式将数据接入到我们的数据池。
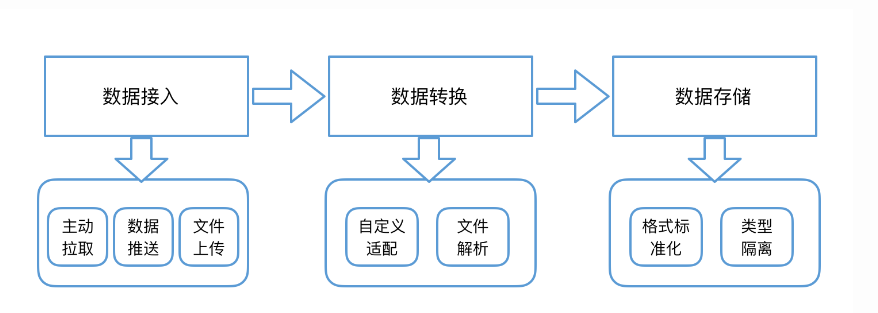
此外,也可用使用同一个数据源
数据核对(轧账)
核心!其目标是发现问题数据。数据核对阶段我们的两个目标是保障数据核对的**覆盖度*和准确性***。经过总结和梳理,数据核对过程可以分为以下5个环节。

1. 问题梳理
由于数据核对的目标是发现问题,那么我们进行数据核对就要从问题出发,首先明确我们要通过对账发现哪些问题,只有这样才能保证数据核对的覆盖度。经过梳理,我们发现在数据流转中过程中数据的不一致问题可以统一归结为三类,分别是*漏结*、*重复结**、错结***。
- 漏结:发起方有数据,而接收方没有数据。举个例子,目前清结算系统会在订单送达时给骑手结算。如果订单的状态是送达,而没有给骑手生成对应的结算数据。就是一种典型的漏结算场景。
- 重复结:接收方重复处理。还是上面的例子,如果订单送达,给骑手结算了两次,产生了重复的结算数据,就是重复结算。
- 错结:发起方和接受方数据不一致。一般会发生在金额和状态两个字段。比如说订单上的数据是用户加小费3元。结算这边只产生了2元的小费结算数据,就是错结。
2. 对账方式
对账方式主要分为两种,**单向对账*和双向对账***。
- 单向对账:以一方数据为基准进行对账。比如结算跟支付平台,以结算数据为基准和支付平台核对,用来发现结算数据为支付成功,支付平台支付失败等问题。
- 双向对账:以双方的数据互为基准对账。既要保证结算数据为成功的,支付平台也要成功,又要保证支付平台数据为成功的,结算数据也要成功。
显而易见,双向对账更能够全面的发现问题。因此在条件允许的情况下,我们会优先选择双向对账。
3. 对账粒度
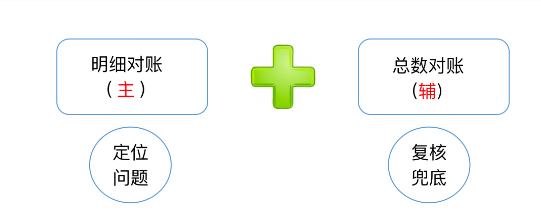
对账粒度也分为两种,分别是**明细对账*和总数对账***。
- 明细对账:对双方的每条数据依次进行比对。
- 优点是可以准确定位问题数据。
- 缺点是对账口径的设计比较复杂。因为我们需要同时针对漏、重、错三种错误类别设计不同的对账口径,同时还要考虑到业务的边缘场景。稍有不慎,就会影响对账的准确性。
- 总数对账:选择一个维度,进行总数级别的对账。优缺点和上面相反
4. 对账口径
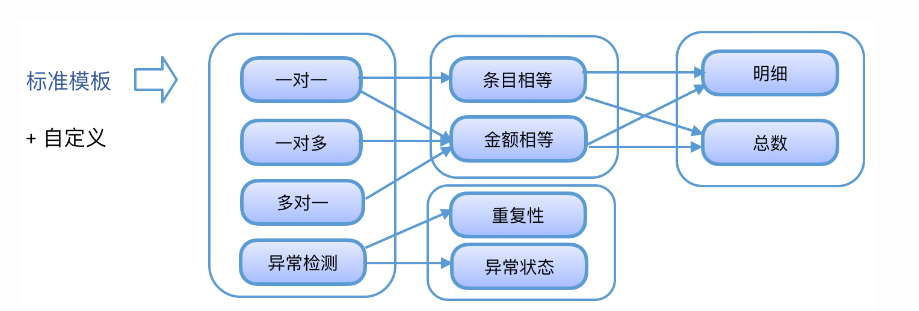
对账口径,也就是具体的对账逻辑的设计。我们会提供固定的**对账模板*,供不同的对账场景选取。如果某些特殊场景对账模板不能覆盖,也可以采取对账逻辑自定义***的方式进行对账。
经过总结我们发现,对账的形式无非就是两方比对和自身异常检测两种。两方比对又可以细分为一对一、多对一、一对多。比对方法也主要是分为条目匹配和金额匹配。自身异常检测主要是重复性和异常状态的检测。我们把这些通用的对账逻辑模板化,减少重复的开发工作。
5. 对账时机
分为离线对账*和在线对账*
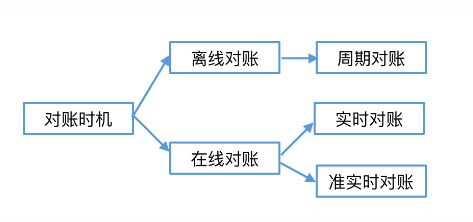
离线对账主要是通过固定的周期进行对账。最短周期为T+1。它的好处是适用性较强,基本可以覆盖所有的对账场景。
在线对账又分为**实时对账*和准实时对账***。
实时对账和准实时对账的区别主要是实时对账耦合在结算链路中,可以在发现问题数据时,对结算流程进行拦截
准实时对账是异步进行的,不具备拦截能力。在线对账有一定的局限性,一方面它依赖于对账数据是否能实时的准备好,另一方面也比较占用系统资源。
我们的做法应该是以周期对账为主,在某些实时性要求比较高,且条件满足的场景使用在线对账。
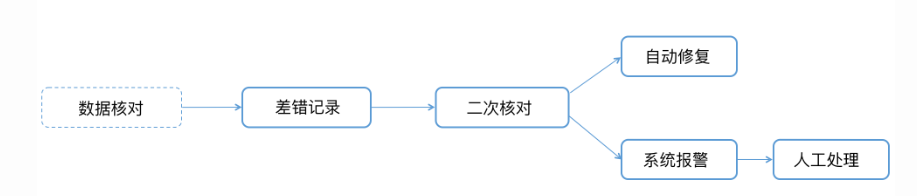
差错处理(平账)
对问题数据的处理
设计实现
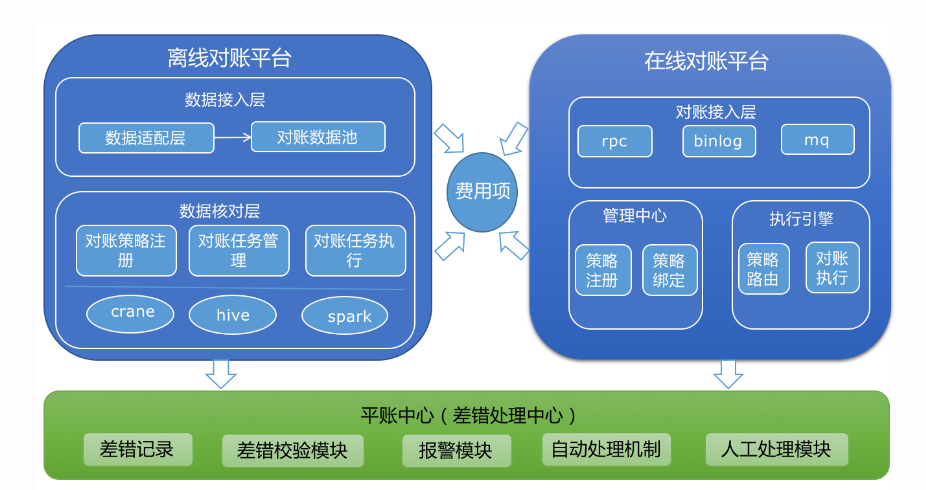
离线对账
在线对账
通过RPC、监听消息队列(MQ)、监听数据库binlog三种方式进行对账接入。在线对账平台分为管理层和执行层。管理层主要是承担策略编辑、策略绑定和拦截管理的相关工作。而执行层分为异步(准实时)对账和同步(实时)对账两个模块。
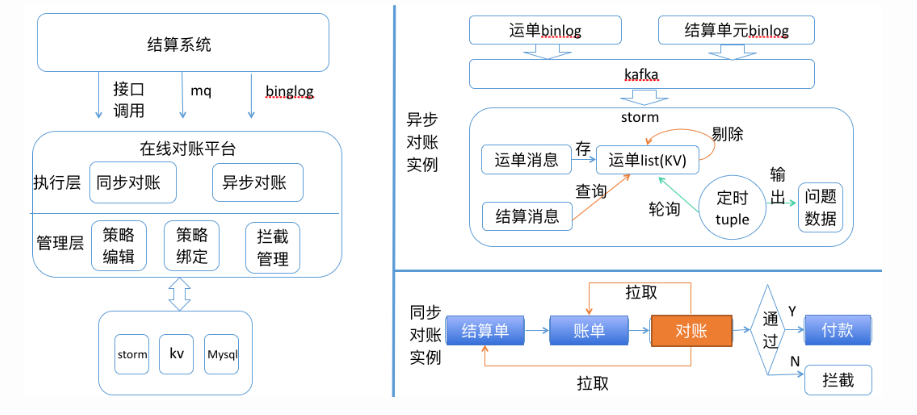
①异步对账:我们分别监听运单和结算单元的Binlog,通过Kafka->Storm的经典架构,进行对账策略的执行。实际的流程比较复杂,这里只是一张简图,大概就是:(细节可以忽略)
结算单元是 清结算系统内部的模型,和运单是一对一关系,记录运单各个节点的结算状态。收到运单消息后,我们会把对于的运单以List的形式存储到Squirrel(Redis)中,当结算消息来了以后,就把对应运单记录Delete掉。如果有运单记录一直停留在List当中,也就是说明结算消息没有来,应该是发生了漏结算。我们通过过定时任务轮询运单List将问题数据输出。
补充:这里在实习时接触到的是监听奖励表binlog,然后MQ发起一个对账请求,核对发奖信息和数据库配置信息是否一致
②同步对账:示例中是结算内部的流程,经历结算单、账单、付款几个流程。因为付款是最后一个流程,如果这个时候数据存在问题,那么就会造成实际的资金损失。因此我们会在付款环节之前,对前面的数据进行对账。如果发现账单和结算单的数据不一致,我们就会进行数据拦截。