TCP数据粘包
引入
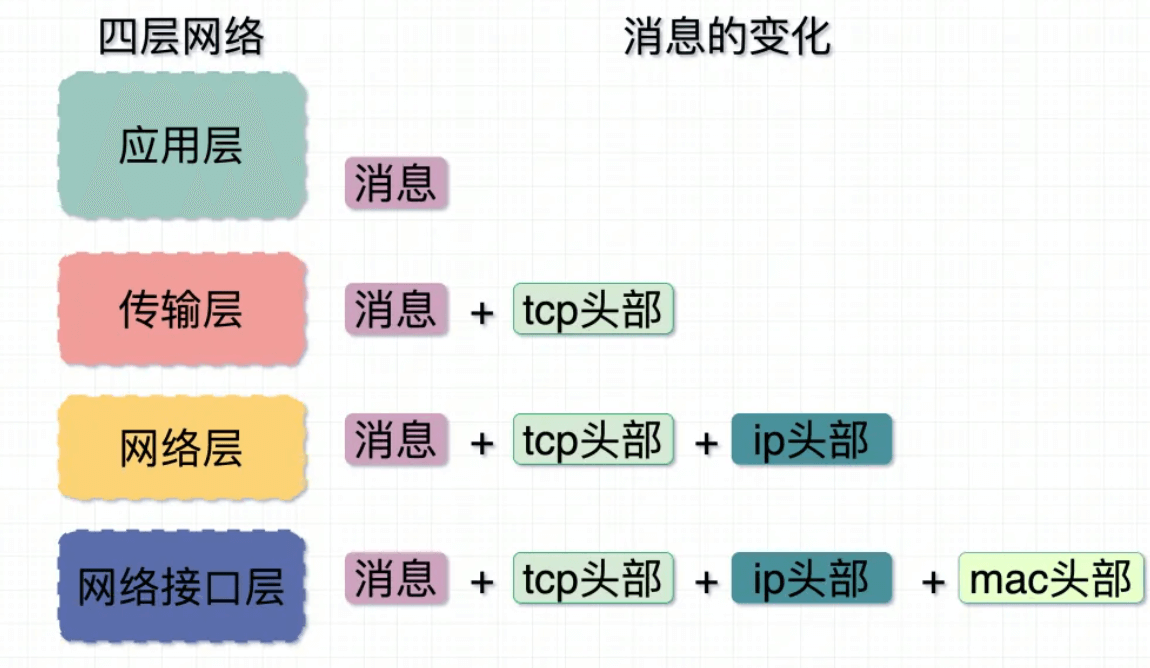
网络层通常四层协议,数据以一个个包在网络中传输,从上到下每经过一层,数据包头部就多出一些信息;
- TCP头:序列号和确认号、源端口和目的端口
- IP头:源IP和目的IP、长度、偏移
- mac头:源mac和目的mac
拆分
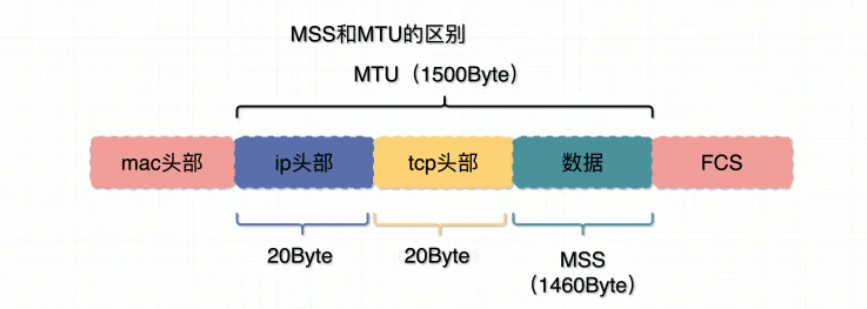
数据链路层提供给IP层每次传输的包大小有限制MTU,如果超过这个大小TCP 中把消息分成 MSS
- MTU: Maximum Transmit Unit,最大传输单元。 由网络接口层(数据链路层)提供给网络层最大一次传输数据的大小;一般 MTU=1500 Byte。
假设IP层有 <= 1500 byte 需要发送,只需要一个 IP 包就可以完成发送任务;假设 IP 层有> 1500 byte 数据需要发送,需要分片才能完成发送,分片后的 IP Header ID 相同。 - MSS:Maximum Segment Size 。TCP 提交给 IP 层最大分段大小,不包含 TCP Header 和 TCP Option,只包含 TCP Payload ,MSS 是 TCP 用来限制应用层最大的发送字节数。
假设 MTU= 1500 byte,那么 MSS = 1500- 20(IP Header) -20 (TCP Header) = 1460 byte,如果应用层有 2000 byte 发送,那么需要两个切片才可以完成发送,第一个 TCP 切片 = 1460,第二个 TCP 切片 = 540。
Nagle 合并
上面的情况是拆分包,还有存在相反的情况
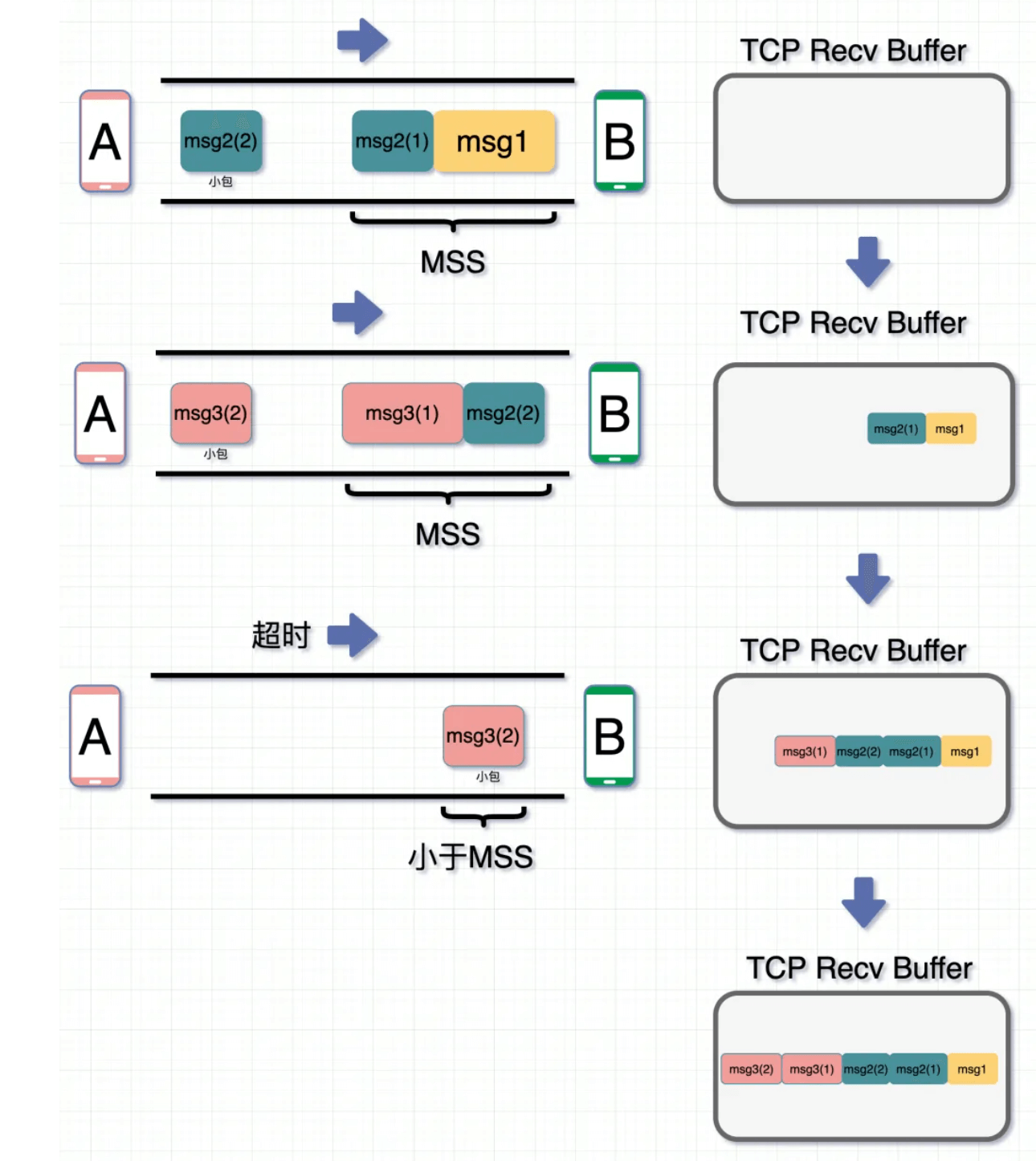
如果每次要传输的报文长度远小于MSS,每次单独发送小包比较浪费网络IO
TCP的 Nagle 算法优化,目的是为了避免发送小的数据包。
在 Nagle 算法开启的状态下,数据包在以下两个情况会被发送:
- 如果包长度达到
MSS(或含有Fin包),立刻发送,否则等待下一个包到来;如果下一包到来后两个包的总长度超过MSS的话,就会进行拆分发送; - 等待超时(一般为
200ms),第一个包没到MSS长度,但是又迟迟等不到第二个包的到来,则立即发送。
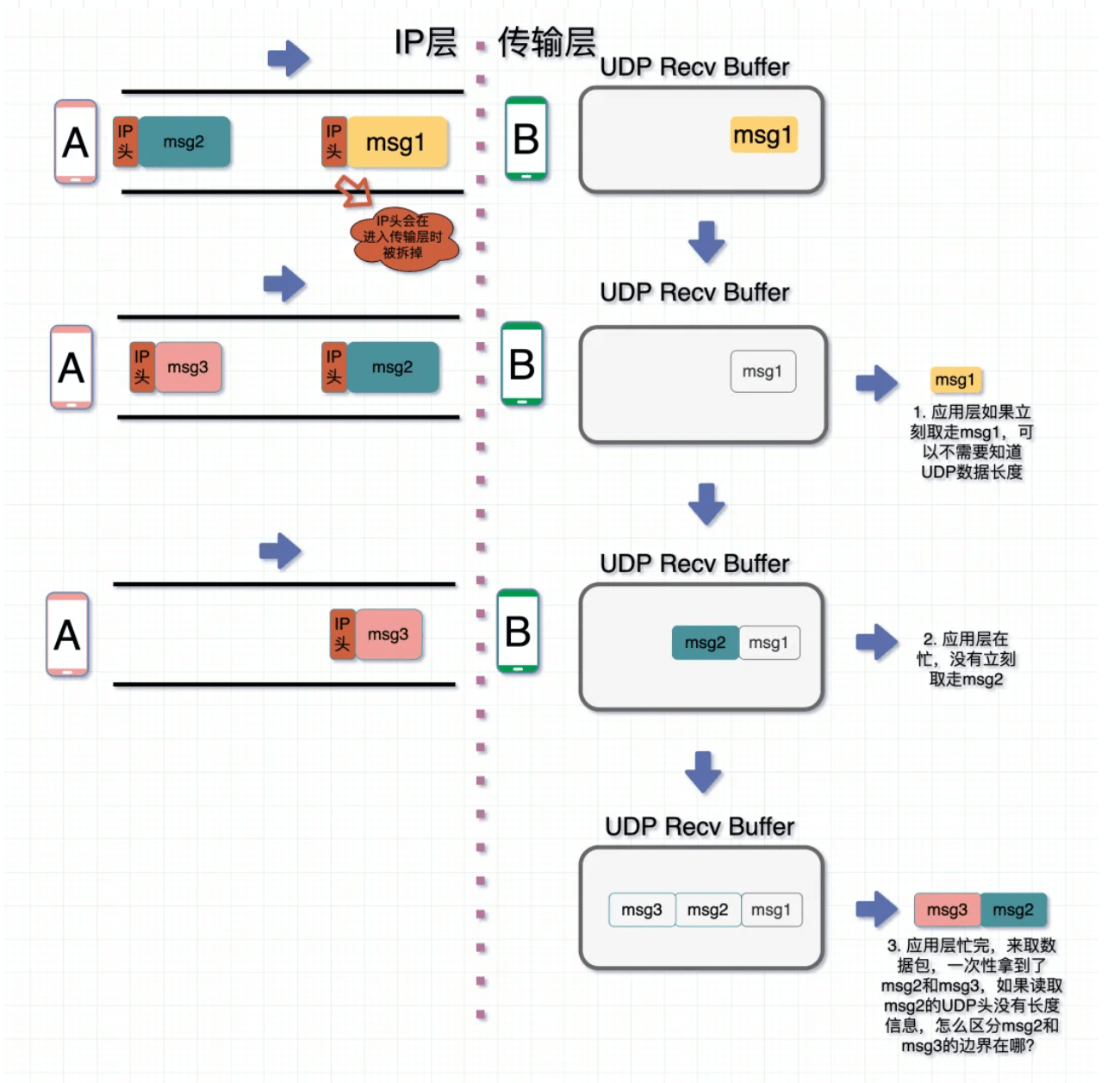
什么是粘包
TCP,Transmission Control Protocol。传输控制协议,是一种面向连接的、可靠的、基于字节流的传输层通信协议。也就是发送一大堆没有边界的01串,而如何理解这些01是应用层的事情,TCP只负责传输。
当发送两个msg时,”李东“ ”亚健康终结者“,接收端收到的可能是这样的信息:

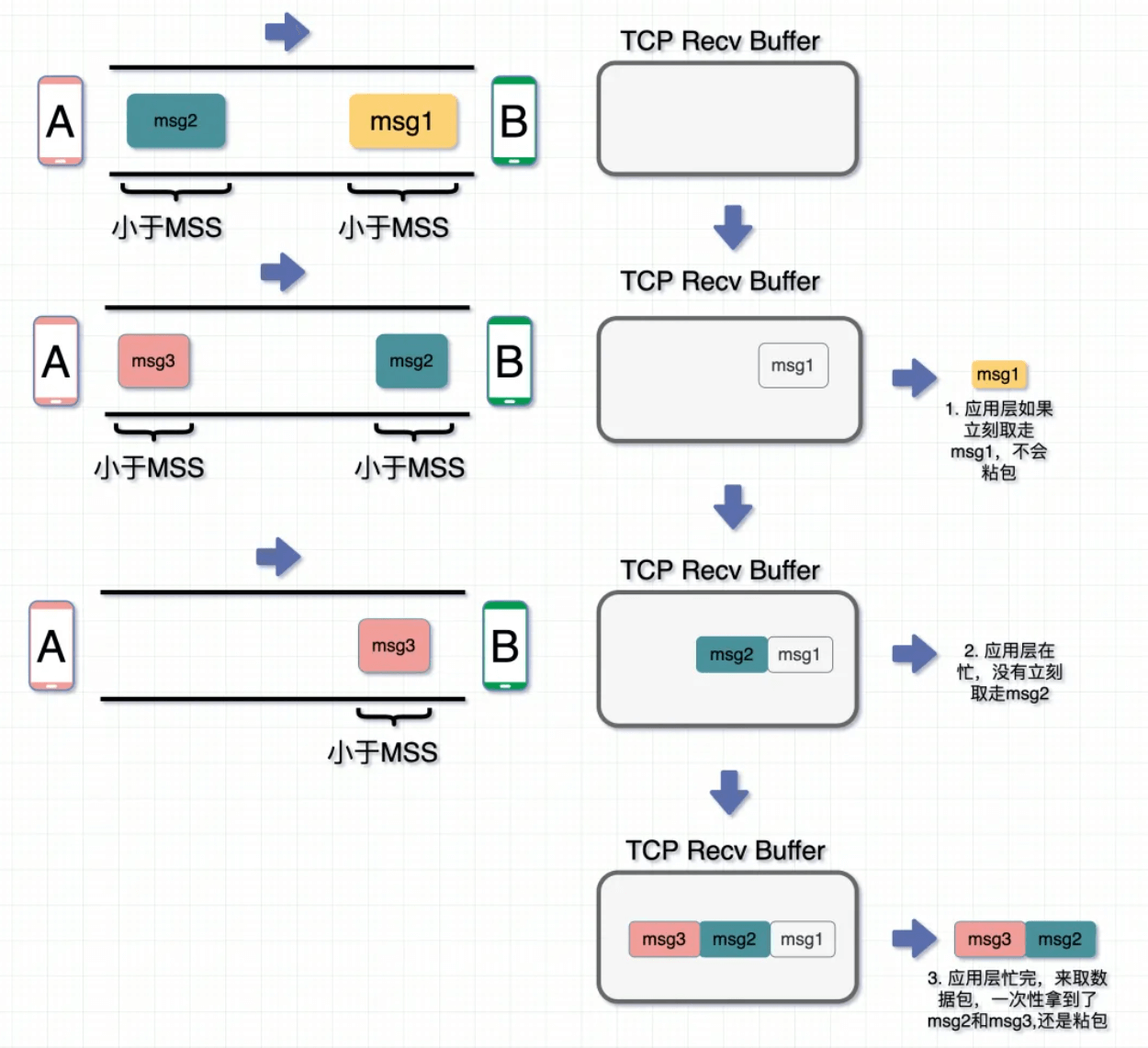
如何处理粘包
- 基于标准的应用层协议(http:content-length、chunked)
- 在每条数据包结尾添加一个特殊字符(chunked)
- 数据包额外添加包头,用于记录长度(content-length)
UDP会粘包吗
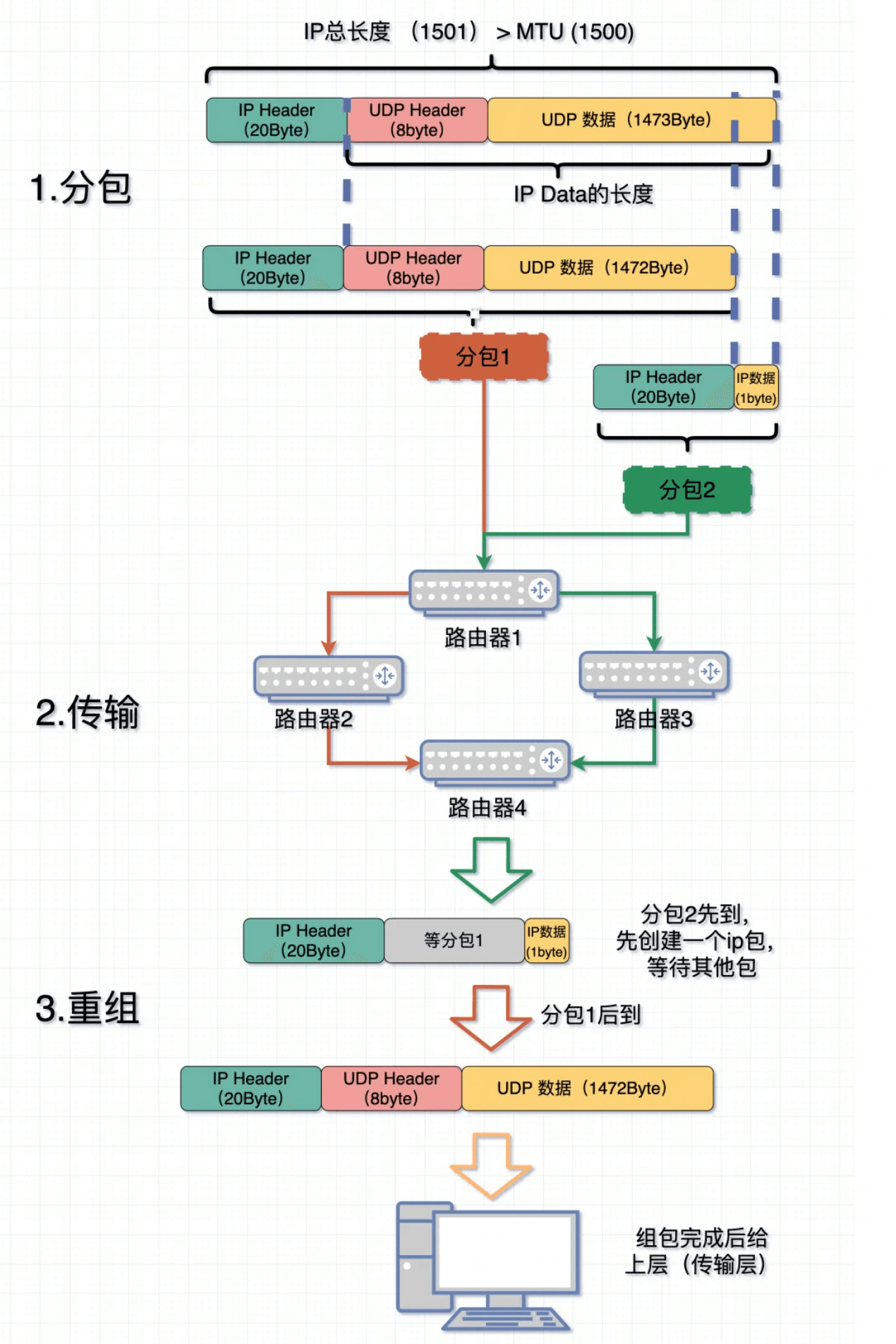
不会,UDP是基于数据报的,而不是字节流的;大的UDP数据包会被分成几个小的IP包,这些包在到达目的地后会被重新组装成原始的数据包。分片和重组是在IP层自动进行的,对UDP来说是透明的。
基于数据报是指无论应用层交给 UDP 多长的报文,UDP 都照样发送,即一次发送一个报文。至于如果数据包太长,需要分片,那也是IP层的事情,大不了效率低一些。UDP 对应用层交下来的报文,既不合并,也不拆分,而是保留这些报文的边界。而接收方在接收数据报的时候,也不会像面对 TCP 无穷无尽的二进制流那样不清楚啥时候能结束。正因为基于数据报和基于字节流的差异,TCP 发送端发 10 次字节流数据,而这时候接收端可以分 100 次去取数据,每次取数据的长度可以根据处理能力作调整;但 UDP 发送端发了 10 次数据报,那接收端就要在 10 次收完,且发了多少,就取多少,确保每次都是一个完整的数据报。

IP层拆包重组
IP层利用Identification(相同)、标志(Flags)和片偏移(Fragment Offset) 保存片段能够按顺序重组
1 | |
长度信息冗余吗?
1 | |
- 允许它在除了IP之外的其他网络层协议上运行,不依赖下层协议
- 长度信息使得在应用层也避免了粘包的发生
总结
- 粘包问题其实就是数据包的边界问题,length是最简单的解决方式
IP 层:我只管把发送端给我的数据传到接收端就完了,我也不了解里头放了啥东西。任务是路由和寻址UDP层是基于数据报的传输协议,不会有粘包问题(有length)。TCP层:任务是完整性和可靠性,但也不管数据的边界,想要确定边界需要添加标识或者直接交给应用层做http层:关注消息的边界(length),tcp层只需要帮我把数据可靠的送到就行