一文搞懂 Redis 架构演化之路(腾讯技术工程)
引言
redis是目前最流行的缓存中间件,但他是如何保证实现稳定并且高性能的提供服务的?
- 如果只是单机版redis,有什么问题?
- 宕机后,如何快速恢复?
- 主从集群以及sentinel可以带来怎样的优势?
- 分片集群作用?
这篇文章从0到1,一步步构建出当前的redis
单机redis
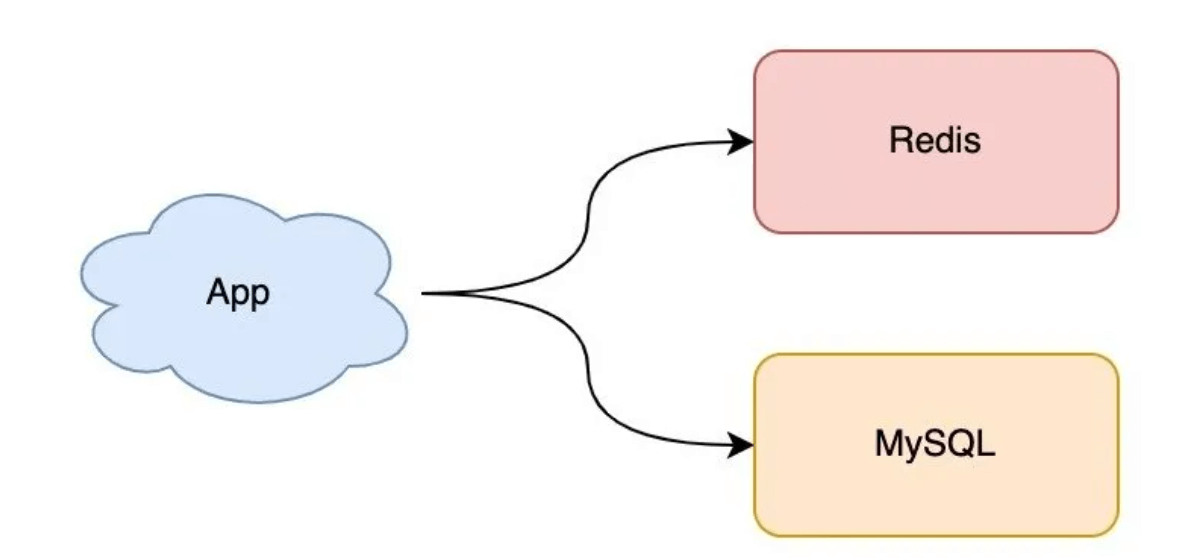
如上图所示,项目的数据最简单的就是直接从mysql读取,现在多了一个redis缓存,并使用cache aside pattern。
在服务不断运行中,项目中redis存储的数据越来越多,如果突然redis宕机,由于redis是内存数据库,全部的数据都会丢失。
- 读数据:就算redis重启了,数据丢失了,构建缓存的过程中数据库压力很大
- 写数据:如果有写数据还没有写入到数据库,数据就永久丢失了
持久化:有备无患
AOF

最简单的持久化操作就是:每执行一个命令,除了更新redis内存外,还写入磁盘,也就是磁盘和redis始终同步。
问题:写磁盘的速度肯定是跟不上redis,如果希望强一致性,那磁盘的读写速度就是redis的性能极限,性能急剧下降。
数据从内存到磁盘分两步:
- 程序写文件的 PageCache(write)
- 把 PageCache 刷到磁盘(fsync)

刚才是每次都执行这两步,现在可以只执行第一步,然后让后台线程去执行fsync操作
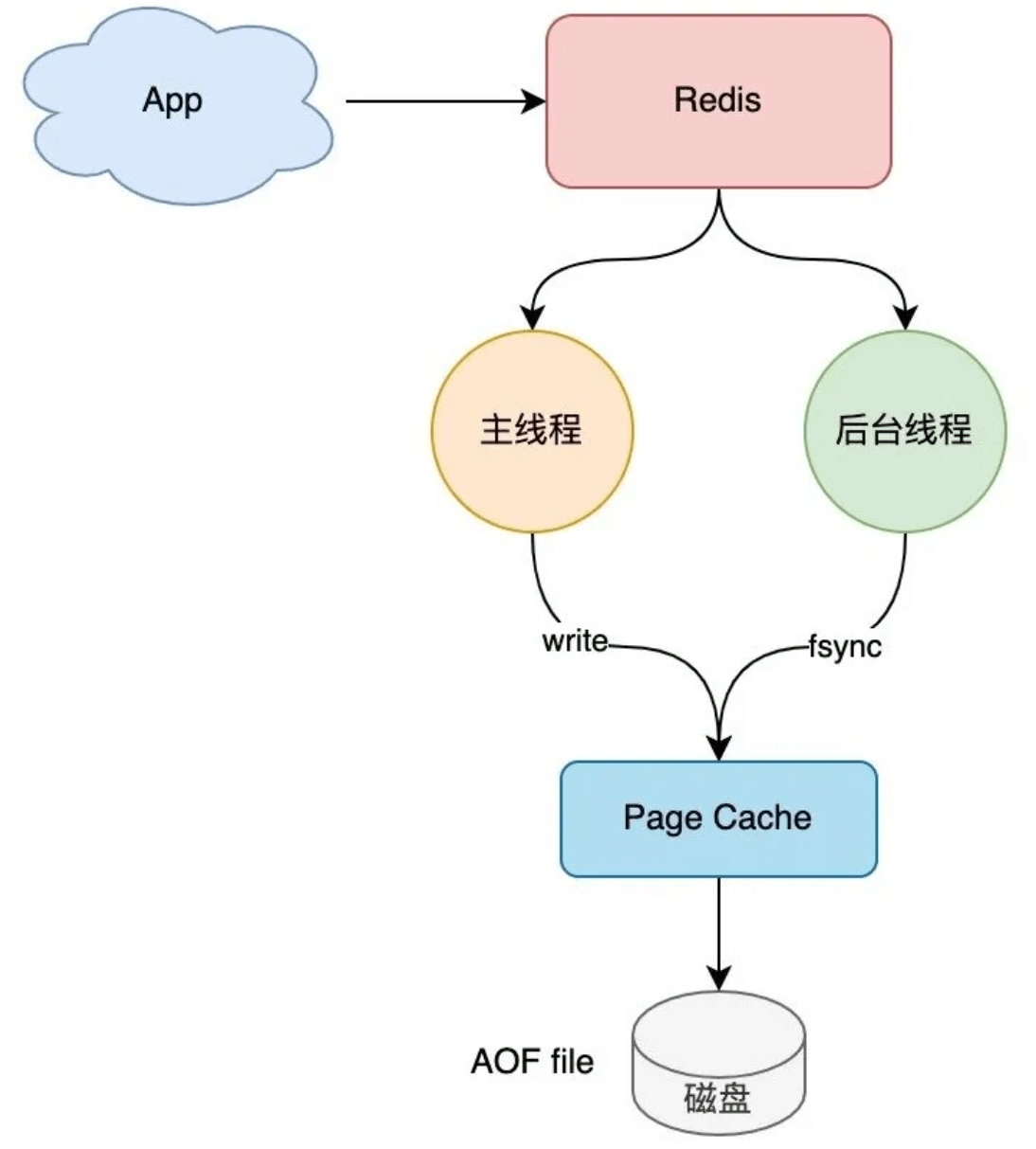
其实这就是AOF,(Append Only File)。
Redis AOF 持久化提供了 3 种刷盘机制:对应着fsync的不同时机
- appendfsync always:主线程同步 fsync
- appendfsync no:由 OS fsync
- appendfsync everysec:后台线程每间隔1秒 fsync;大大减小了io的频率
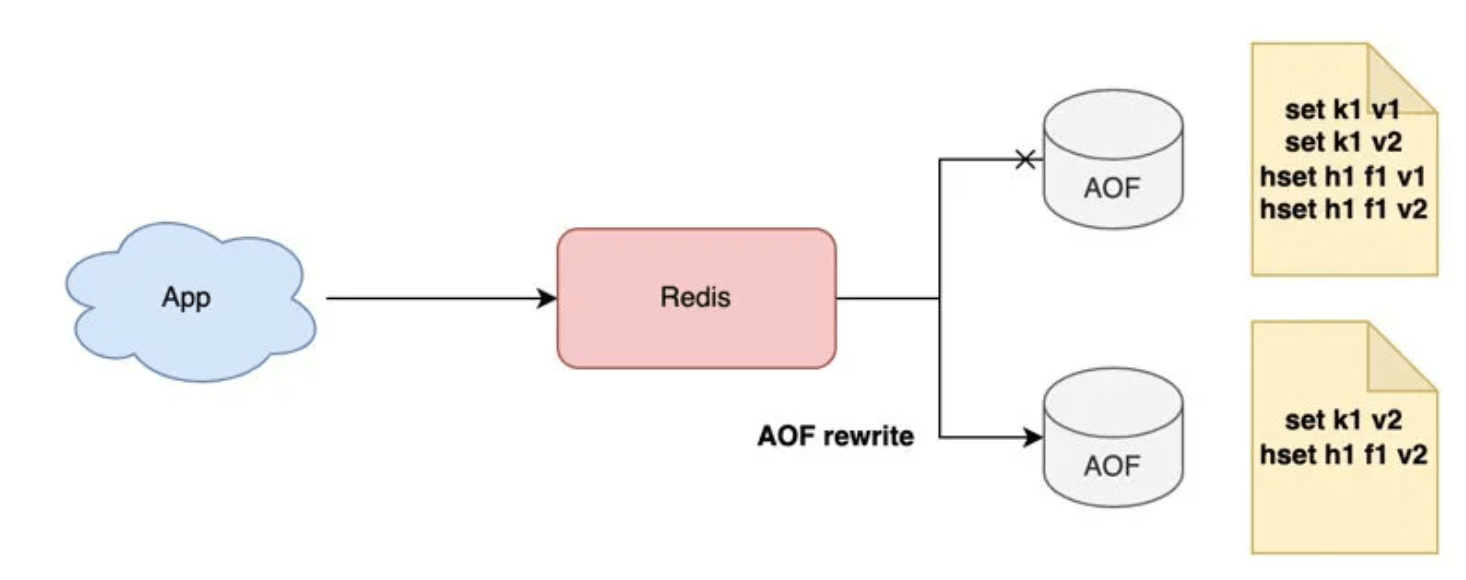
随着时间推移,AOF文件可能越来越大,redis还提供了AOF rewrite使得AOF【瘦身】,如 set k1 v1,set k1 v2,其实我们只需要记录后一条命令就好了(最终版本)
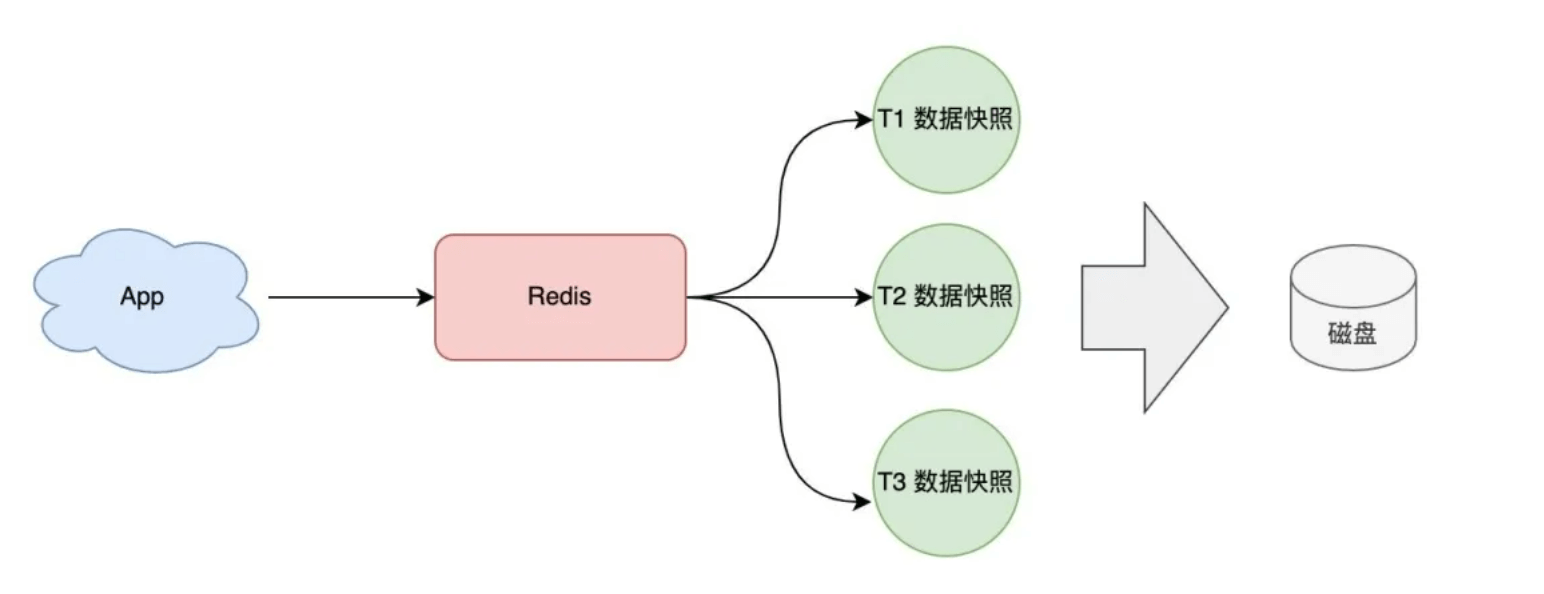
RDB
除了使用基于命令的方式,还可以使用最常用的基于数据快照实现数据的备份
快照的备份时机可以定时的,也可也是最近一段时间数据的修改量 save 300 10 # 100s内有10个key修改了则触发bgsave
优点
- 持久化体积小(二进制+压缩)
- 写盘频率
缺点也很明显,因为是定时持久化,数据肯定没有 AOF 实时持久化完整。
如果你的 Redis 只当做缓存,对于丢失数据不敏感(可从后端的数据库查询),那这种持久化方式是非常合适的。
如果让你来选择持久化方案,你可以这样选择:
- 业务对于数据丢失不敏感,选 RDB
- 业务对数据完整性要求比较高,选 AOF 但文件体积更大、恢复更慢
混合持久化
如何保证数据完整性,又可以让文件更小(恢复更快)呢?
数据完整性:想要保住数据完整性,就需要从AOF下手(记录下每条命令),还想要体积更小,就将RDB快照(二进制+压缩)嵌入到AOF中

当 AOF 在做 rewrite 时,Redis 先以 RDB 格式在 AOF 文件中写入一个数据快照,再把在这期间产生的每一个写命令,追加到 AOF 文件中。
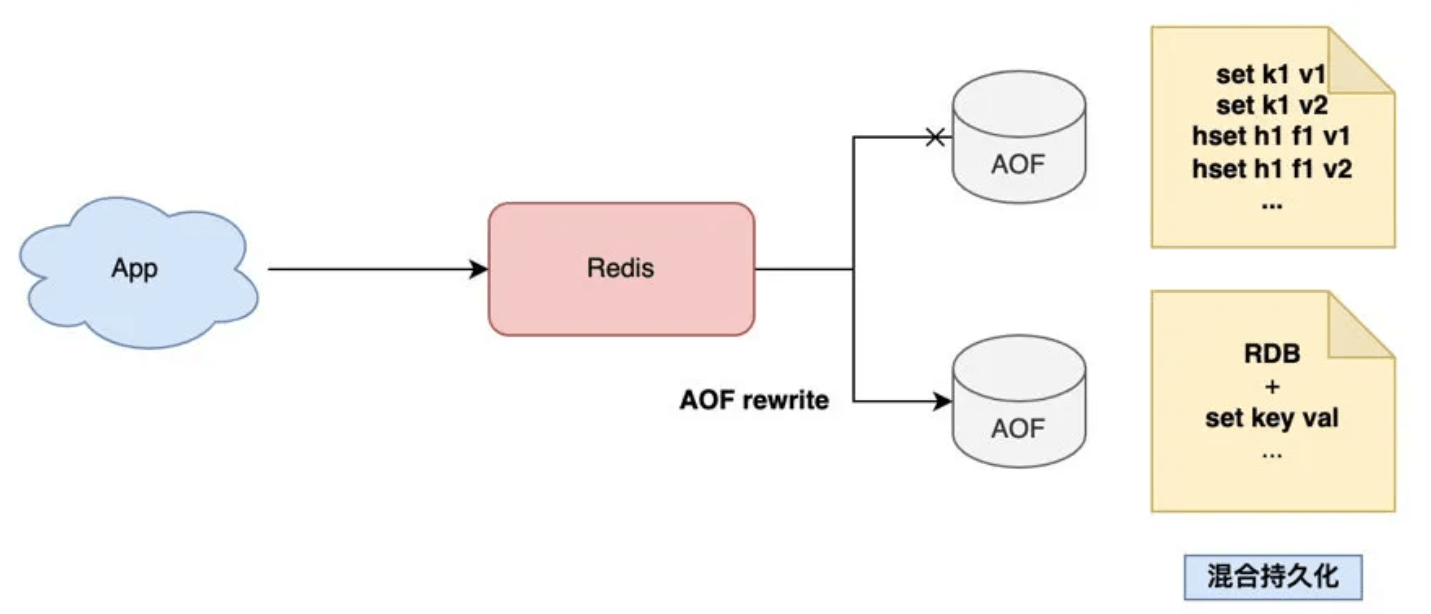
数据恢复时,先加载AOF中的RDB,再执行命令
现在已经实现单机的恢复,但恢复启动的过程中服务还是宕机的,解决方法:引入多个 Redis 实例,这些实例实时进行同步,当一个宕机后剩下的立马可以补救【主从复制:多副本】
主从复制:多副本
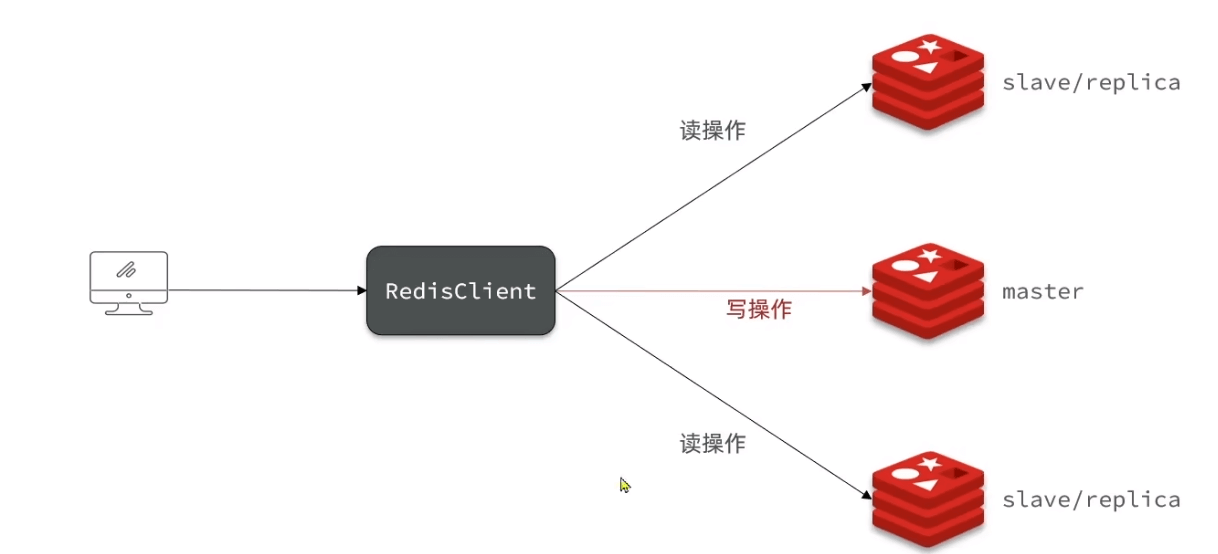
- 缩短不可用时间:master 发生宕机,我们可以手动把 slave 提升为 master 继续提供服务
- 提升读性能:让 slave 分担一部分读请求,提升应用的整体性能
但它的问题在于:当 master 宕机时,我们需要「手动」把 slave 提升为 master,这个过程也是需要花费时间的。
优化:切换的过程,变成自动化?
哨兵:故障自动切换
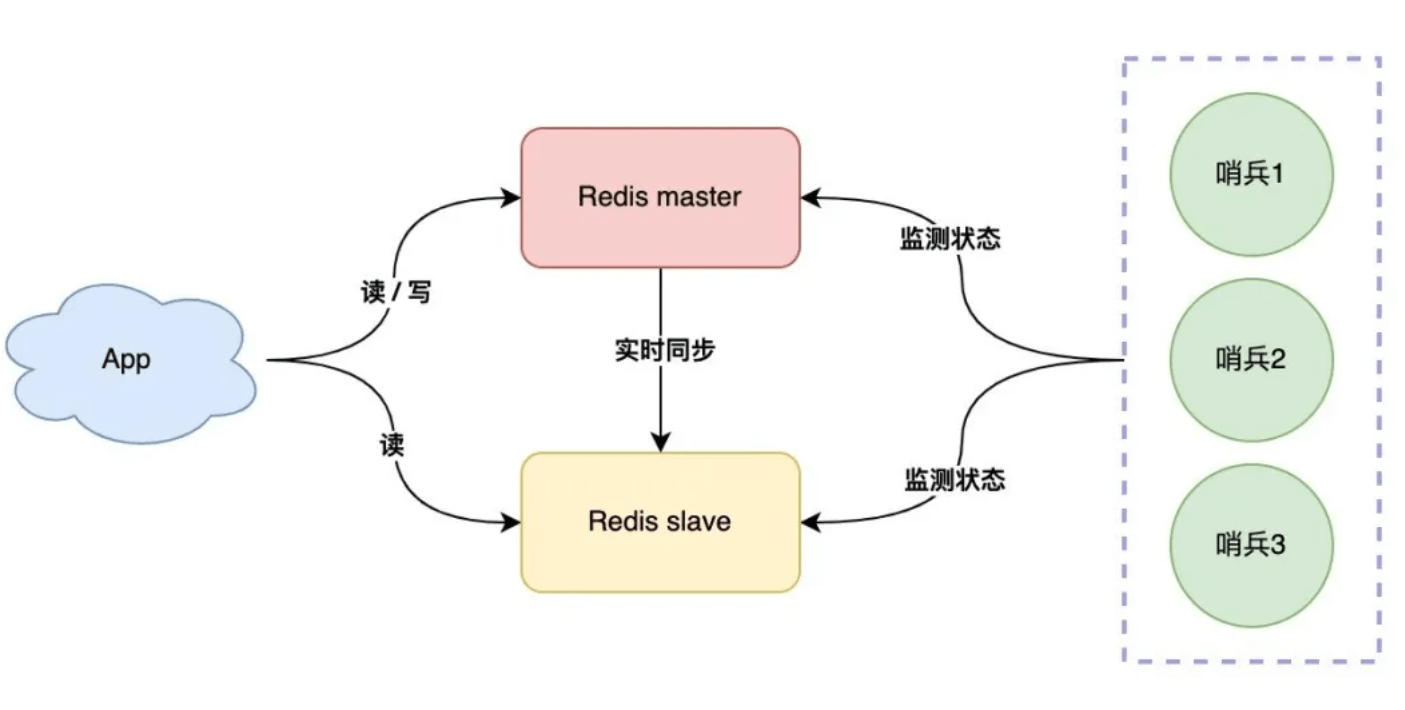
- 引入哨兵实现服务的监控
- 多个哨兵避免网络问题引起的波动
1 | |
共识算法在分布式系统领域有很多,例如 Paxos、Raft,哨兵选举领导者这个场景,使用的是 Raft 共识算法,因为它足够简单,且易于实现。
目前解决的问题:
- 数据怕丢失:持久化(RDB/AOF)
- 恢复时间久:主从副本(副本随时可切)
- 手动切换时间长:哨兵集群(自动切换)
- 读存在压力:扩容副本(读写分离)
- 写存在压力:一个 mater 扛不住怎么办?
集群
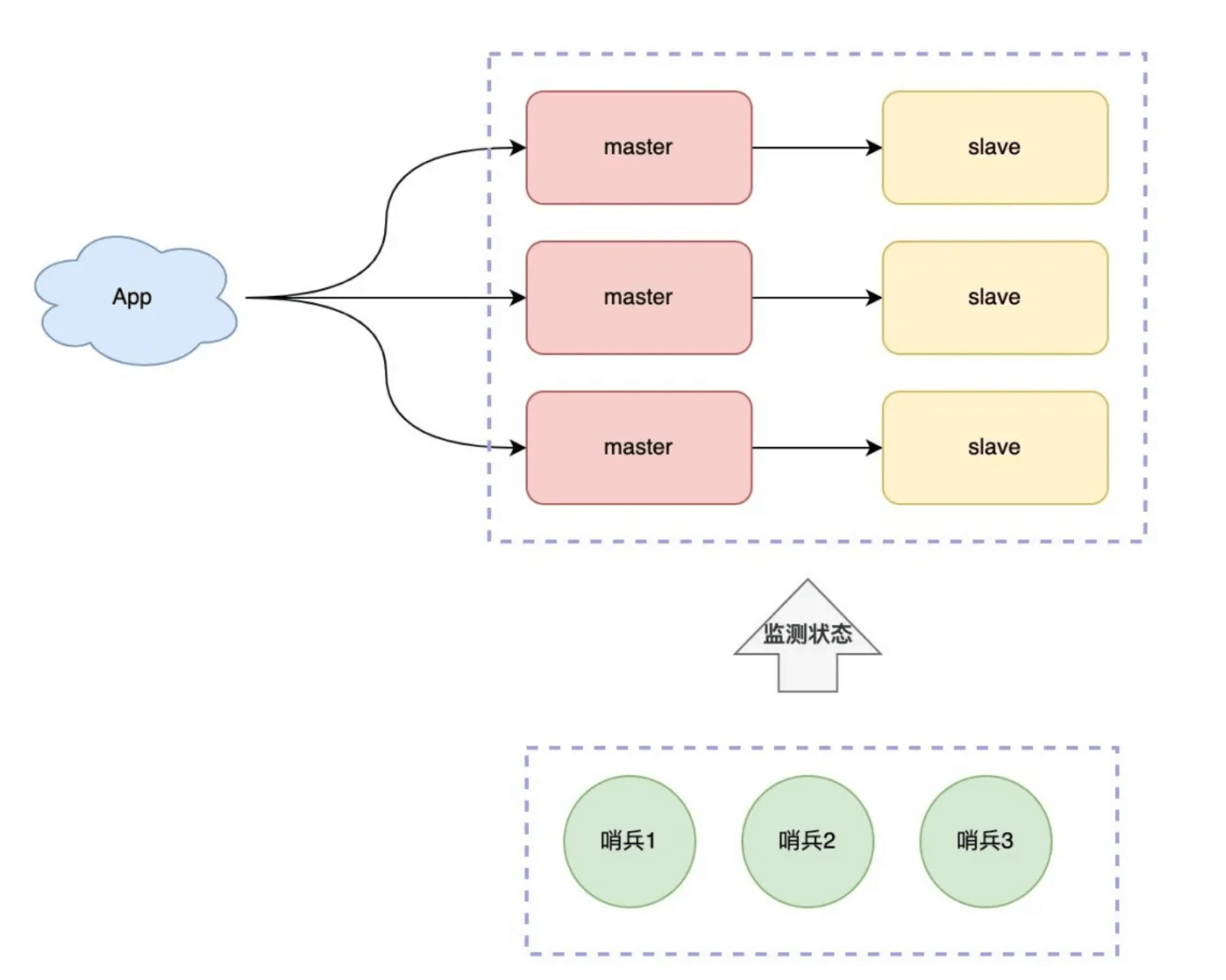
引入多个master分担压力
我们制定规则如下:
- 每个节点各自存储一部分数据,所有节点数据之和才是全量数据
- 制定一个路由规则,对于不同的 key,把它路由到固定一个实例上进行读写
需要一个路由
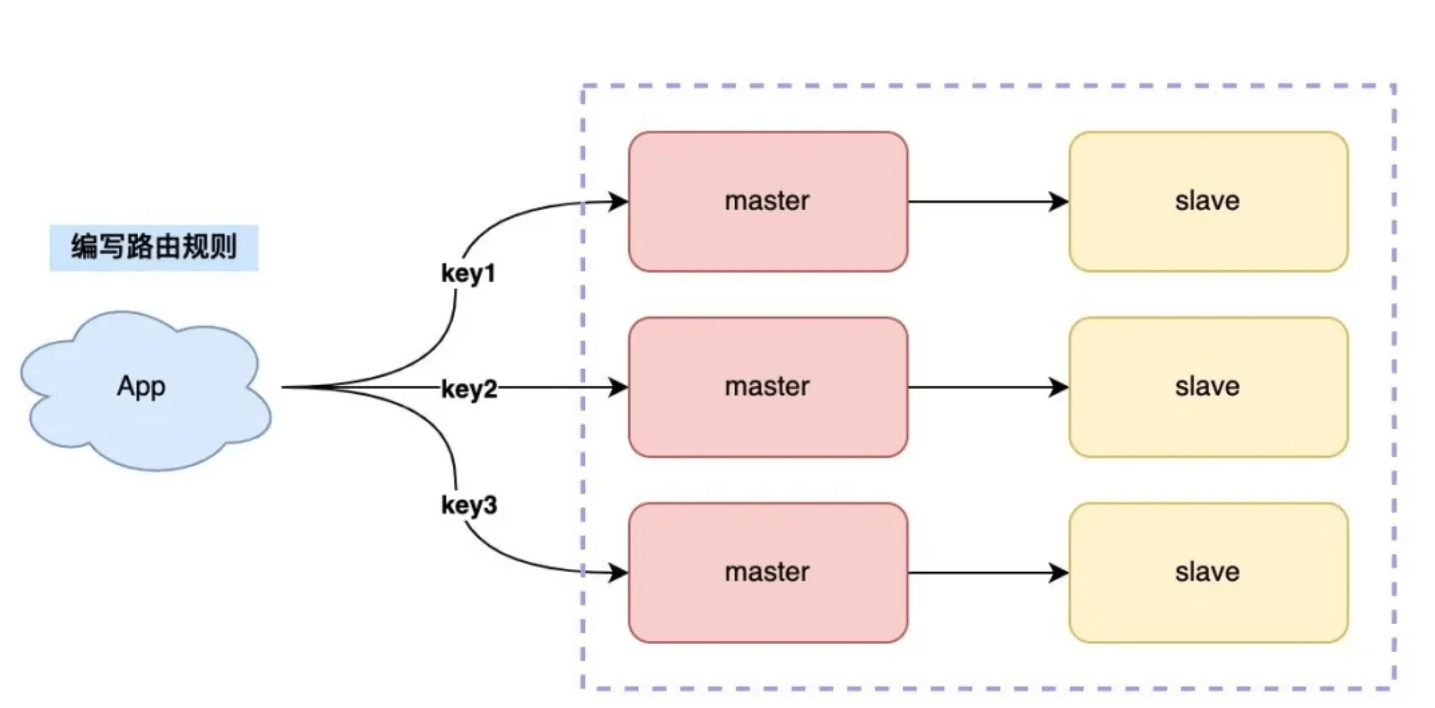
这种方案也叫做「客户端分片」,这个方案的缺点是,客户端需要维护这个路由规则,也就是说,你需要把路由规则写到你的业务代码中。
如何做到不把路由规则耦合在客户端业务代码中呢?
继续优化,我们可以在客户端和服务端之间增加一个「中间代理层」,这个代理就是我们经常听到的 Proxy,路由转发规则,放在这个 Proxy 层来维护。使得proxy后面的一切对客户端来说都是透明无感知的
业界开源的 Redis 分片集群方案,例如 Twemproxy、Codis 就是采用的这种方案。
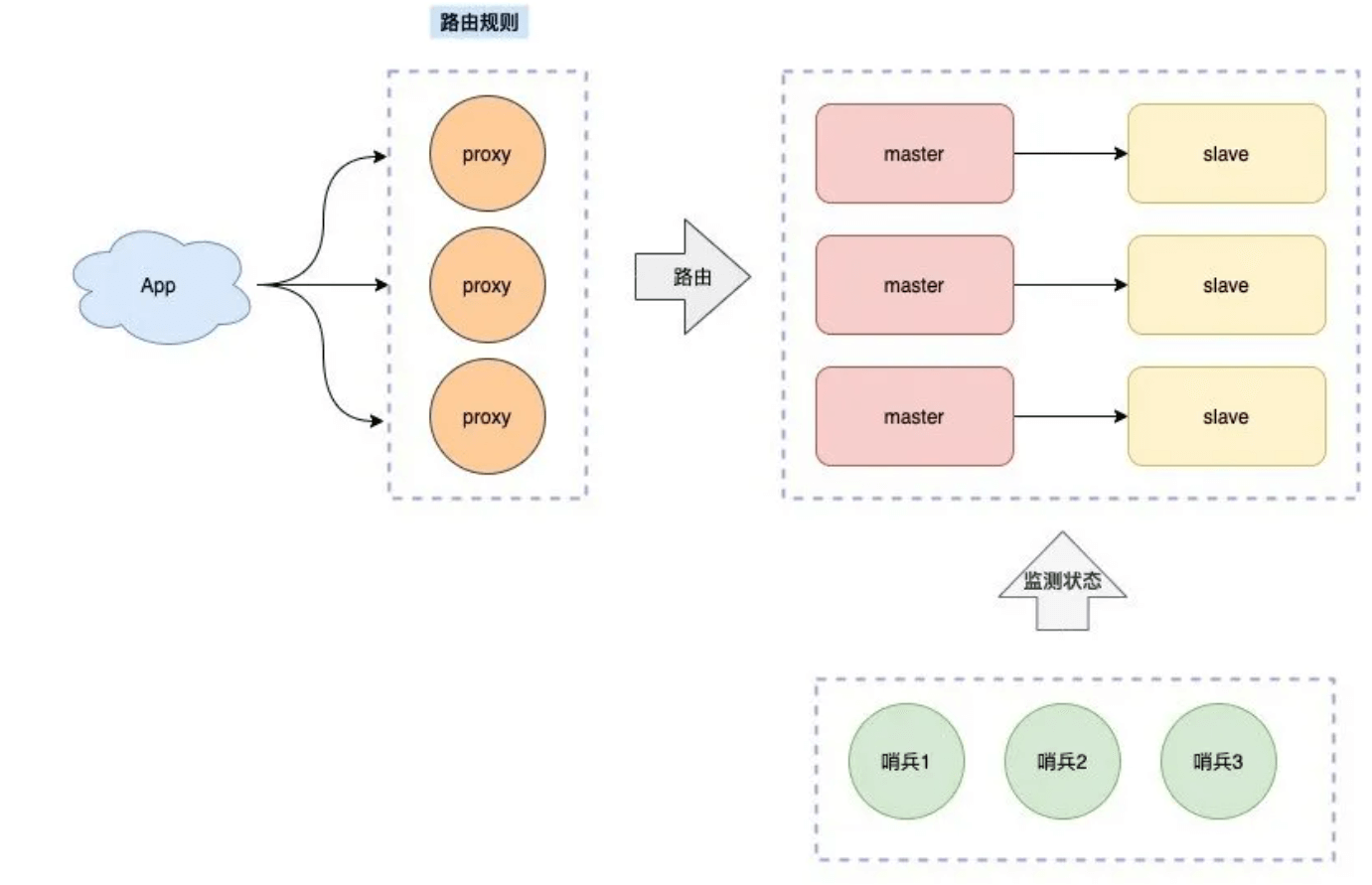
官方
官方方案更加简单,无需路由以及哨兵
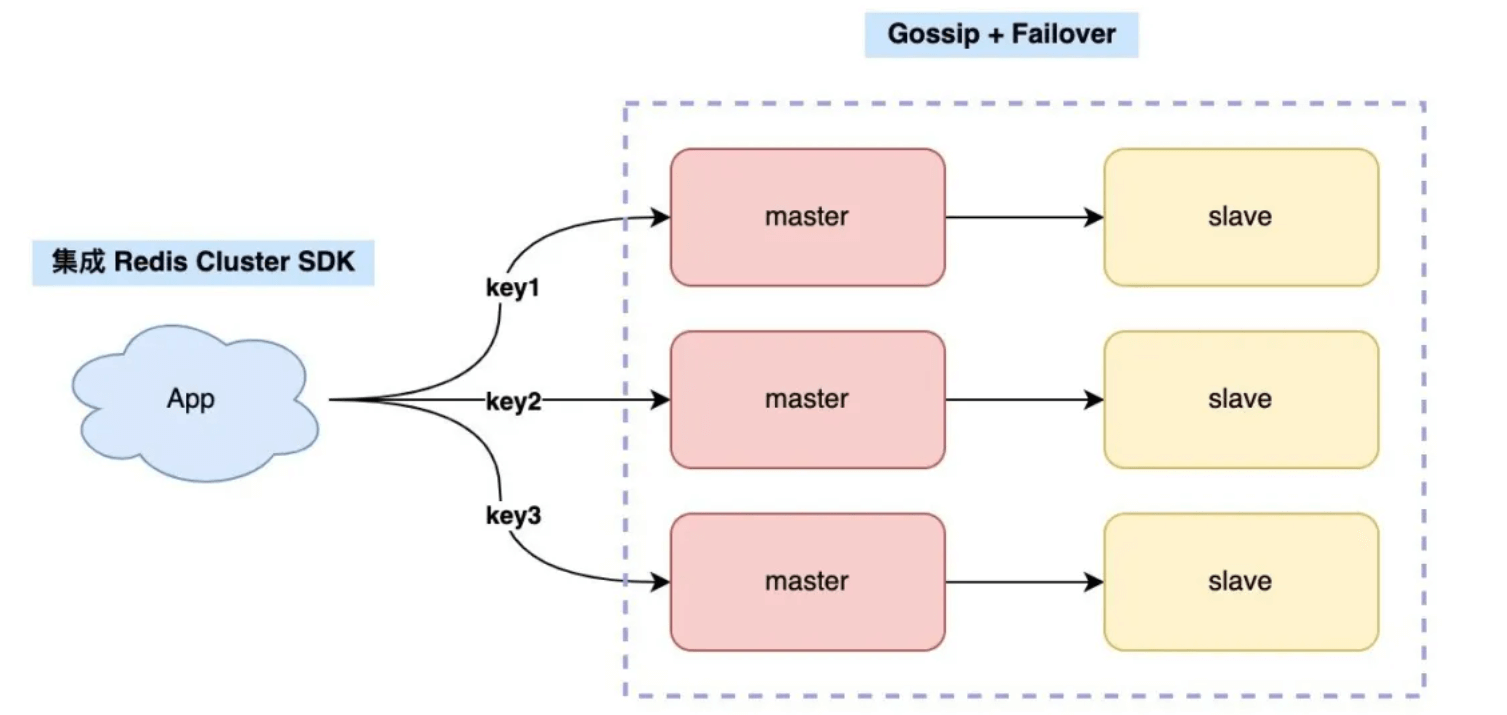
- 故障监控:Redis Cluster 无需部署哨兵集群,集群内 Redis 节点通过 Gossip 协议互相探测健康状态,在故障时可发起自动切换。
- 路由:访问集群的任意节点,会自动转发到正确节点
虽然省去了哨兵集群的部署,维护成本降低了不少,但对于客户端升级 SDK,对于新业务应用来说,可能成本不高,但对于老业务来讲,「升级成本」还是比较高的,这对于切换官方 Redis Cluster 方案有不少阻力。
于是,各个公司有开始自研针对 Redis Cluster 的 Proxy,降低客户端的升级成本,架构就变成了这样:
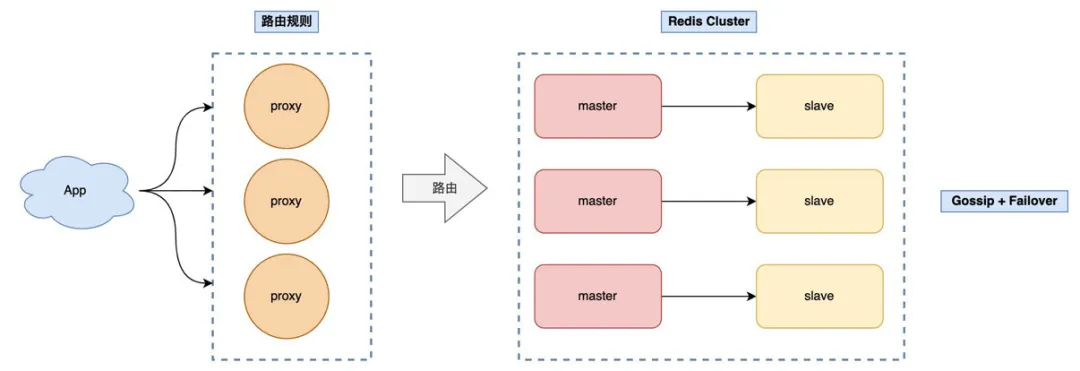
这样,客户端无需做任何变更,只需把连接地址切到 Proxy 上即可,由 Proxy 负责转发数据,以及应对后面集群增删节点带来的路由变更。
至此,业界主流的 Redis 分片架构已经成型,当你使用分片集群后,对于未来更大的流量压力,也都可以从容面对了!
总结
总结一下,我们是如何从 0 到 1,再从 1 到 N 构建一个稳定、高性能的 Redis 集群的,从这之中你可以清晰地看到 Redis 架构演进的整个过程。
- 数据怕丢失 -> 持久化(RDB/AOF)
- 恢复时间久 -> 主从副本(副本随时可切)
- 故障手动切换慢 -> 哨兵集群(自动切换)
- 读存在压力 -> 扩容副本(读写分离)
- 写存在压力/容量瓶颈 -> 分片集群
- 分片集群社区方案 -> Twemproxy、Codis(Redis 节点之间无通信,需要部署哨兵,可横向扩容)
- 分片集群官方方案 -> Redis Cluster (Redis 节点之间 Gossip 协议,无需部署哨兵,可横向扩容)
- 业务侧升级困难 -> Proxy + Redis Cluster(不侵入业务侧)
至此,我们的 Redis 集群才得以长期稳定、高性能的为我们的业务提供服务。