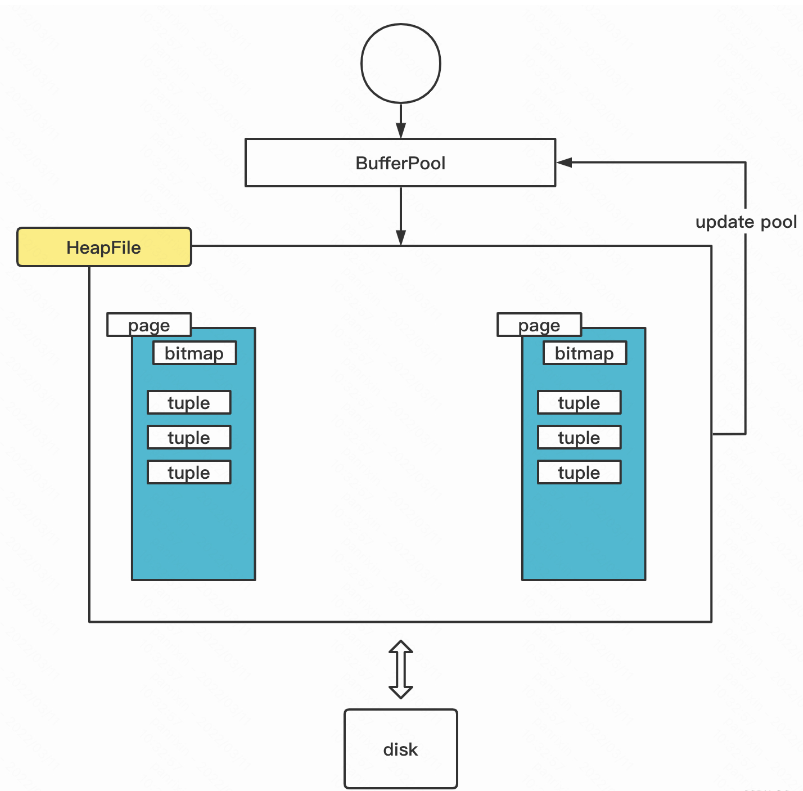
运算符是基于迭代器的;每个运算符都实现了 DbIterator 接口。 较低级别的运算符传递到较高级别运算符的构造函数中,使他们串联起来。叶子节点 Operators are connected together into a plan by passing lower-level operators into the constructors of higher-level operators, i.e., by 'chaining them together.' Special access method operators at the leaves of the plan are responsible for reading data from the disk(and hence do not have any operators below them).
At the top of the plan, the program interacting with SimpleDB simply calls getNext on the root operator; this operator then calls getNext on its children, and so on, until these leaf operators are called. They fetch tuples from disk and pass them up the tree(as return arguments to getNext); tuples propagate up the plan in this way until they are output at the root or combined or rejected by another operator in the plan.
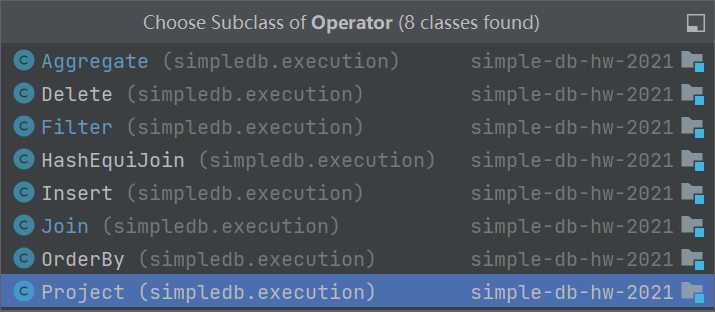
For this lab, you will only need to implement one SimpleDB operator.
// create the table, associate it with some_data_file.dat // and tell the catalog about the schema of this table. HeapFiletable1=newHeapFile(newFile("some_data_file.dat"), descriptor); Database.getCatalog().addTable(table1, "test");
// construct the query: we use a simple SeqScan, which spoonfeeds // tuples via its iterator. TransactionIdtid=newTransactionId(); SeqScanf=newSeqScan(tid, table1.getId());
try { // and run it f.open(); while (f.hasNext()) { Tupletup= f.next(); System.out.println(tup); } f.close(); Database.getBufferPool().transactionComplete(tid); } catch (Exception e) { System.out.println ("Exception : " + e); } }
// create the tables, associate them with the data files // and tell the catalog about the schema the tables. HeapFiletable1=newHeapFile(newFile("lab2_file1.dat"), td); Database.getCatalog().addTable(table1, "t1");
// and run it try { j.open(); while (j.hasNext()) { Tupletup= j.next(); System.out.println(tup); } j.close(); Database.getBufferPool().transactionComplete(tid);
publicclassCostCard { /** The cost of the optimal subplan */ publicdouble cost; /** The cardinality of the optimal subplan */ publicint card; /** The optimal subplan */ public List<LogicalJoinNode> plan; }
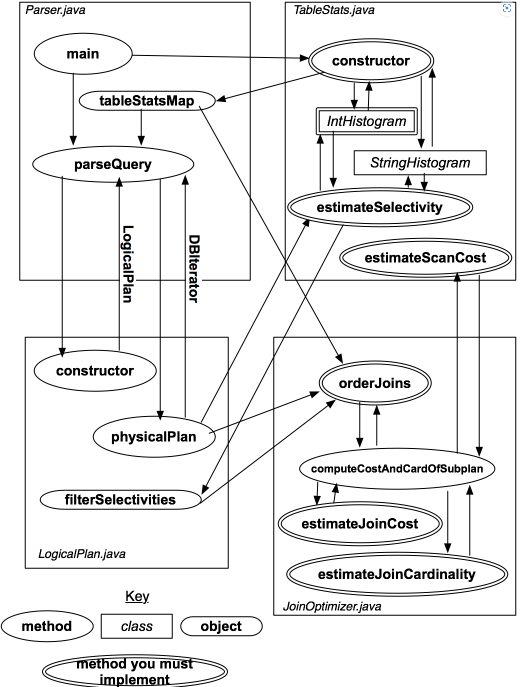
// some code goes here //Replace the following // some code goes here //Replace the following PlanCacheplanCache=newPlanCache(); CostCardbestCostCard=newCostCard(); intsize= joins.size(); for (inti=1; i <= size; i++) { // 找出给定size的所有子集 Set<Set<LogicalJoinNode>> subsets = enumerateSubsets(joins, i); for (Set<LogicalJoinNode> subset : subsets) { doublebestCostSoFar= Double.MAX_VALUE; for (LogicalJoinNode joinNode : subset) { CostCardcostCard= computeCostAndCardOfSubplan(stats, filterSelectivities, joinNode, subset, bestCostSoFar, planCache); if (costCard == null) { continue; } bestCostSoFar = costCard.cost; bestCostCard = costCard; } if (bestCostSoFar != Double.MAX_VALUE) { planCache.addPlan(subset, bestCostCard.cost, bestCostCard.card, bestCostCard.plan); } } } if (explain) { printJoins(bestCostCard.plan, planCache, stats, filterSelectivities); } return bestCostCard.plan; }
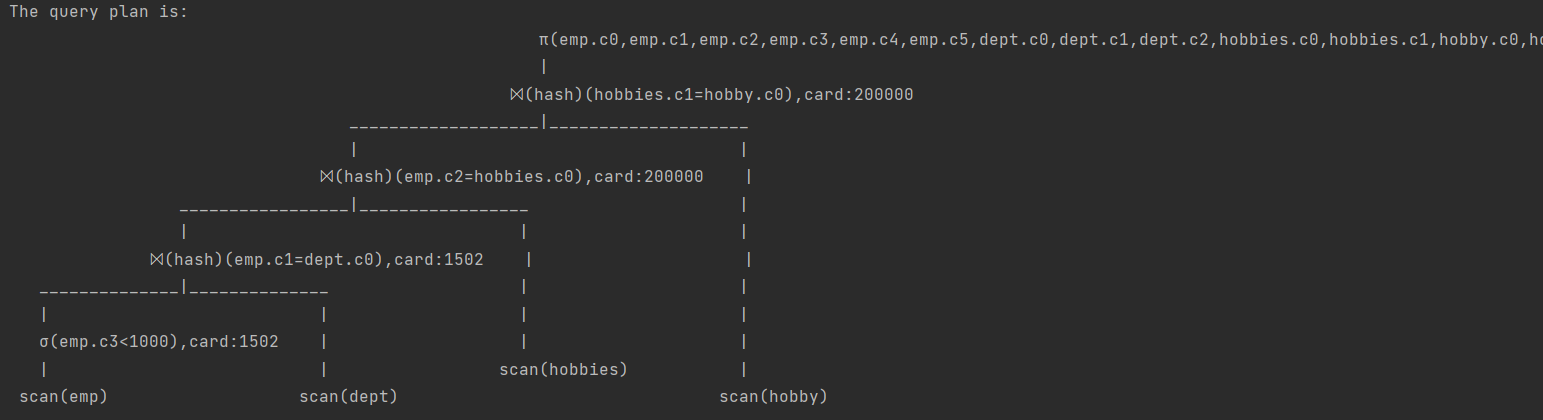
"SELECT * FROM emp,dept,hobbies,hobby WHERE emp.c1 = dept.c0 AND hobbies.c0 = emp.c2 AND hobbies.c1 = hobby.c0 AND emp.c3 < 1000;"
emp过滤后1500: 随机数最大值65530,1500≈(1000/65535*10w)
lab4
A transaction is a group of database actions (e.g., inserts, deletes, and reads) that are executed atomically;
Atomicity: Strict two-phase locking and careful buffer management ensure atomicity.
Consistency: The database is transaction consistent by virtue of atomicity. Other consistency issues (e.g., key constraints) are not addressed in SimpleDB.
Durability: A FORCE buffer management policy ensures durability (see Section 2.3 below).
核心思想:NO STEAL/FORCE
To simplify your job, we recommend that you implement a NO STEAL/FORCE buffer management policy.
You shouldn’t evict dirty (updated) pages from the buffer pool if they are locked by an uncommitted transaction (this is NO STEAL).
由于只在最后刷盘,不需要undo了,失败只要重新从磁盘加载page即可
On transaction commit, you should force dirty pages to disk (e.g., write the pages out) (this is FORCE).
假设transactionComplete不会失败,这样就不需要redo log
lock acquire
acquire and release locks in BufferPool
Modify getPage() to block and acquire the desired lock before returning a page. 核心方法,阻塞获取锁
Implement unsafeReleasePage(tid, pid). This method is primarily used for testing, and at the end of transactions. 释放tid在pid上的锁
Implement holdsLock(tid, pid) so that logic in Exercise 2 can determine whether a page is already locked by a transaction. tid是否锁住pid
create data structures that keep track of which locks each transaction holds and check to see if a lock should be granted to a transaction when it is requested:hashmap: pageid->locks
插入 删除 查找都是调用pool的getPage,需要传入正确的permission
被操作的页置为dirty
插入时创建了新的page,能否正常锁定
release
strict two-phase locking:This means that transactions should acquire the appropriate type of lock on any object before accessing that object and shouldn’t release any locks until after the transaction commits.
release a shared lock on a page after scanning it to find empty slots
Insert the following lines into BufferPool.flushPage() before your call to writePage(p), where p is a reference to the page being written: 在page写回磁盘前,先将log写回,包含最开始的内容(BeforeImage)以及当前内容
1 2 3 4 5 6 7 8 9 10 11
// append an update record to the log, with // a before-image and after-image. TransactionIddirtier= p.isDirty(); if (dirtier != null){ Database.getLogFile().logWrite(dirtier, p.getBeforeImage(), p); Database.getLogFile().force(); } if (page.isDirty() != null){ table.writePage(page); page.markDirty(false, null); }
在commit并刷盘后,更新BeforeImage,
1 2 3 4 5
flushPages(tid) flushPage(pageId); // use current page contents as the before-image // for the next transaction that modifies this page. page.setBeforeImage();