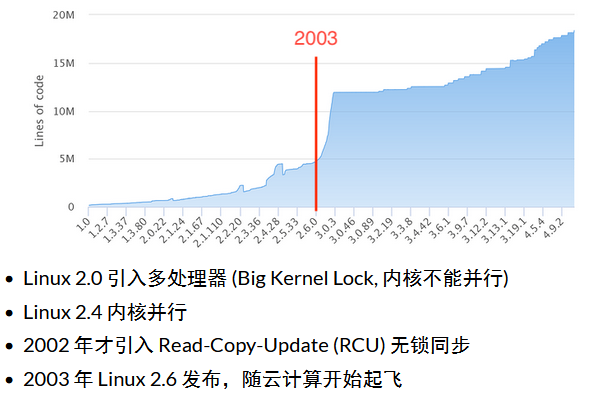
有什么不懂的直接问gpt
什么是程序 00 01 10 00 01 10
源代码角度 同时我们也可以用C语言实现
状态:内存中的所有东西,全部栈帧
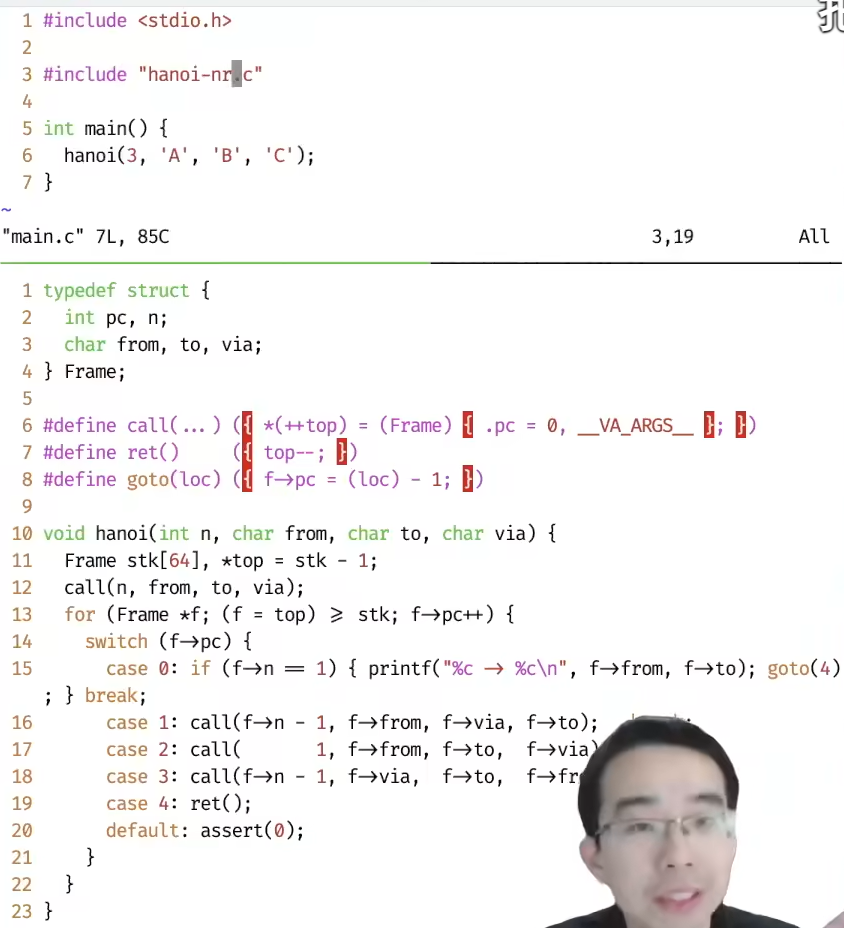
使用栈模拟递归
二进制角度
状态:内存 + 寄存器
初始状态:
迁移:一条01指令
任何的程序都需要退出,也就是结束。因此需要特别的指令 syscall 把现在的状态交给操作系统
程序 = 普通计算 + syscall
实现与操作系统中别的对象交互
读写文件 如果有权限,操作系统把状态写入程序的M, R
改变进程 杀死程序
如何构造一个printf("hello world")
操作系统
收编了所有对象(包含程序状态机和文件),实现霸主地位
管理多个状态机,根据权限访问。打开文件,屏幕显示
在程序眼里,操作系统就是syscall,程序 = (普通计算 + syscall) 如何只展示syscall
strace a.out 去掉计算,只展示用到的所有的系统调用
c语言的第一条程序是什么,谁定义的,能不能修改
计算机没有玄学,一切都建立在确定的机制上。bug只要能复现,就能解决
Python操作系统 思路
应用程序 = 纯粹计算(Python 代码) + syscall; 状态机
操作系统 = Python syscall实现,有 “假想” 的 I/O 设备; 管理状态机
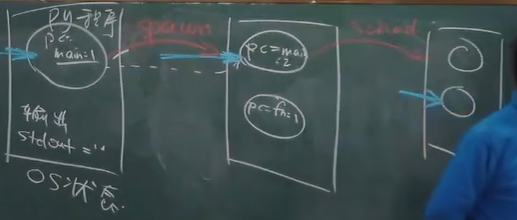
操作系统为方框,程序为圆圈,操作系统管理全部程序,并且会提供红色的syscall指令。蓝色为当前运行程序spawn创建程序后,操作系统有了选择,到底执行哪一个程序呢?
四个 “系统调用” API
choose(xs): 返回 xs 中的一个随机选项,纯粹的计算不能实现随机write(s): 输出字符串 sspawn(fn): 创建一个可运行的状态机 fnsched(): 随机切换到任意状态机执行(这里是主动切换,实际也存在被OS强制切换)
demo-code 我进行状态机切换,肯定需要保存状态(变量值是多少、pc在哪) : yield (实际OS由一段汇编代码将当前状态机 (执行流) 的寄存器保存到内存中)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 import sysimport randomfrom pathlib import Pathclass OperatingSystem ():"""A minimal executable operating system model.""" 'choose' , 'write' , 'spawn' , 'sched' ]class Thread :"""A "freezed" thread state.""" def __init__ (self, func, *args ):None def step (self ):"""Proceed with the thread until its next trap.""" None return syscall, argsdef __init__ (self, src ):exec (src, variables)'main' ]def run (self ):while threads: try :match (t := threads[0 ]).step():case 'choose' , xs: case 'write' , xs: print (xs, end='' )case 'spawn' , (fn, args): case 'sched' , _: except StopIteration: if __name__ == '__main__' :if len (sys.argv) < 2 :print (f'Usage: {sys.argv[0 ]} file' )1 )1 ]).read_text()for syscall in OperatingSystem.SYSCALLS:f'sys_{syscall} ' , f'yield "{syscall} ", ' )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 count = 0 def Tprint (name ):global countfor i in range (3 ):1 f'#{count:02} Hello from {name} {i+1 } \n' )def main ():3 , 4 , 5 ])f'#Thread = {n} \n' )for name in 'ABCDE' [:n]:
more 进程 + 线程 + 终端 + 存储 (崩溃一致性)
系统调用/Linux 对应
行为
sys_spawn(fn)/pthread_create
创建从 fn 开始执行的线程
sys_fork()/fork
创建当前状态机的完整复制
sys_sched()/定时被动调用
切换到随机的线程/进程执行
sys_choose(xs)/rand
返回一个 xs 中的随机的选择
sys_write(s)/printf
向调试终端输出字符串 s
sys_bread(k)/read
读取虚拟设磁盘块 �k 的数据
sys_bwrite(k, v)/write
向虚拟磁盘块 �k 写入数据 �v
sys_sync()/sync
将所有向虚拟磁盘的数据写入落盘
sys_crash()/长按电源按键
模拟系统崩溃
mosaic.py:500行操作系统。还实现了打印每一步的状态
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 T = 3 3 def Tsum ( ):for _ in range (n):1 1 def main ():0 0 for _ in range (T):while heap.done != T:f'SUM = {heap.x} ' )
不确定性发生在sys_sched(), --check 遍历所有答案
1 2 3 4 5 6 7 8 9 10 void Tsum () {for (int i = 0 ; i < n; i++) {int tmp = sum;2 ~n*T]
并发 1.放弃原子性
1 2 3 4 5 6 7 8 9 unsigned int balance = 100 ;int Alipay_withdraw (int amt) {if (balance >= amt) {return SUCCESS;else {return FAIL;
1 for (int i = 0 ; i < N; i++) sum++;
printf("a") 为什么不会报错?带了锁
互斥和原子性是本学期的重要主题
2.顺序丧失
1 2 3 4 5 6 7 8 9 10 -O1: R[eax] = sum; R[eax] += N; sum = R[eax]100000000 200000000 while (!done);if (!done) while (1 );
3.丧失可见性
理论上输出 01 10 11, 但其实00也有输出
处理器也是一个编译器,一条指令拆分多个uops
如果想写入x时未命中,print就可以先执行
1 2 3 4 5 6 7 8 9 10 11 12 13 int x = 0 , y = 0 ;void T1 () {1 ;asm volatile ("" : : "memory" ) ; printf ("y = %d\n" , y);void T2 () {1 ;asm volatile ("" : : "memory" ) ; printf ("x = %d\n" , x);
在共享内存 实现并发时,一个反例 get set不是原子操作
1 2 3 4 5 6 7 8 9 10 11 12 13 int locked = UNLOCK;void critical_section () {if (locked != UNLOCK) {goto retry;
Peterson 棋子代表:我想上厕所;门上贴的人代表着:谁能上厕所
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 int x = 0 , y = 0 , turn = A;while (1 ) {1 */ x = 1 ;2 */ turn = B;3 */ while (y && turn == B) ;4 */ x = 0 ; } }while (1 ) {1 */ y = 1 ;2 */ turn = A;3 */ while (x && turn == A) ;4 */ y = 0 ; } }
证明正确性:直接画出状态机表达出全部状态。
Model Checker 并发程序 = 状态机,画出状态机就可以知道并发程序有没有错
1 2 3 4 5 6 7 8 9 10 11 12 13 class Mutex :'' def T1 (self ):yield checkpoint()while True :yield checkpoint()while self.locked == '🔒' :yield checkpoint()pass yield checkpoint()'🔒'
使用程序去遍历出全部的状态 Model Checker
没有工具(编程、测试、调试),不做系统
1 2 3 4 5 typedef struct {lock_t ;void lock (lock_t *lk) ;void unlock (lock_t *lk) ;
还是原来难点:get set 非原子
自旋锁 spin lock 硬件 能为我们提供一条 “瞬间完成” 的读 + 写指令
xchg dest, src 原子的实现交换数据,并返回原来的值。 这样就可以实现两个线程之间的锁
1 2 3 4 5 6 7 8 9 10 int xchg (volatile int *addr, int newval) {int result;asm volatile ("lock xchg %0, %1" : "+m" (*addr), "=a" (result) : "1" (newval)) ;return result;int locked = 0 ;void lock () { while (xchg(&locked, 1 )) ; }void unlock () { xchg(&locked, 0 ); }
处理器保证,带lock的指令可以锁定总线,xchg默认带lock
两个cpu共享内存时,带lock指令会锁住memory ,硬件实现,一个bit实现bus lock
cpu有缓存L1,如何保证缓存一致。当一个cpu锁定memory时,需要把别的cpu的缓存都剔除
Load-Reserved/Store-Conditional,硬件里会实现
Compare-and-Swap:乐观锁
1 2 3 4 5 6 int cas (int *addr, int cmp_val, int new_val) { int old_val = *addr;if (old_val == cmp_val) {return 0 ;else { return 1 ; }
缺陷 :未获得锁的线程在空转,甚至获取锁的线程被OS切换了,所以需要不拥堵时 使用
操作系统内部自己使用:操作系统内核的并发数据结构 (短临界区);关中断
互斥锁 Mutex Lock 与其干等,不如把cpu让给别的线程执行,阻塞
把锁的实现放到操作系统 里就好!
未得到锁会进入等待队列,释放锁时OS会取出等待队列中一个线程,OS使用自旋锁 确保自己处理过程是原子的
上锁失败会睡眠,不占用CPU,但不管有没有竞争都需要进出内核系统调用,带来一定的开销
Futex = Spin + Mutex Fast Userspace muTexes,无竞争情况下,能够避免系统调用的开销
1.自旋锁 (线程直接共享 locked)
更快的 fast path
更慢的 slow path
2.睡眠锁 (通过系统调用访问 locked)
更快的 slow path
更慢的 fast path
3.融合 :先原子指令上锁,失败后系统调用睡眠
线程库的锁就是这样的锁,但还有很多的优化 以减少系统调用
code:Kernel为操作系统需要做的,这里使用while模拟
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 class Futex :'' , '' def tryacquire (self ):if not self.locked:'🔒' return '' else :return '🔒' def release (self ):if self.waits:1 :]else :'' @thread def t1 (self ):while True :if self.tryacquire() == '🔒' : '1' while '1' in self.waits: pass True del cs @thread def t2 (self ):while True :if self.tryacquire() == '🔒' :'2' while '2' in self.waits:pass True del cs
Fast/slow paths:性能优化的途径
有了基本的互斥锁,现在需要通过他实现一些线程间的同步机制。有锁时默认使用Futex
线程同步:共同达到互相已知的状态
生产者消费者(解决并发的万能钥匙):等价于打印左右括号,左括号往队列加资源,右括号消费资源
自旋锁、互斥锁、条件变量、信号量、管道(通信)
互斥锁 count计数左括号,是共享资源需要互斥,使用spin lock实现互斥访问count,并且如果不符合条件就反复询问
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 int n, count = 0 ;while (1 ) {if (count == n) {"(" );while (1 ) {if (count == 0 ) {")" );
万能的条件变量 我希望不要循环,在不满足时进行sleep
条件变量 API:在不符合某条件时,等待别人通过cv唤醒我 cv是程序间的暗号 需要访问共享条件当然要加锁
wait(cv, mutex) 💤 release(mutex)、sleep
调用时必须保证已经获得 mutex
醒来时需要获取mutex
signal/notify(cv) 💬 私信:走起
broadcast/notifyAll(cv) 📣 所有人:走起
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void Tproduce () {if (count == n) cond_wait(&cv, &lk); printf ("(" ); count++; cond_signal(&cv);void Tconsume () {if (count == 0 ) cond_wait(&cv, &lk);printf (")" ); count--; cond_signal(&cv);if 检测改成while 循环
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 class ProducerConsumer :'' , 0 , '' , '' def tryacquire (self ):'🔒' , self.lockedreturn seen == '' def release (self ):'' @thread def tp (self ):for _ in range (2 ):while not self.tryacquire(): pass if self.count == 1 :'1' while '1' in self.waits: pass while not self.tryacquire(): pass '(' , self.count + 1 1 :] @thread def tc1 (self ):while not self.tryacquire(): pass if self.count == 0 :'2' while '2' in self.waits: pass while not self.tryacquire(): pass ')' , self.count - 1 1 :] @thread def tc2 (self ):while not self.tryacquire(): pass if self.count == 0 :'3' while '3' in self.waits: pass while not self.tryacquire(): pass ')' , self.count - 1 1 :]
两个条件变量实现
1 2 3 4 5 6 7 8 9 10 11 12 void Tproduce () {if (count == n) cond_wait(&c, &lk); printf ("(" ); count++; cond_signal(&p);void Tconsume () {if (count == 0 ) cond_wait(&p, &lk);printf (")" ); count--; cond_signal(&c);
while循环+broadcast 通用模板
1 2 3 4 5 6 7 8 9 10 11 12 13 mutex_lock(&mutex);while (!cond) { cond可以多个条件while 还是会睡眠
作业:打印指定的形状 <><_ 和 ><>_ http://jyywiki.cn/pages/OS/2022/demos/fish.c
处理器可以乱序执行,先执行第二条,但13需要顺序执行,硬件实现顺序执行
1 2 3 x = 0 write
信号量PV 在执行前需要某些东西,没有就睡眠等到有。happens before。优雅但不全
最好解决单一资源 问题,但上面的打印🐟难以实现
token为资源数量,当token=1、0时就代表互斥锁Mutex,没得到就睡眠(但相当于有多把钥匙)
P: token– if token < 0,线程加入等待队列
V:token++ if token<=0, 唤醒等待队列
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Semaphore :1 , '' def P (self, tid ):if self.token > 0 :1 return True else :return False def V (self ):if self.waits:1 :]else :1
1 2 3 4 5 6 7 8 9 10 void producer () {printf ("(" ); void consumer () {printf (")" );
线程同步 1 2 3 4 5 6 7 8 9 A -> B 如果使用条件变量,可能出现A已经执行,但B还没进入0 0
计算图 如果想要并行,就需要画出计算图,并让程序按计算图执行:PV很方便
每条边PV各一次
打印🐟 1 2 3 当前线程想打符号'<' 那就P ('<' )V ('>' ) 多个就随机
信号量实现条件变量 1 2 3 4 5 6 失败:我不能带者锁睡眠,必须要先释放锁,但释放之后不能保证原子性了
管道 之前实现通信需要共享内存并且锁定,会引发竞争和死锁;因此我们反过来,通过通信来实现共享内存
Do not communicate by sharing memory; instead, share memory by communicating. ——*Effective Go*
管道:不但能同步,还能通信
cat a.txt | wc -l Linux管道就是一种同步机制。 后一个会一边接收一边处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 package mainimport "fmt" var stream = make (chan int , 10 )const n = 4 func produce () for i := 0 ; ; i++ {"produce" , i)func consume () for {"consume" , x)func main () for i := 0 ; i < n; i++ {go produce()
哲学家吃饭 条件变量 直接上吃饭的条件,并用互斥锁保护起来
1 2 3 4 5 6 7 8 9 10 11 12 13 mutex_lock(&mutex);while (!(avail[lhs] && avail[rhs])) {false ;true ;
信号量 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 void Tphilosopher (int id) {int lhs = (N + id - 1 ) % N;int rhs = id % N;while (1 ) {printf ("T%d Got %d\n" , id, lhs + 1 );printf ("T%d Got %d\n" , id, rhs + 1 );
需求变了:如果一个人要左边两把右边一把,如何设计? 还是条件变量方便,直接改cond就行
分布与集中 集中控制而不是各自协调
1 2 3 4 5 6 7 8 9 10 11 12 13 14 void Tphilosopher (int id) {void Twaiter () {while (1 ) {if (status == EAT) { ... }if (status == DONE) { ... }
信号量可以被操作系统高效实现,避免了broadcast开销
真实世界的并发编程 背景回顾 :我们已经掌握了多种并发控制技术:自旋锁、互斥锁、条件变量、信号量。我们已经可以实现共享内存系统上的任意并发/并行计算。然而,大家也在使用这些 “底层” 并发控制时发现使用的困难。那么,真实世界的程序员是怎么实现并发程序的?
高性能计算 (注重任务分解)中的并行编程 (embarrassingly parallel 的数值计算)数据中心 (注重系统调用): (协程、Goroutine 和 channel)人工智能时代的分布式机器学习 (GPU 和 Parameter Server)
用户身边 的并发编程 (Web 和异步编程) (注重易用性)
高性能计算 massive computation 源自数值密集型科学计算任务。通常有固定的计算图
物理系统模拟
天气预报、航天、制造、能源、制药、……
大到宇宙小到量子,有模型就能模拟
矿厂 (现在不那么热了)
HPC-China 100
embarrassingly parallel :这类问题可以被分解成多个独立的子问题,每个子问题可以在不同的处理器上并行计算,而不需要进行任何进一步的同步或通信。这种问题的并行化非常简单,因为每个子问题都是相互独立的,不需要进行任何协调或同步。
通常出现在科学计算、数据分析、图像处理 等领域。例如,在图像处理中,可以将一张大图像分成多个小块,每个小块可以在不同的处理器上并行处理,最后将结果合并成一张完整的图像。在科学计算中,可以将一个大型计算任务分成多个小任务,每个小任务可以在不同的处理器上并行计算,最后将结果合并成一个完整的计算结果。
数据中心 “A network of computing and storage resources that enable the delivery of *shared* applications and data.” (CISCO)
以数据 (存储) 为中心
互联网索引与搜索
社交网络
支撑各类互联网应用
通信 (微信/QQ 群人数为什么有上限?)、支付 (支付宝)、游戏/网盘/……
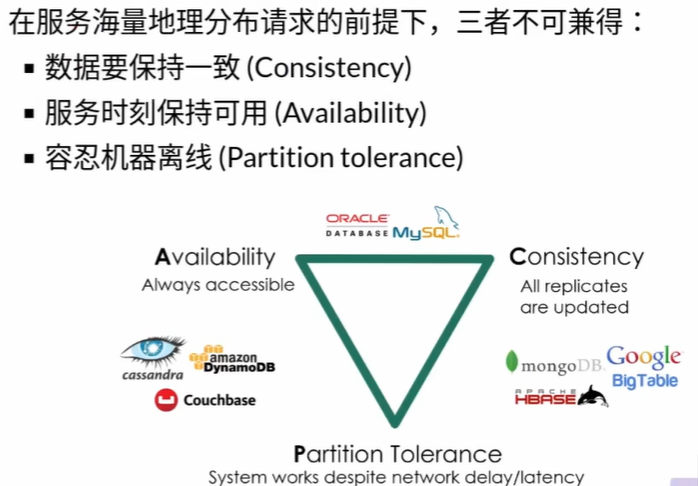
关键问题 我希望高可靠、低延时、多副本的分布式 存储 计算系统
举个例子:微信先拉黑,再发朋友圈,如果没有一致性,那么朋友圈可能被拉黑的人看到。亚马逊没一致性可能发两个快递
单机程序
假设有数千/数万个请求同时到达服务器……
线程能够实现并行处理
但远多于处理器数量的线程导致性能问题
协程(协作的线程) 和线程概念相同 (独立堆栈、共享内存) ,用户态的线程,由程序员主动控制
但 “一直执行”,直到 yield() 可以视为函数调用 , 主动放弃处理器
有编译器辅助,切换开销低
yield() 是函数调用,只需保存/恢复 “callee saved” 寄存器(函数调用保存的寄存器) RBP
线程切换需要保存/恢复全部寄存器
但等待 I/O 时,其他协程就不能运行了……
1 2 3 void T1 () { send("1" ); send("1" ); yield(); }void T2 () { send("2" ); send("2" ); yield(); }
Goroutine:概念上是线程,实现上是协程:在遇到IO且可能等待时,yield切换
如果是协程,线程sleep后计算机就停止了,但go优化成yield切换
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 package mainimport ("fmt" "time" func main () go spinner(100 * time.Millisecond)const n = 45 "\rFibonacci(%d) = %d\n" , n, fibN)func spinner (delay time.Duration) for {for _, r := range `-\|/` {"\r%c" , r)func fib (x int ) int {if x < 2 { return x }return fib(x - 1 ) + fib(x - 2 )
go之前,java已经形成了大数据处理系统的生态
人工智能时代的分布式机器学习 特点
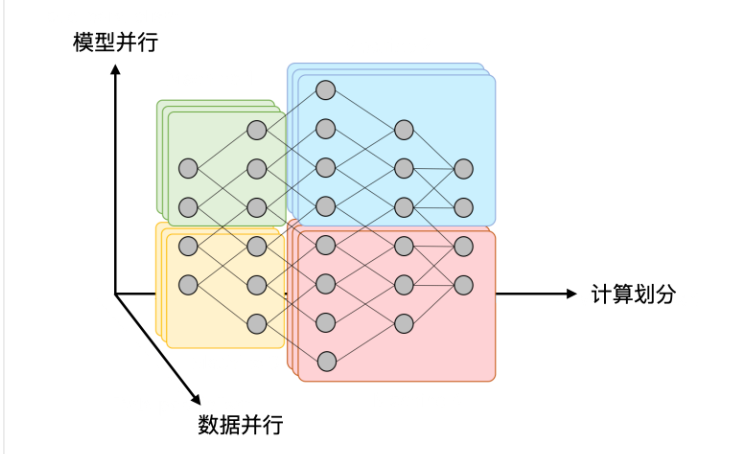
并行 数据并行:一部分数据这台机器,一部分那台 model = nn.DataParallel(model)
SIMP Single Instruction, Multiple Threads
CPU:多个cpu,但各自运行各自的,都有pc指针
GPU:一个pc控制多个执行流,独立寄存器标记线程号
SIMD
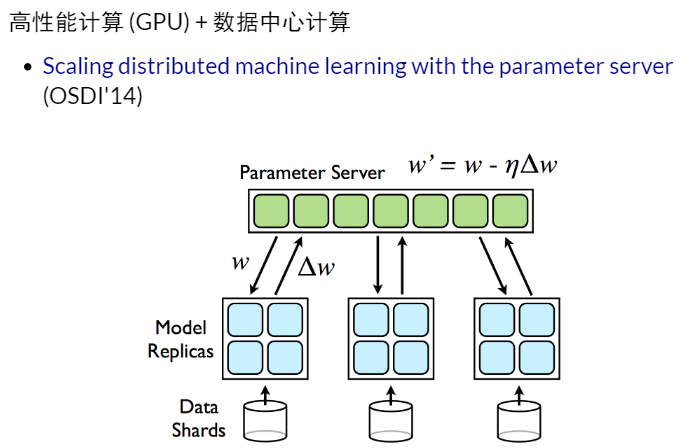
分布式机器学习
用户身边并发编程 web2.0:HTML(DOM Tree) + CSS + JS
特点:不太复杂
既没有太多计算
DOM Tree 也不至于太大 (大了人也看不过来)
DOM Tree 怎么画浏览器全帮我们搞定了
也没有太多 I/O
JS 单线程 + 事件模型
一个线程、按序执行 (run-to-complete)。无并行减少了bug 主线程执行栈 + 微任务队列
耗时的 API (Timer, Ajax, …) 调用会立即返回 + Callback
当Promise被创建时,它处于未完成的状态(pending)。当异步操作完成并且Promise成功解析(resolved)时,或者发生错误导致Promise被拒绝(rejected)时,回调函数会被添加到微任务队列中。
坏处 :$.ajax 嵌套 5 层,可维护性已经接近于零了
Promise Callback没有很好表示流程图 -> Promise
Chaining
1 2 3 4 5 6 7 loadScript ("/article/promise-chaining/one.js" )then ( script =>loadScript ("/article/promise-chaining/two.js" ) )then ( script =>loadScript ("/article/promise-chaining/three.js" ) )then ( script =>catch (err =>
Fork-join
1 2 3 4 a = new Promise ( (resolve, reject ) => { resolve ('A' ) } )new Promise ( (resolve, reject ) => { resolve ('B' ) } )new Promise ( (resolve, reject ) => { resolve ('C' ) } )Promise .all ([a, b, c]).then ( res =>console .log (res) } )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 function loadImage (url ) {return new Promise ((resolve, reject ) => {const image = new Image ();onload = () => {resolve (image); onerror = () => {reject (new Error ('Failed to load image' )); src = url;const imageUrls = ['image1.jpg' ,'image2.jpg' ,'image3.jpg' Promise .all (imageUrls.map (url =>loadImage (url)))then (images =>forEach (image =>document .body .appendChild (image); catch (error =>console .error (error);
Async-Await 一种计算图的描述语言.
通过使用 async 关键字声明一个函数为异步函数(函数会返回一个Promise对象),我们可以在函数内部使用 await 关键字来等待一个 Promise 对象的解决(resolve)
更现代、更优雅的方式来处理异步代码,与 .then 方法相比更易于理解和编写(避免嵌套)。
1 2 3 4 5 6 7 A = async () => await $.ajax ('/hello/a' )async () => await $.ajax ('/hello/b' )async () => await $.ajax ('/hello/c' )async () => await Promise .all ([A (), B (), C ()])hello ()then (window .alert )catch (res =>console .log ('fetch failed!' ) } )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 async function fetchData (try {const response = await axios.get ('https://api.example.com/data' );const data = response.data ;return data;catch (error) {console .error (error);throw new Error ('Failed to fetch data' );console .log ('Before fetchData()' );fetchData ()then (data =>console .log ('Data:' , data);catch (error =>console .error ('Error:' , error);console .log ('After fetchData()' );
并发bug
1 2 3 assert mode in [XRay, Electron]not (mode == XRay and mirror == Off)
死锁 表现明显:程序停止了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 lock(&lk);void Tphilosopher () {
Mutual-exclusion - 一张校园卡只能被一个人拥有
Wait-for - 一个人等其他校园卡时,不会释放已有的校园卡
No-preemption - 不能抢夺他人的校园卡
Circular-chain - 形成校园卡的循环等待关系
处理方法 :
预防死锁 (一次性分配资源; 允许抢占; Locker order规定获取锁的顺序,必须从小到大(获得编号最大的进程能运行))避免死锁 (银行家 :在一次分配完后检查是否有安全序列能实现全部运行)监测死锁 (资源分配图 ,分配完有没有环)解除死锁 (资源剥夺、回滚进程、终止进程)
数据竞争 多个线程对同一内存进行读写,先写还是先读产生的结果不同。山寨支付宝判断并修改余额
先来先写,多个memory,无法定义谁先来,所以需要避免data race。上锁
不同的线程 同时访问同一内存 ,且至少有一个是写
“内存” 可以是地址空间中的任何内存
“访问” 可以是任何代码
可能发生在你的代码里
可以发生在框架代码里
可能是一行你没有读到过的汇编代码
可能时一条 ret 指令
原子性违反 调查100个BUGs,97% 的非死锁并发 bug 都是原子性 (山寨支付宝)或顺序错误
应对并发bug 假设程序员会花式犯错
编译器 :只管翻译代码,不管需求含义
怎么才能编写出 “正确” (符合 specification) 的程序?
防御性编程 机器永远是对的,代码始终是错的
防御性编程:把可能不对的情况都检查一遍。assert 大型项目很需要
Peterson 算法中的临界区计数器
二叉树的旋转
assert(p->parent->left == p || p->parent->right == p);
AA-Deadlock 的检查
if (holding(&lk)) panic();xv6 spinlock 实现示例
自动运行时检查 Lockdep死锁检测 Lockdep :死锁的检查。linux内核
每一个锁有一个唯一的site(线程文件行号),上锁解锁日志记录下该site。通过查看所有日志有没有环
1 2 3 void lock (lock_t *lk) {printf ("LOCK %s\n" , lk->site);
data race检测 ThreadSanitizer:运行时的数据竞争检查.编译时实现
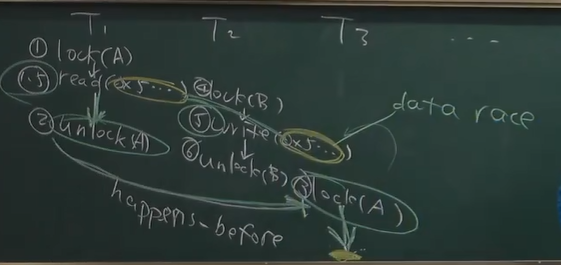
两个进程同时读写同一内存,有没有happens-before关系,没有就存在data race (T1-5 T2-5)
rule of thumb
不实现 “完整” 的检查
允许存在误报/漏报
但实现简单、非常有用
canary “牺牲” 一些内存单元,来预警 memory error 的发生。栈空间多分配一些canary空间作为保护,值被修改了就异常了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #define MAGIC 0x55555555 #define BOTTOM (STK_SZ / sizeof(u32) - 1) struct stack {char data[STK_SZ]; };void canary_init (struct stack *s) {for (int i = 0 ; i < CANARY_SZ; i++)void canary_check (struct stack *s) {for (int i = 0 ; i < CANARY_SZ; i++) {"underflow" );"overflow" );
msvc 中 debug mode 的 guard/fence/canary
未初始化栈: 0xcccccccc 烫
未初始化堆: 0xcdcdcdcd 屯
对象头尾: 0xfdfdfdfd
低配lockdep 统计自旋的次数,超过某个值肯定不正常
1 2 3 4 5 6 int count = 0 ;while (xchg(&lk, LOCKED) == LOCKED) {if (count++ > SPIN_LIMIT) {"Spin limit exceeded @ %s:%d\n" , __FILE__, __LINE__);
低配AddressSanitizer 并发分配内存时,分配完标记一个颜色
1 2 3 4 5 6 7 8 9 10 11 for (int i = 0 ; (i + 1 ) * sizeof (u32) <= size; i++) {"double-allocation" );for (int i = 0 ; (i + 1 ) * sizeof (u32) <= alloc_size(ptr); i++) {0 , "double-free" );0 ;
多处理器与中断 处理器如何实现多线程?中断
本讲内容 :操作系统内核实现。
多处理器和中断
AbstractMachine API
50 行实现嵌入式操作系统
多处理器的状态机模型:状态为内存和每一个状态。执行为任选 一个cpu
如果死循环某个CPU就会卡死,而为什么我们写的死循环程序不会卡死电脑?
中断 下降沿触发的一根线。IF寄存器(interrupter flag) 决定是否响应中断(操作系统可以修改该值)
x86 Family
询问中断控制器获得中断号 n
保存 CS, RIP, RFLAGS, SS, RSP 到堆栈
跳转到 IDT[n] 指定的地址,并设置处理器状态 (例如关闭中断)
关中断实现了 “stop the world” ,尝试asm volatile ("cli")被操作系统检测到,会直接报错
上下文保存 所有线程都有一块内存用来保存自己的现场
1 2 3 4 5 6 7 8 struct Context {
中断处理:保存当前的ctx,并返回运行在该cpu上的另一个线程的上下文
tasks[n]是内存中所有线程的状态。next指针把所有状态串联currents[MAX_CPU] 是每一个cpu当前的状态,都指向tasks中的某一个current=currents[cpu_current()]是当前cpu状态指针,current->context = ctx保存现场到内存
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 Task *currents[MAX_CPU];#define current currents[cpu_current()] on_interrupt (Event ev, Context *ctx) {if (!current) {0 ]; else {do {while (!on_this_cpu(current)); return current->context;
50行操作系统 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 #include <am.h> #include <klib.h> #include <klib-macros.h> #define MAX_CPU 8 typedef union task {struct {const char *name;union task *next ;void (*entry)(void *);uint8_t stack [8192 ];#define current currents[cpu_current()] int locked = 0 ; void lock () { while (atomic_xchg (&locked, 1 )); }void unlock () { atomic_xchg (&locked, 0 ); }#include "tasks.h" on_interrupt (Event ev, Context *ctx) {if (!current) current = &tasks[0 ]; else current->context = ctx; do {while ((current - tasks) % cpu_count() != cpu_current());return current->context; void mp_entry () {int main () {for (int i = 0 ; i < LENGTH(tasks); i++) {stack = (Area) { &task->context + 1 , task + 1 }; stack , task->entry, (void *)task->name); 1 ) % LENGTH(tasks)];
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 void func (void *arg) {while (1 ) {printf ("Thread-%s on CPU #%d\n" , arg, cpu_current());for (int volatile i = 0 ; i < 100000 ; i++) ;"A" , .entry = func },"B" , .entry = func },"C" , .entry = func },"D" , .entry = func },"E" , .entry = func },
内核 fork execv exit
应用程序 = 纯粹计算(Python 代码) + syscall; 状态机
操作系统 = syscall实现:重要的三个系统调用
fork: 对当前状态机状态进行完整复制
execve: 将当前状态机状态重置为某个可执行文件描述的状态机
exit: 销毁当前状态机
fork fork: 完全 复制一份当前的状态 (内存、寄存器现场),相当于创建了一个新的进程,返回子进程号。unix唯一方法
因为状态机是复制的,因此总能找到 “父子关系”
1 2 3 4 5 6 7 8 9 10 systemd-+-ModemManager---2 *[{ModemManager}]-NetworkManager ---2 *[{NetworkManager}]-accounts -daemon---2 *[{accounts-daemon}]-at -spi-bus-laun-+-dbus-daemon`-3 *[{at -spi-bus-laun}]-at -spi2-registr---2 *[{at -spi2-registr}]-atd -avahi -daemon---avahi-daemon-colord ---2 *[{colord}]
1个变成了4个。fork出来的子进程也会执行下面的fork(), 除了x不一样其他都一样
1 2 3 pid_t x = fork();pid_t y = fork();printf ("%d %d\n" , x, y);
打印了多少个?
1 2 3 4 5 6 7 for (int i = 0 ; i < 2 ; i++) {printf ("Hello\n" );6 个8 个 因为如果输入到管道,print的信息会放到缓存中,被同时复制
execv execv :
将当前进程重置 成一个可执行文件描述状态机的初始状态
唯一能够执行程序的系统调用,一切程序的起点 (fork是父进程调用的)
传入参数 和环境变量
1 2 3 4 5 int execve (const char *filename, char * const argv[], char * const envp[]) ;execve (" /usr/bin/ls" , ["ls" , "-al" ], 0x7ffeaabcda88 ) = 0
环境变量,默认继承父进程
使用env命令查看
PATH: 可执行文件搜索路径PWD: 当前路径HOME: home 目录DISPLAY: 图形输出PS1: shell 的提示符
export: 告诉 shell 在创建子进程时设置环境变量
小技巧:export ARCH=x86_64-qemu 或 export ARCH=native
strace gcc gcc会先去找可执行的as汇编器程序,去path里找,所以会输出:
1 2 3 4 [pid 28369 ] execve("/usr/local/sbin/as" , ["as" , "--64" , ...pid 28369 ] execve("/usr/local/bin/as" , ["as" , "--64" , ...pid 28369 ] execve("/usr/sbin/as" , ["as" , "--64" , ...pid 28369 ] execve("/usr/bin/as" , ["as" , "--64" , ..
exit 1 2 3 void _exit(int status)
exit 的几种写法 (它们是不同)
exit(0) stdlib.h中声明的 libc 函数
_exit(0) glibc 的 syscall wrapper
执行 “exit_group” 系统调用终止整个进程 (所有线程)
不会调用 atexit
syscall(SYS_exit, 0)
执行 “exit” 系统调用终止当前线程
不会调用 atexit
shell中运行./a.out:
Shell解析命令行输入,发现./a.out是一个可执行文件。
Shell调用fork()系统调用,创建一个新的子进程。子进程复制父进程的所有资源和代码段。
子进程调用execve()系统调用,加载并执行a.out可执行文件。
如果可执行文件需要进行系统调用,例如读取文件或写入文件,它会使用相应的系统调用,如open()、read()、write()等。
当可执行文件执行完毕或调用了exit()系统调用来终止进程时,进程会返回到Shell。
shell wail()等待子进程(如果后台运行&就不会等待)
Shell本身也是一个进程/bin/bash,初始状态读取配置文件~/.bashrc。输入:
执行内部命令(例如cd或echo)
执行系统命令(例如ls或grep)(本质上也是可执行文件)
可执行文件
Linux中的init
Linux 操作系统
Linux 系统启动和 initramfs
Linux 应用世界的构建
just for fun
1 2 Hello, everybody out there using minix – I’m doing a (free) operating system (just a hobby, won’t be big and professional like gnu) for 386 (486 ) AT clones. This has been brewing since April, and is starting to get ready.21 岁)
Minix: 完全用于教学的真实操作系统 1987。Andrew Tanenbaum。 Linux 的起点
Kernel
加载第一个进程
相当于在操作系统中 “放置一个位于初始状态的状态机” **init ** systemd
Single user model (高权限)
包含一些进程可操纵的操作系统对象
除此之外 “什么也没有”
Linux Kernel 系统调用上的发行版和应用生态
第一个状态机 1.我们可以控制init程序是谁,比如最简单的helloword。当helloword 退出后,也就是杀死最后一个进程,Kernel panic
1 2 3 4 5 6 7 8 9 10 11 INIT := /init"console=ttyS0 quiet rdinit=$(INIT) "
2.改回启动Init程序,其中busybox 是一个程序,但包含很多文件 5000行 busybox vi busybox sh,因此我们的init程序就可以使用命令了,再通过软连接就可以直接执行了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #!/bin/busybox sh $BB echo -e "\033[31mHello, OS World\033[0m" $BB poweroff -f$BB shfor cmd in $($BB --list); do $BB ln -s $BB /bin/$cmd done mkdir -p /tmpmkdir -p /proc && mount -t proc none /procmkdir -p /sys && mount -t sysfs none /sysmknod /dev/tty c 4 1
至此我们通过init启动了一个独立sh,sh中可以执行我们的指令
1 2 3 4 5 6 如果我们放一个vi & 在后台sh ---pstreevi
其他工作 只是一个内存里的小文件系统
我们 “看到” 的都是被 init 创造出来的
加载剩余必要的驱动程序,例如网卡
根据 fstab 中的信息挂载文件系统,例如网络驱动器
将根文件系统和控制权移交pivot_root给另一个程序,例如 systemd
进程的地址空间 进程的状态由 (M,R) 组成,R为体系结构中决定的,M的具体实现?
地址空间内容 pmap pid 读取/proc/pid/maps strace跟踪可以证明
1 2 3 4 5 6 7 8 9 10 11 12 13
如果是动态链接呢?有一个加载的过程,在main之前把动态链接库(如libc.so.6)加载到地址空间中
系统调用需要陷入内核,但有些简单的(只读的)可以不用陷入内核执行
vvar :Virtual Variable 存储内核和用户空间之间共享的变量。这些变量包括与时间相关的信息、线程特定的数据等。vdso:取这些信息的代码,不进入内核的系统调用
空间的管理 程序空间是变化的:操作系统应该提供一个修改进程地址空间的系统调用
1 2 3 4 5 6 7 8 void *mmap (void *addr, size_t length, int prot, int flags, int fd, off_t offset) ;int munmap (void *addr, size_t length) ;int mprotect (void *addr, size_t length, int prot) ;
分配8G(可以超过内存)会直接分配,使用时才加入内存发生缺页中断
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #include <unistd.h> #include <stdint.h> #include <stdio.h> #include <stdlib.h> #include <sys/mman.h> #define GiB * (1024LL * 1024 * 1024) int main () {volatile uint8_t *p = mmap(NULL , 8 GiB, PROT_READ | PROT_WRITE, MAP_ANONYMOUS | MAP_PRIVATE, -1 , 0 );printf ("mmap: %lx\n" , (uintptr_t )p);if ((intptr_t )p == -1 ) {"cannot map" );exit (1 );2 GiB) = 1 ;4 GiB) = 2 ;7 GiB) = 3 ;printf ("Read get: %d\n" , *(p + 4 GiB));printf ("Read get: %d\n" , *(p + 6 GiB));printf ("Read get: %d\n" , *(p + 7 GiB));
Memory-Mapped File : 一致性:什么时候将修改写入磁盘?多进程如何共享?
入侵地址空间 入侵地址空间就是可以任意操控其他进程
调试器 (gdb)
Profiler (perf)
金手指 物理劫持
金山游侠 入侵地址空间,修改金钱 、生命 属性
任何操作系统肯定提供了gdb
原理为pmap读取内存的内容并修改
代码扫描所有地址,找出金钱为3000的,消耗一些后找出价钱为2700的,这些地址值都修改就可以修改金钱
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 int main (int argc, char *argv[]) {long val;char buf[64 ];struct game game ;if (load_game(&game, argv[1 ]) < 0 ) {goto release;while (!feof(stdin )) {printf ("(%s %d) " , game.name, game.pid);if (scanf ("%s" , buf) <= 0 ) goto release;switch (buf[0 ]) {case 'q' : goto release; break ;case 'b' : scanf ("%ld" , &val); game.bits = val; reset(&game); break ;case 's' : scanf ("%ld" , &val); scan(&game, val); break ;case 'w' : scanf ("%ld" , &val); overwrite(&game, val); break ;case 'r' : reset(&game); break ;return 0 ;
按键精灵 大量重复固定任务。这个简单,就是给进程发送键盘/鼠标事件
做个驱动 (可编程键盘/鼠标)
利用操作系统/窗口管理器提供的 API
变速齿轮 跳转游戏逻辑更新速度
程序只是状态机,除了syscall无法感知时间。修改syscall返回值就可以欺骗程序。
代码注入 1 2 3 4 5 6 1000 / FPS); if (hp < 0 ) game_over();






 两个线程画图
两个线程画图