redis应用及原理
视频:https://www.bilibili.com/video/BV1cr4y1671t
链接https://pan.baidu.com/s/1189u6u4icQYHg_9_7ovWmA?pwd=eh11
提取码:eh11
社交类项目
- 短信登陆
- 商户查询缓存:缓存雪崩 穿透 击穿
- 博客
- 优惠券秒杀:计算器 lua 分布式锁 队列
- 好友关注:set集合
项目搭建
前后端分离
start nginx.exe
数据库表
- user
- user_info
- shop
- shop_type
- blog
- follow
- voucher
- voucher_order
登录
短信登录:验证码,用户信息都是直接存入session
是否登录:session中不用唯一,而redis是共享的需要唯一
1.查看session中有没有某个key(固定,不用返回,如”user”,“code”) 2.查看redis中有没有携带的这个token(动态 返回,UUID或者JWT)
配置拦截器,取出User的同时加入到threadlocal中,以后获得用户 UserHolder.getUser()
1 | |
去除敏感信息:创建一个小的类,然后copy信息
1 | |
redis:验证码、用户信息都存入redis中。
- 用户信息用hash(
BeanUtil.beanToMap),添加有效期,登录添加登陆后更新有效期 - 拦截器类没有交给spring,不能注入redis,因此添加一个成员变量
- StringRedisTemplate 需要保证hash中key value 都是string。所以beantomap时需要对类型进行转化
- 问题:有的请求没有拦截,导致没有刷新。再添加一个。一个全部刷新添加、一个拦截
商户查询缓存
缓存:浏览器缓存 redis缓存 数据库缓存 索引
问题:数据一致性
shop、shop_type添加缓存
缓存更新策略
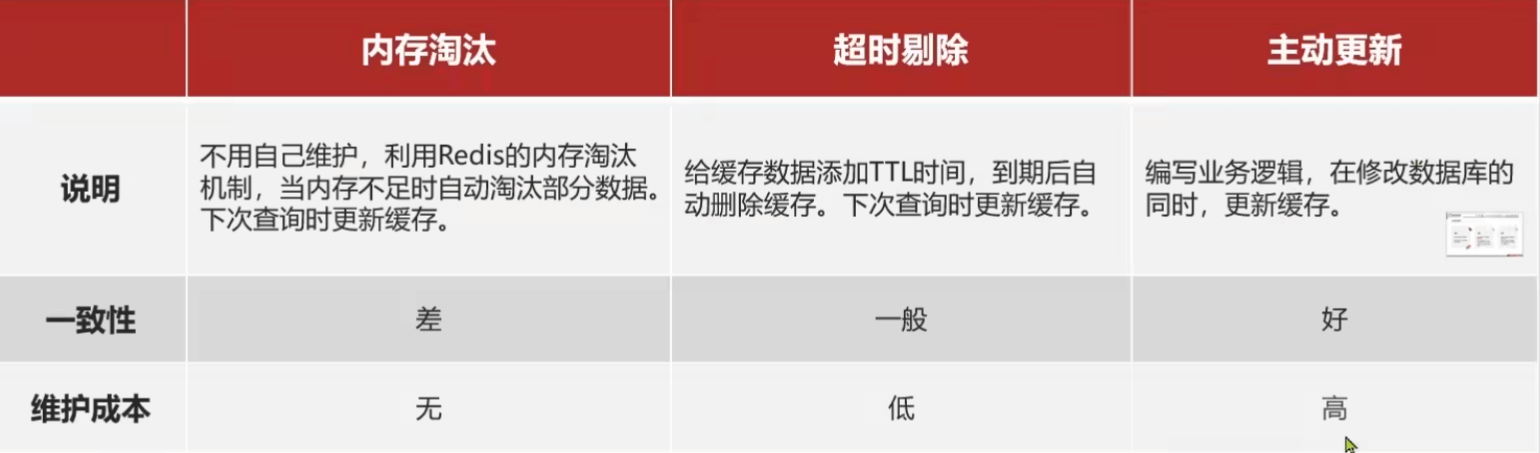
- 低一致性的数据:内存淘汰
- 高一致性:主动更新+超时
主动更新
- 更新数据库的同时更新缓存
- 更新还是删除缓存:删除比较一致性好。防止多次更新
- 如何保证同时成功失败:单体:事务;分布式:TCC分布式事务
- 先更新数据库还是缓存? 都可能有问题
- 先删缓存:A删完缓存来了查询B,B查询完成后写入脏数据到redis
- 先数据库:出问题概率更低(B来的时候没有缓存,B读取数据库,A更新数据并删除redis,B写脏数据到redis),但A写数据库的过程,B查的都是旧数据
- 缓存、数据库整合成一个服务
- 先更新缓存、异步更新到数据库

所以:查询商品:添加超时,并且更新后删除缓存
此外:还可以直接加读写锁,更新时直接加写锁。读取时读redis加读锁,读数据库并更新加写锁 并发251集
1 | |
缓存穿透
Redis和数据库都不存在的数据,不停的请求每次都会打到数据库上。
- 缓存空对象:直接缓存一个空值“”,需要添加TTL。可能照成短期的不一致。 代码写法
- 布隆过滤器:添加一层判断是否纯在。内存少 但实现复杂
此外还有:数据格式校验、用户权限校验、热点参数限流 cloud
缓存雪崩
同时大量缓存失效或者宕机。
- TTL可以添加随机
- Redis集群
- 降级限流 确保数据库安全
- 多级缓存
缓存击穿
查询数据库但在没有构建出缓存的这段时间,同时大量重建 击穿了数据库。
热点key(高并发),并且重新构建业务比较复杂(查询数据库的时间很长,这个时间大家都来查了)。
- 互斥锁:加一个查询锁。没有锁的休息下重试。可能死锁 (锁的可能会有问题:加版本 加lua脚本 见秒杀.md)
- 逻辑过期:永不过期防止查不到,并且添加一个逻辑过期时间字段,如果逻辑过期了,就返回旧值并异步更新一下(锁)
互斥锁
setIfAbsent实现
1 | |
1 | |
逻辑过期
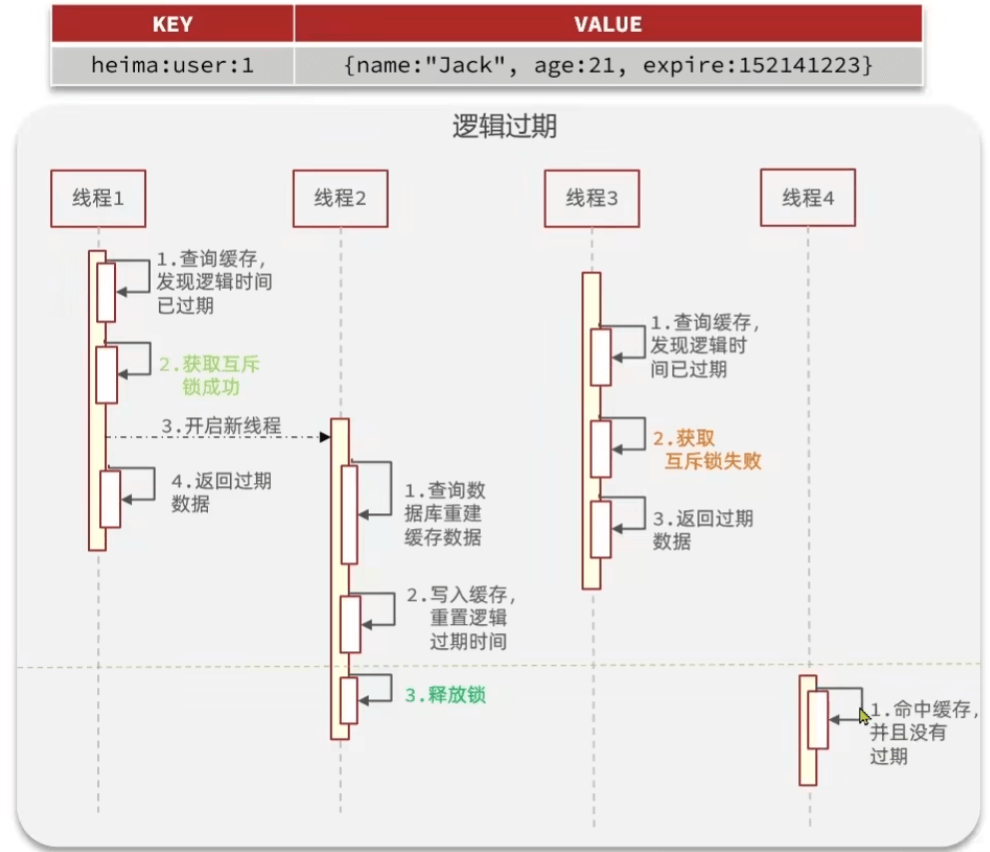
RedisData: 包装类保存时间和数据
1 | |
- 先预热下数据,该数据逻辑上过期了
- redis没有 直接返回
- 有 再看下时间要不要重建
- 最后修改下数据库,1m发起1000次请求,重建延时为200ms,可以看到后面的数据可以查到真的,前面是脏的
没有doublecheck但数据库依旧只查询了一次,原因未知
1 | |
工具类
- 对象->string类型 TTL
- 对象->string类型 逻辑TTL
- queryWithPassThrough 空字符串防止缓存穿透
pre id Class-> 对象 null防止缓存穿透,Function<ID, R> dbFallback, Long time, TimeUnit unit重建
- queryWithLogicalExpire
pre id Class-> 对象Function<ID, R> dbFallback, Long time, TimeUnit unit重建
- queryWithMutex
秒杀
代金券就是商品
tb_voucher_order:订单表
ID生成器
id没有使用自增:规律性明显、表拆分后自增会冲突
全局id生成器:唯一、高可用(集群)、高性能、递增、安全
时间戳用的秒,序列号为一天的自增长(需要一个prefix):方便统计计量、控制大小

1 | |
优惠券下单
同样两个表,普通表和秒杀表
普通表有基本信息(type区分普通还是秒杀),秒杀表扩展 库存 时间。voucher类中有额外字段,用@TableField(exist = false)标识。
添加优惠券:一个接口 同时添加两个表。
超卖
- 悲观锁:直接一个
redis.setnx锁 - 乐观锁:更新数据时,成功率很低
- 添加版本号,修改前需要查版本号
set stock = stock -1 where version = initVersion - CAS(compare and set):库存本来就是版本号,
where stock = initStock,但这样会导致成功率低; ==修改为==:where stock > 0也就是秒杀项目的基础用法
- 添加版本号,修改前需要查版本号
一人一单
- 唯一索引
- 加锁: 单机情况
- sychronized:锁定函数,阻塞的
- 缩小范围,提取一人一单开始锁定,并且通过userid标识
synchronized (userId.toString().intern()) - 小函数添加事务,提取出真的的代理对象调用小函数。引入依赖、添加注解
1 | |
问题:微服务项目,不同服务中的普通线程锁就失败了。无法跨进程
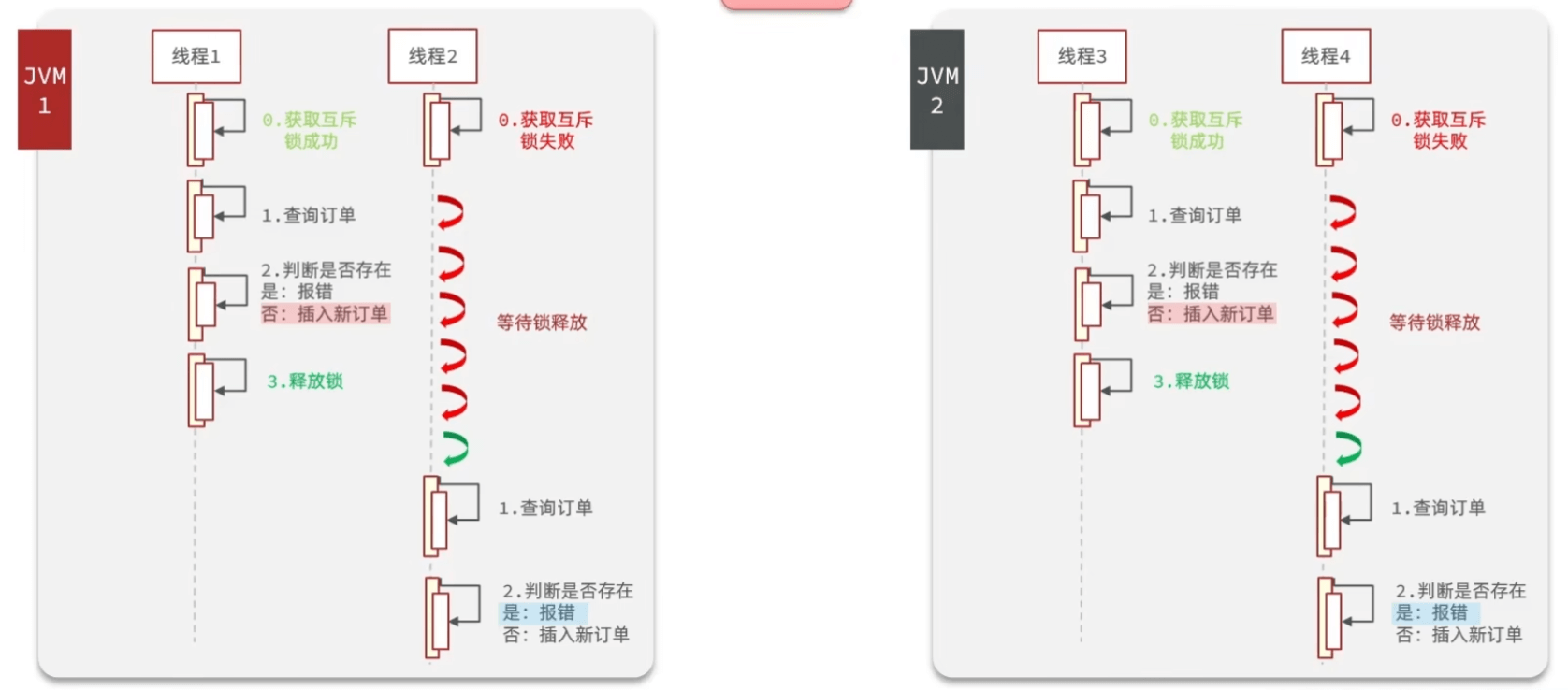
分布式锁
普通set del => 加超时 => 加版本 => 加Lua
set lock thread1 NX EX 10
添加SimpleRedisLock类专门处理锁,需要传入name 和 redis
1 | |
lua
数组下标从1开始,需要指明key的数量
1 | |
脚本定义和调用
1 | |
存在问题
- 不可重用 A拿了锁调用B,B也需要锁
- 不可重试,只try一次
- 超时释放 和 业务时间冲突
- 主从一致性,主节点宕机后存在还能没同步到从节点
Redisson
基本使用
1.首先,在 pom.xml 文件中添加 Redisson 的依赖:
1 | |
2.在 Spring Boot 应用中,使用 Redisson 的方式通常是通过创建一个 RedissonClient 实例与 Redis 进行通信。RedissonClient 可以根据 Redis 的不同部署方式来进行配置。下面是一个基于单节点的 Redisson 配置示例:
1 | |
3.执行
1 | |
可重用
Redisson自带可重用,可以打断点看redis中
实现原理:添加一个计数,如果是线程值相同,那么说明是同一个线程,可以获取锁,并数量+1
hash结构实现”: lock:order ( uuid+thread : count)

释放锁时,先减,减到零再释放锁
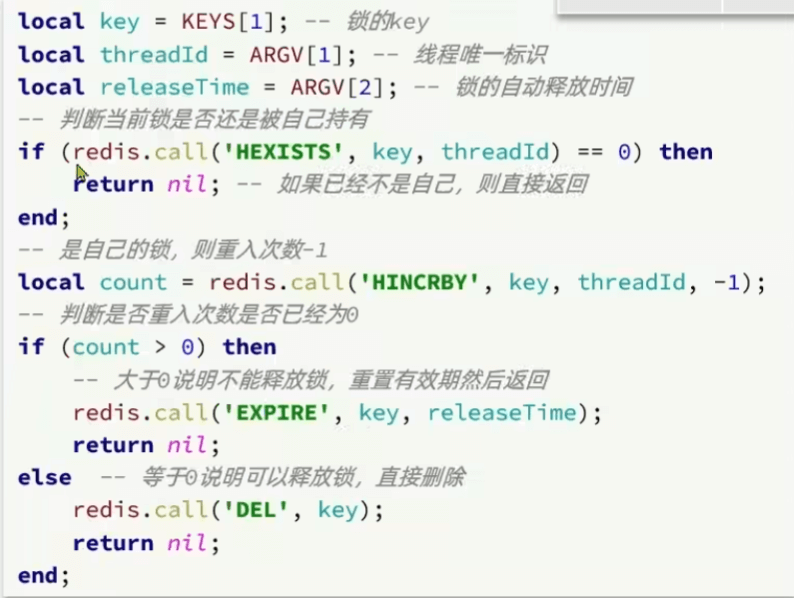
重试
- 获取锁成功直接返回,失败会返回过期时间
- 获取锁失败,订阅别人的释放tread信号
- 等到后,再去while true尝试锁,通过信号量
主从一致性
开多台主机,重用保证主机的可靠性。相当于把redis主从机都做了复制
异步
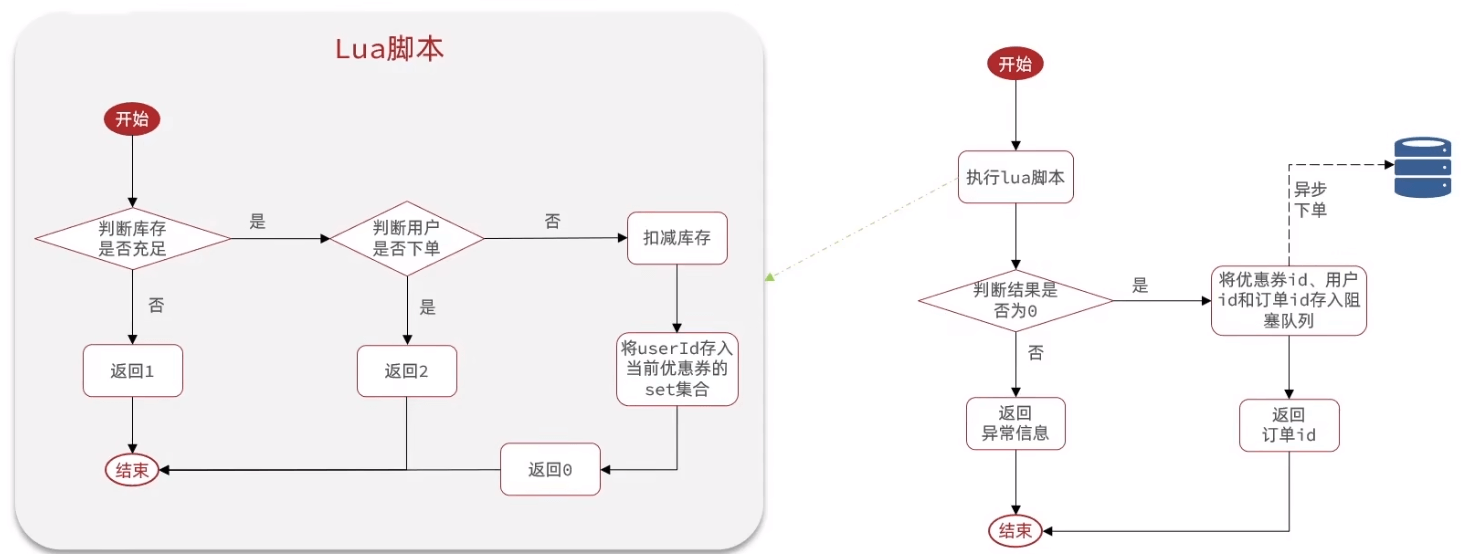
阻塞队列
jvm中的服务,受到本地性能影响;并且数据可能丢失
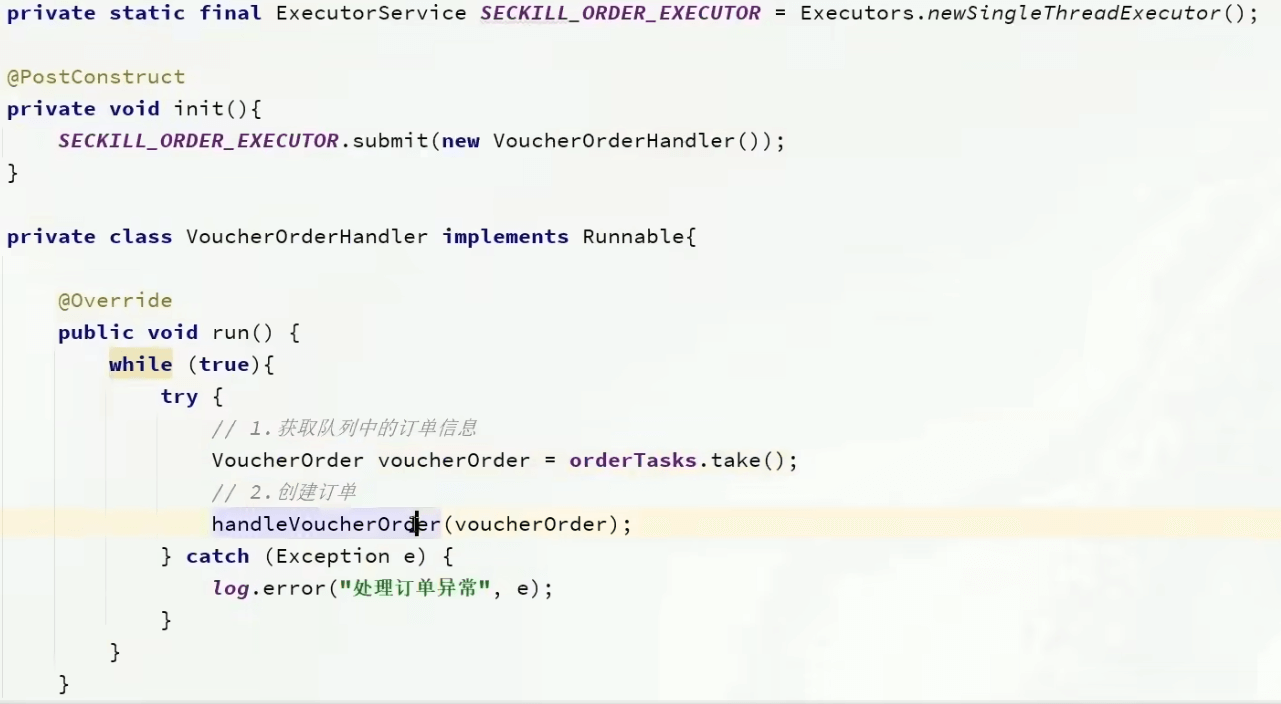
- 添加任务:往队列中add
- 一个BlockQueue以及一个线程池,线程池中一个线程任务为不停的从队列中拿出任务并执行,这样就实现了异步
消息队列
List:List模拟消息队列,单消费者
1
通过BRPOP 实现阻塞的提取任务PubSub:点对点的消息队列,多生产多个消费者,可以实现通过通配符实现订阅
1
2
3
4subscribe(channel)
psubscribe(pattern)
publish(channel)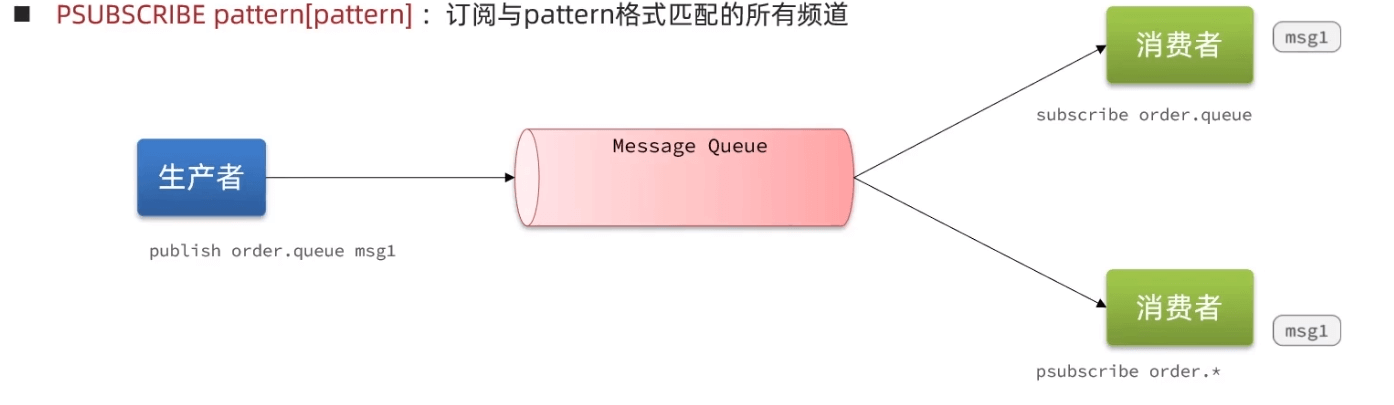
消息堆积有上限,消息可能丢失(如果没有人接受的)
Stream:比较完善的模型,是一种新的数据类型
1
2
3
4
5XADD key k v
# 创建名为users的队列,并向其中发送一个消息,内容是: {name= jack , age=21},并且使用Redis自动生成ID
XADD users * name jack age 21
XREAD COUNT 1 STREAM key 0(从哪个消息开始,$为最新) BLOCK 阻塞 读完不删除消费者组:一个组有多个消费者,共同消费;消息存在标识代表是否处理过,已读未确认的加入pending


XACK s1 g1 id
分布式缓存
- 数据丢失 主从 持久化
- 并发能力 读写分离
- 故障恢复 哨兵检测监控状态
- 存储能力 单节点数据太大了,分片集群
持久化
为了安全性使用AOF(1s刷盘),RDB(频率不高、空间小)定期手动进行备份
RDB
RDB Redis Database Backup file 快照(snapshot)持久化方式
保存到磁盘,如果docker启动还需要挂载
1 | |
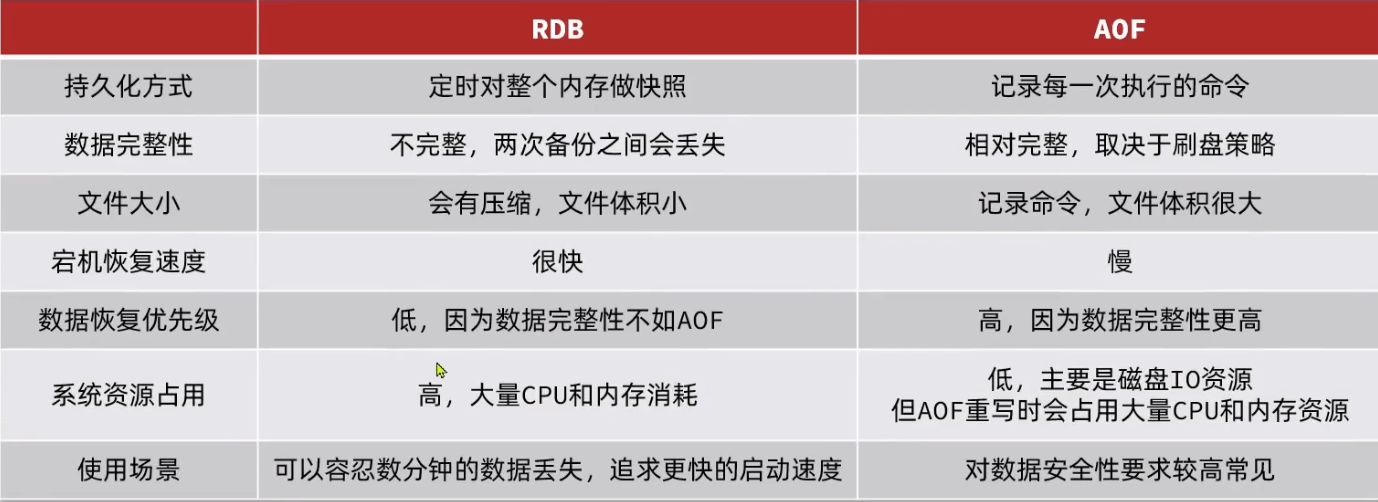
bgsave中fork过程是需要耗时的,需要拷贝内存。实际上是拷贝页表。
如果在save过程写请求进来,会修改一个副本内存
AOF
(Append-Only File) 记录下命令,优先使用AOF恢复
1 | |
同样会在开始前加载,结束后保存
但:同一个key实际上前面的操作没有意义,bgrewriteaof 异步只保留最后一次
1 | |
主从
搭建
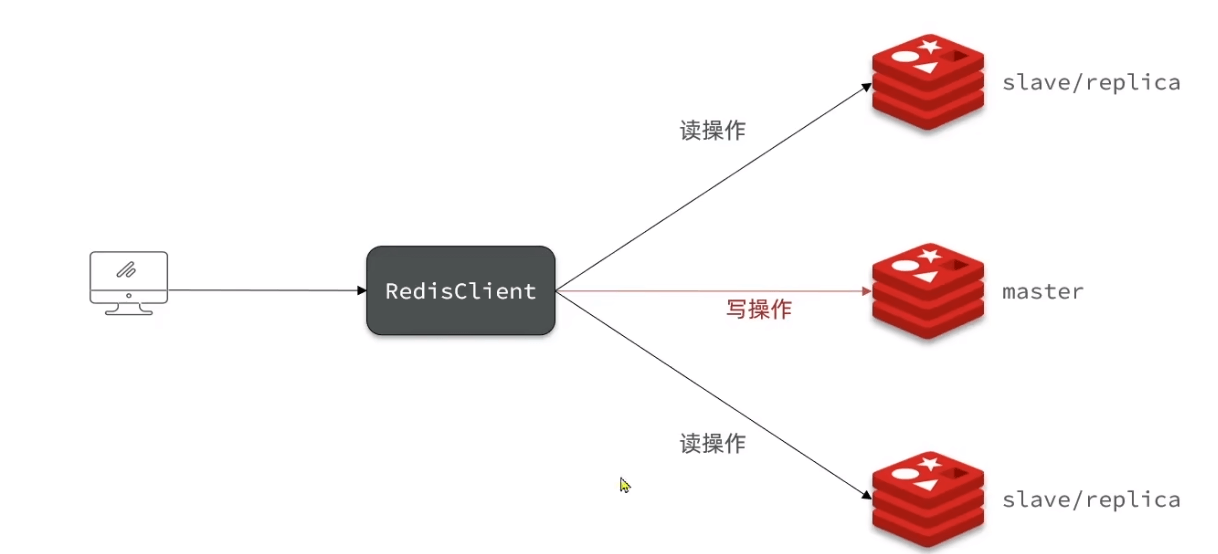
- 开启RDB 关闭AOF
- 拷贝三个配置文件,需要不同的port和dir文件路径 master关闭bind
1 | |
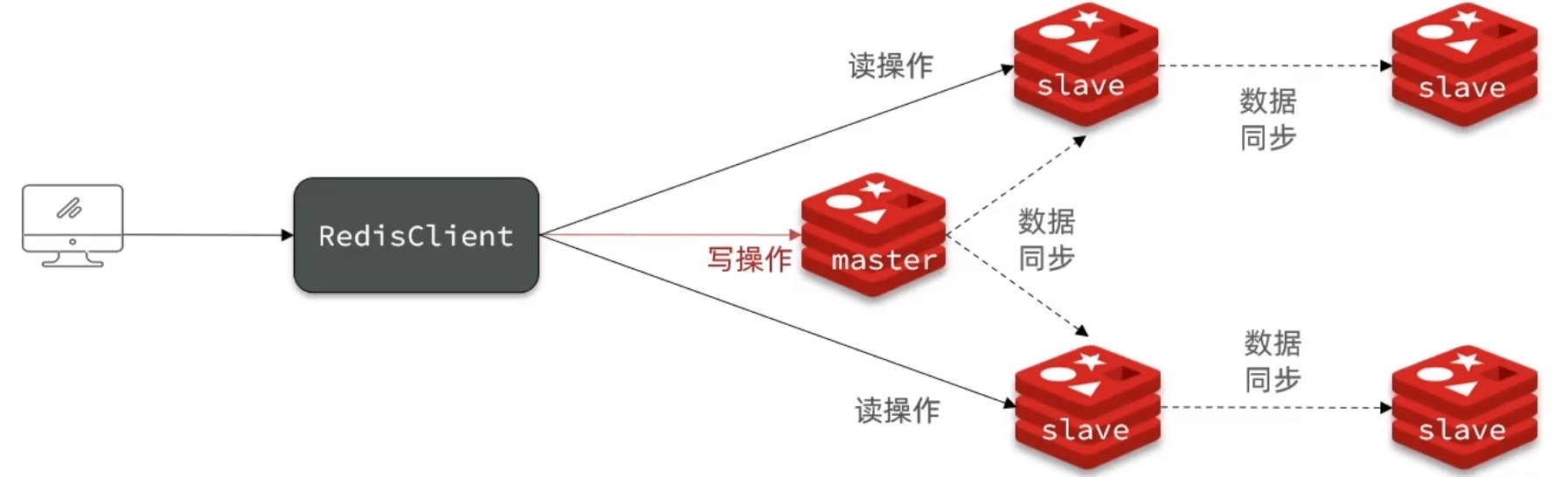
至此master可读可写,slave只可以读,master写时会同步到从
原理
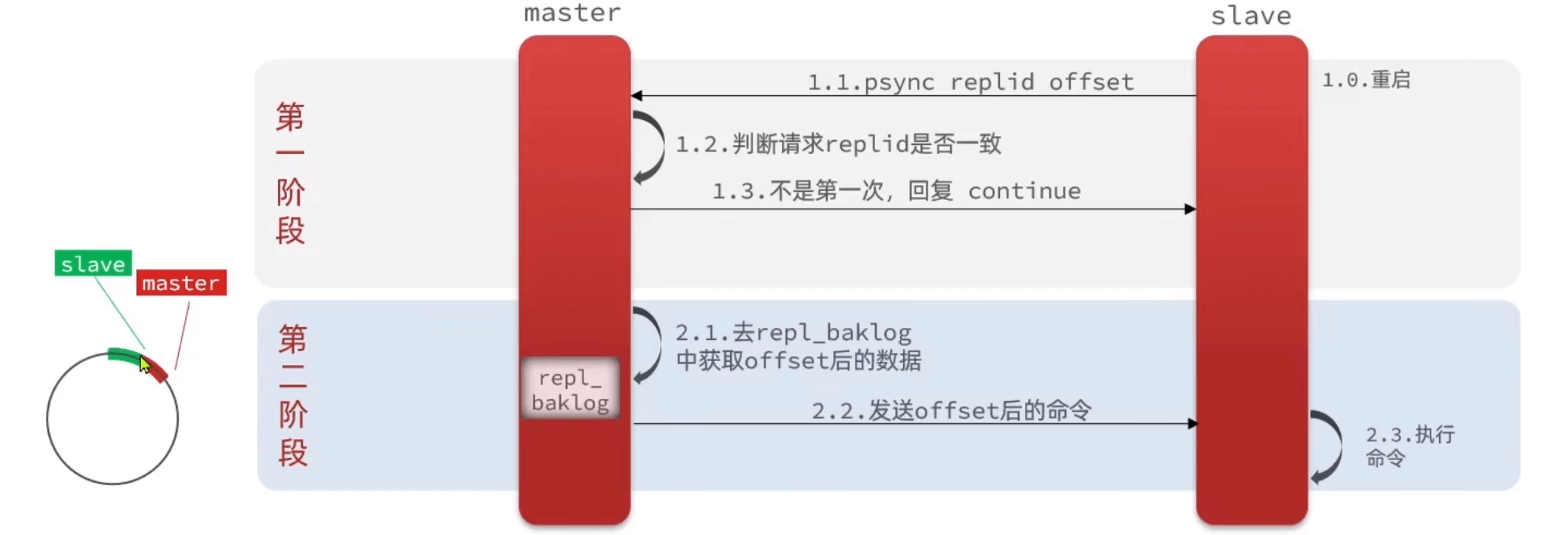
基于RDB
- 第一次判断:master有唯一replid,是数据集的标记,不一致说明是第一次
- 是否落后:offset 偏移量代表数据,offset不一致说明数据落后了
全量同步
第一次:全量同步;如果尝试做增量同步失败后
增量同步
根据offset,发回repl_backlog差距
log是一个环形数组,如果差距写满了,就需要全量同步
其他优化
- repl-diskless-sync yes # 直接网络发送而不是先磁盘
- 适当提高repl_backlog大小
- 主从从结构
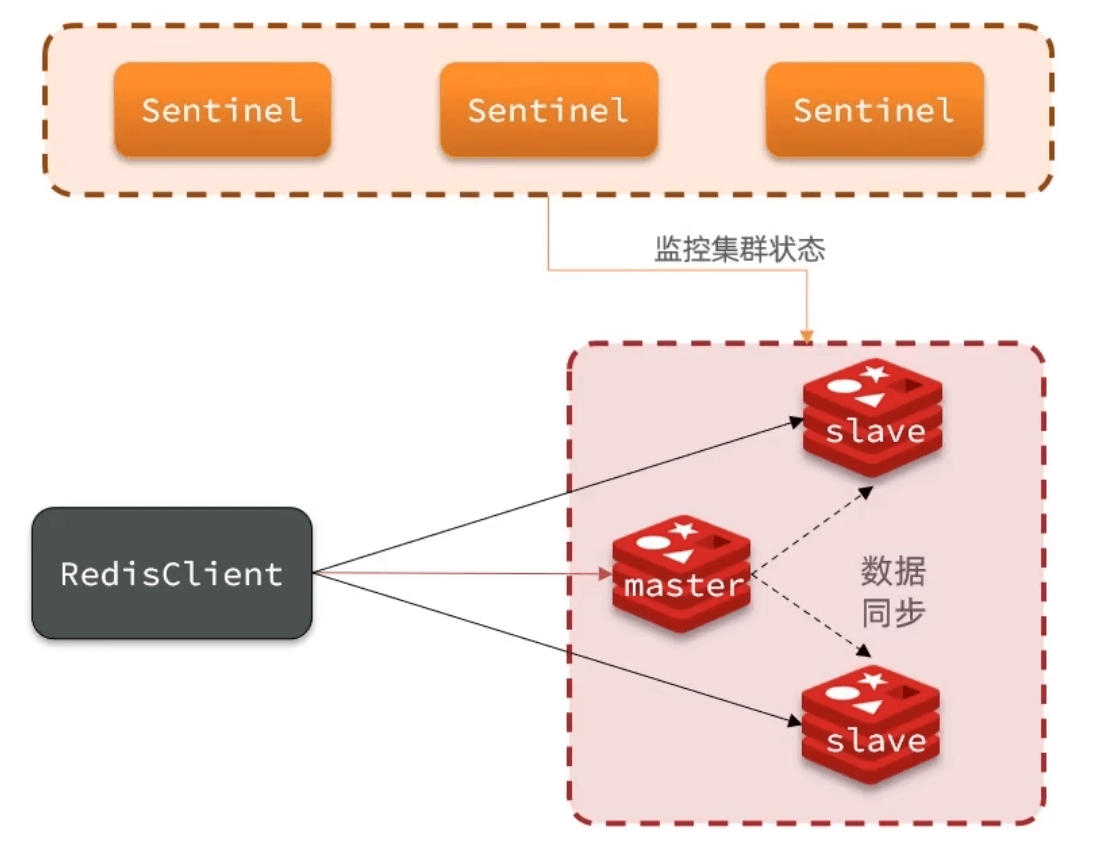
故障恢复-哨兵
哨兵也是一个小集群
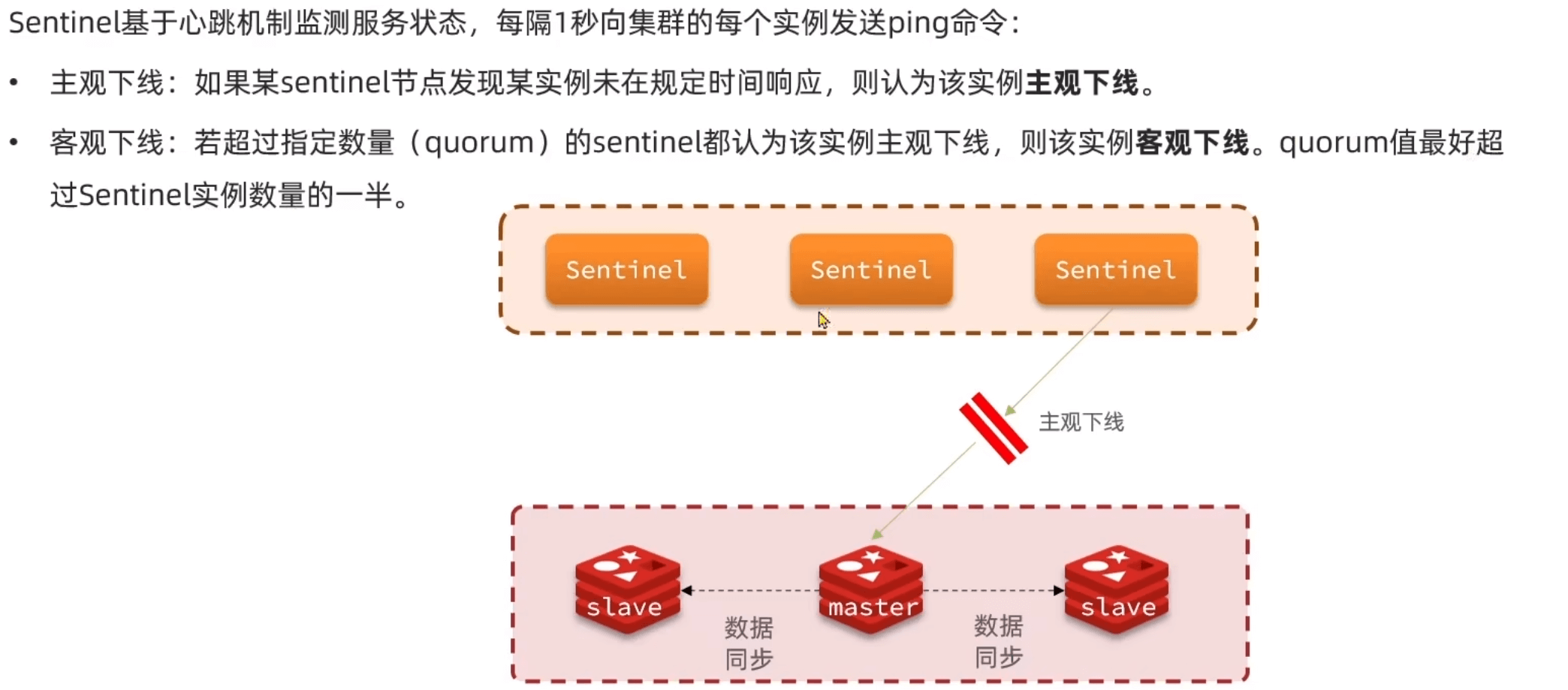
作用和原理
- master宕机,立马更换一个
- 与master断开时间小于配置
- 再根据优先级
- 最后判断offset
- slave宕机重启
- 如果发生了更换,客户端放如何知道? 通知客服端
心跳监控
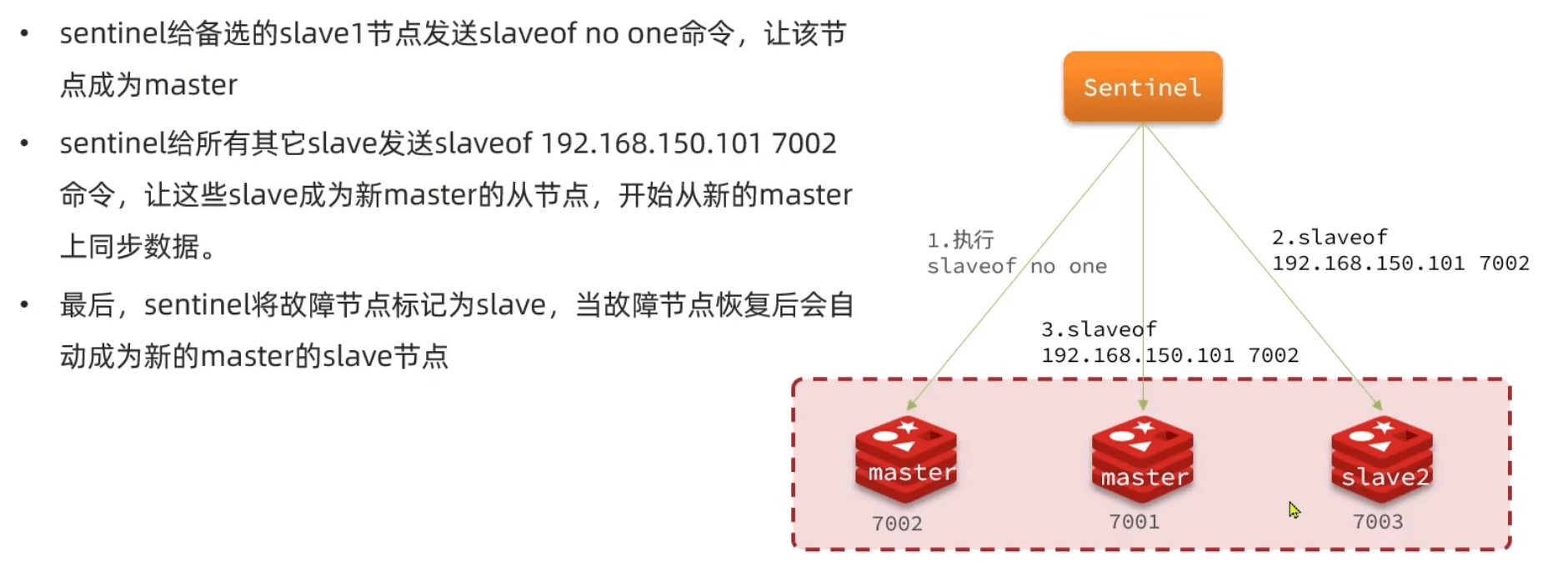
迁移master
- 备选的变成master
- 通知其他slave
- 原来master配置文件改为slaveof new
搭建
sentinel.conf

启动 redis-sentinel path.conf
感知切换
redistemplate基于lettuce实现感知自动切换
不需要配置redis地址,而是sentinel地址


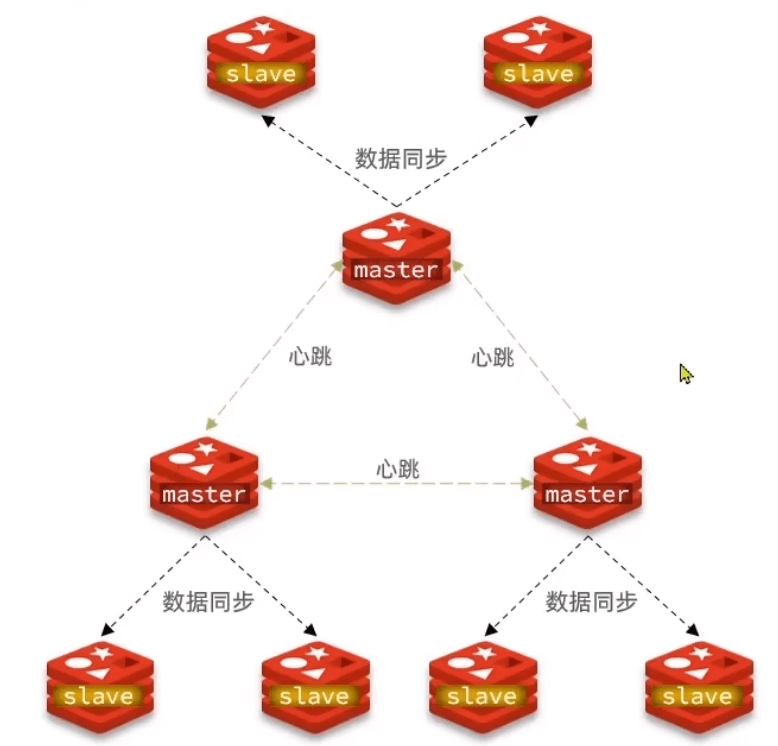
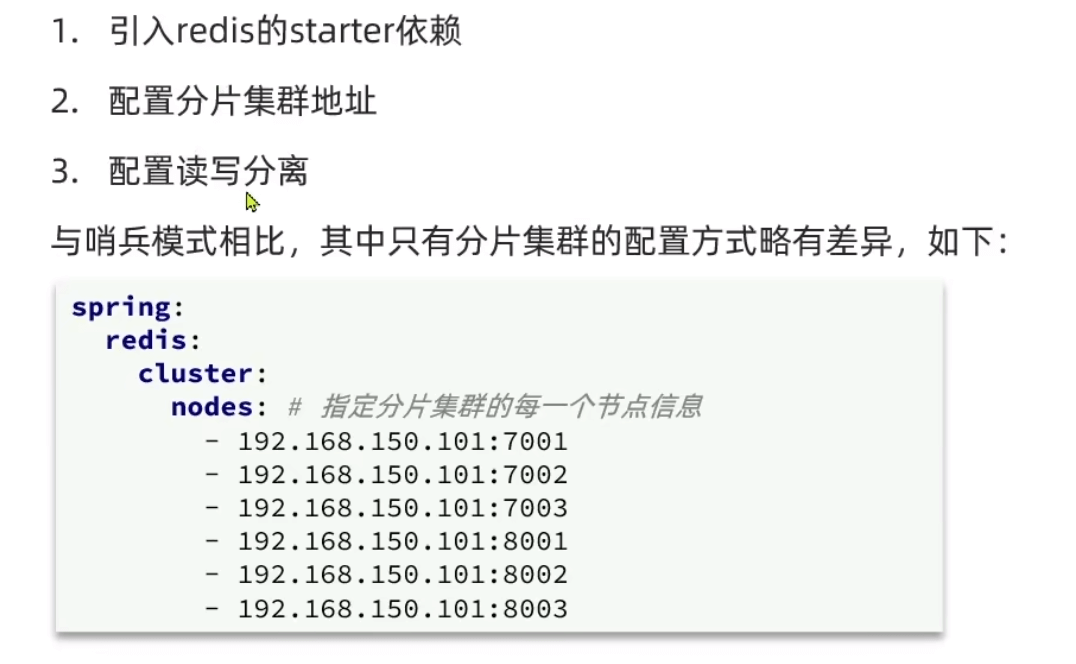
分片集群
前面的问题:1.海量数据存储 2.高并发的写操作
- 多个master 保存不同的数据 通过插槽实现;master之间可以同时执行命令,高性能
- master之间相互检测健康 不需要sentinel;高可用
- 访问集群的任意节点,会自动转发到正确节点
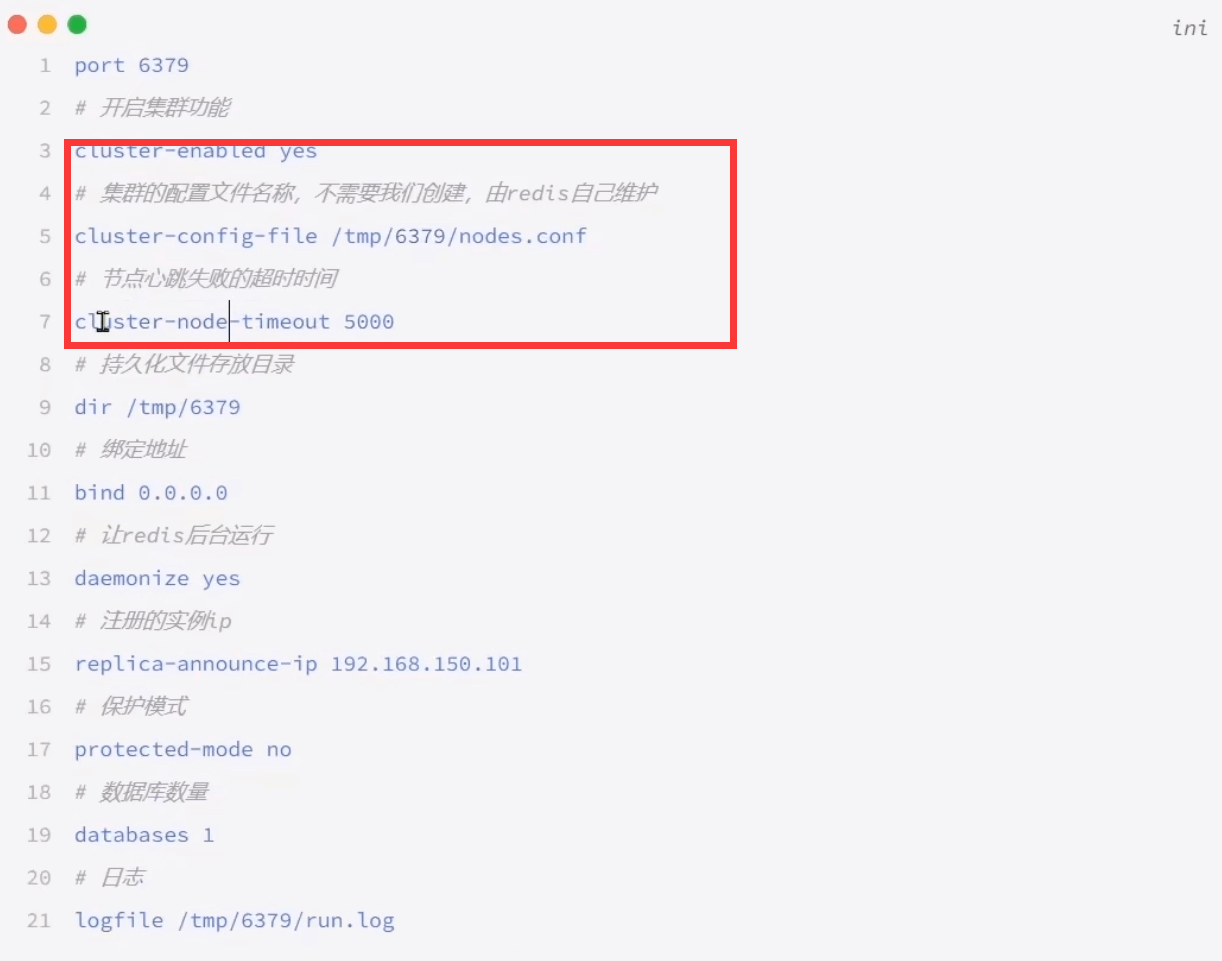
配置
1.启动 master slave所有的都一样, config-file每个人都有自己的 当前启动后相互还没有关系
2.创建集群
redis-cli --cluster create --cluster-replicas 2 ip1 ip2 ....
1 | |
一个master对应两个slave,前面的ip为master
查看集群状态 :redis-cli -p 7001 cluster nodes
连接:redis-cli -c -p 7001
散列插槽
每一个master都会散列到0~16383个插槽上的一部分

key的有效部分{hash_tag}(控制某一类在一个redis上)也会hash计算插槽%16384,得到插槽位置:数据和插槽绑定
集群伸缩
redis-cli --cluster help
redis-cli --cluster add-node ip:port 集群ip:port
分配插槽
1 | |
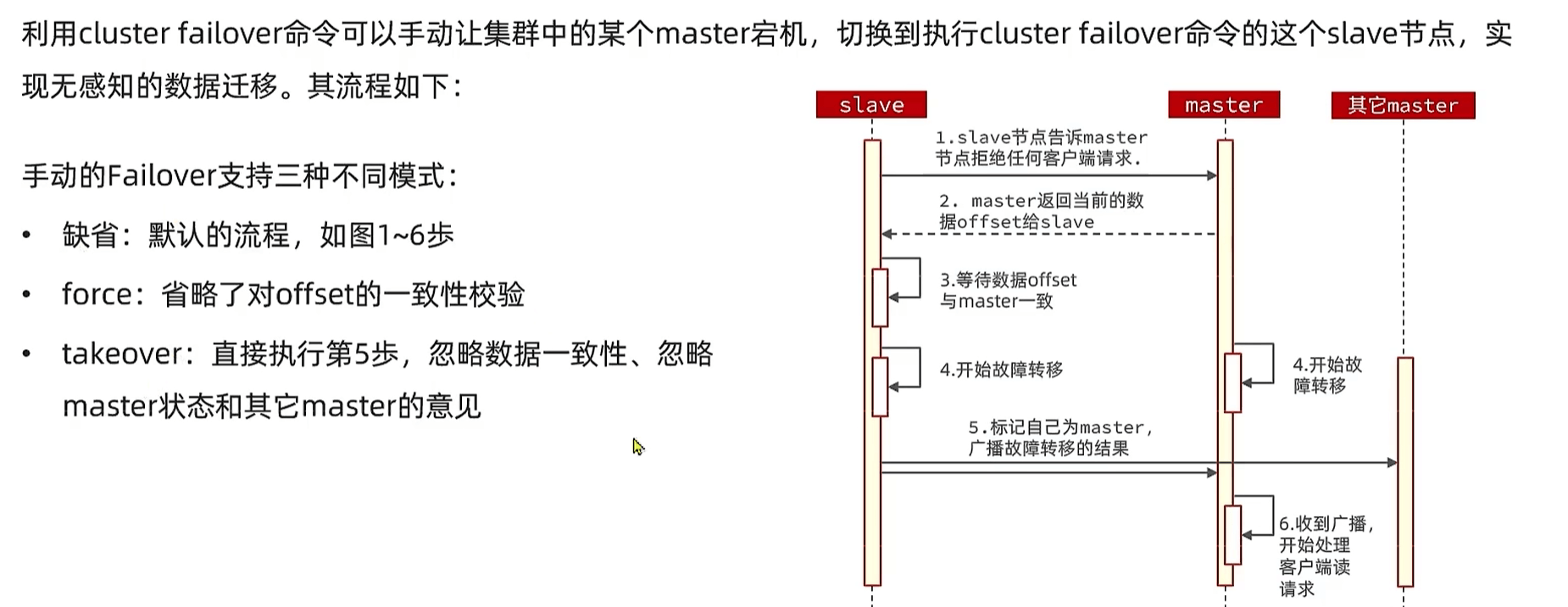
故障转移
当一个master宕机?
集群可以实现自动切换,master宕机换下一个slave,slave也宕机插槽就宕机了
手动转移:进入到slave CLUSTER FAILOVER
代码
多级缓存
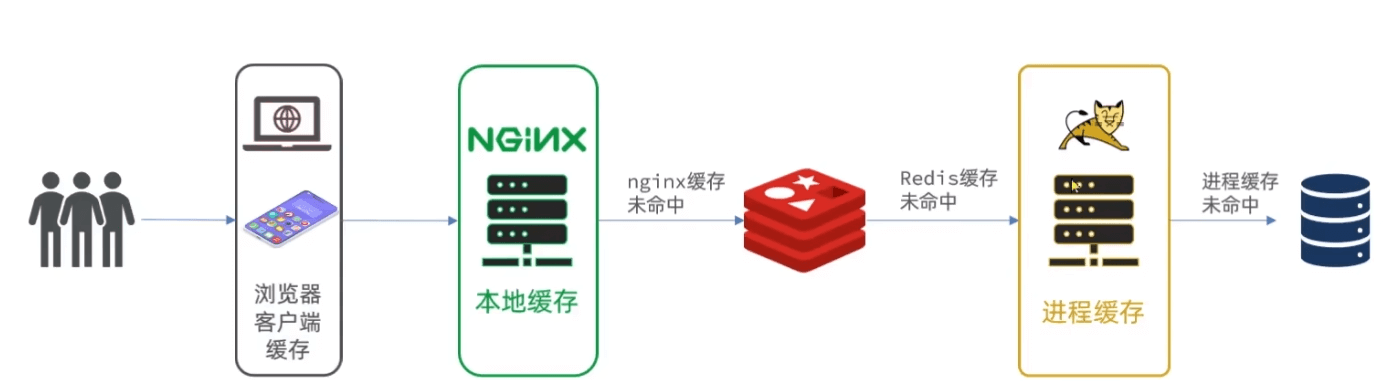
最佳实践
键值设计
key
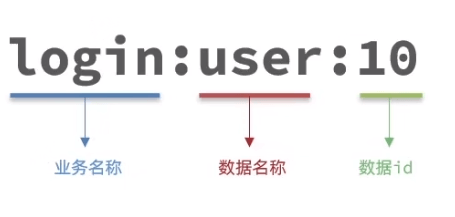

bigkey

合适数据结构
存储对象:
- json字符串 方便
- 直接打散,一个字段一个key value 浪费空间
- hash;entry不超过1000 如果太大拆分取模成多个hash
批处理优化
Pipeline
单次:网络延时(ms级)+执行延时(us级) 一次执行多条指令,如mset,但收到指令集的限制
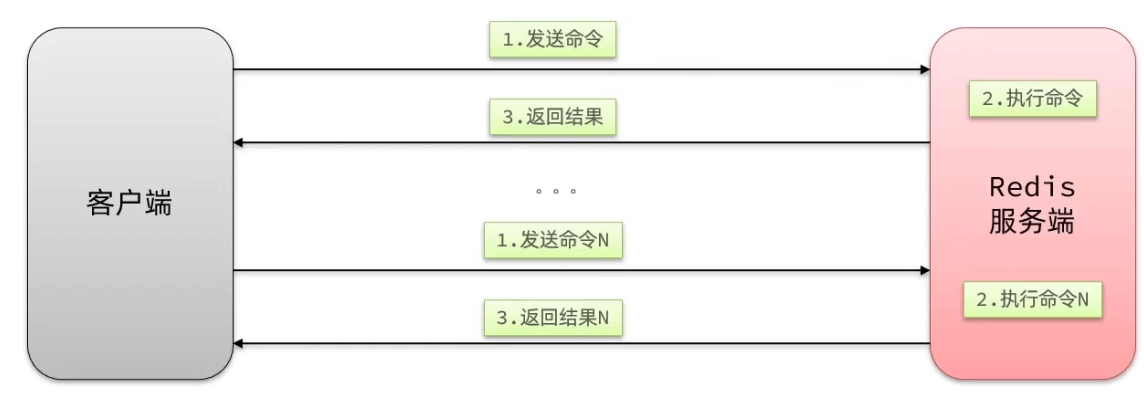
pipeline:不受指令限制,一次发送多条指令,不具备原子性

问题:在集群下,多个命令(pipeline mset)必须要在同一个插槽,才能映射到一台机器上
集群下的批处理
mset默认情况下如果key在不同节点上,会报错
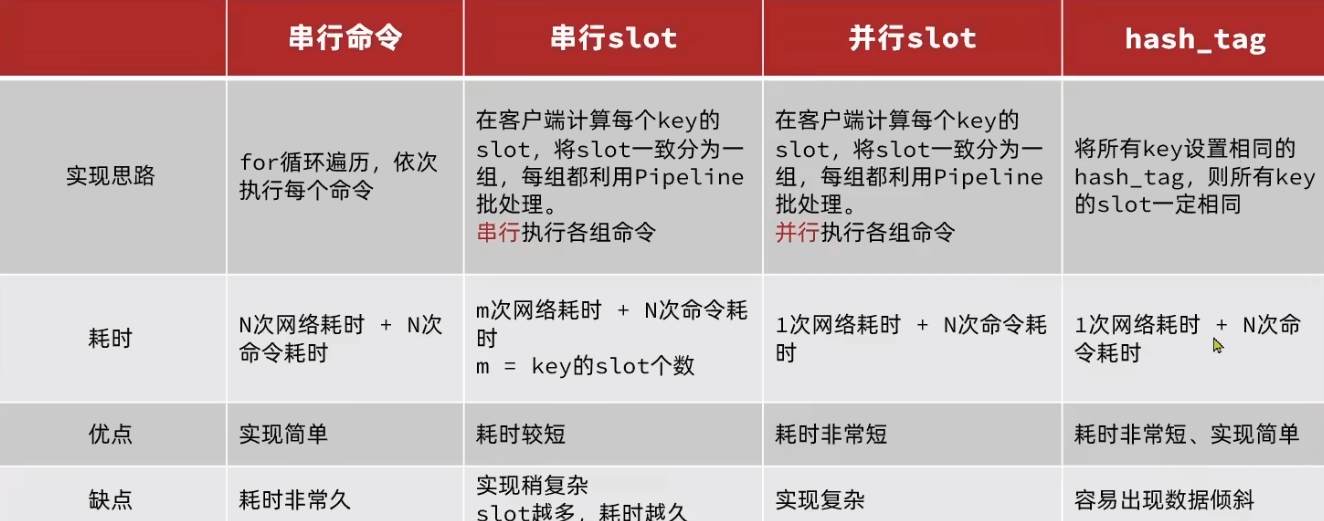
集群下,spring mset就会默认按照插槽划分,并且创建线程异步并行执行(方法三)
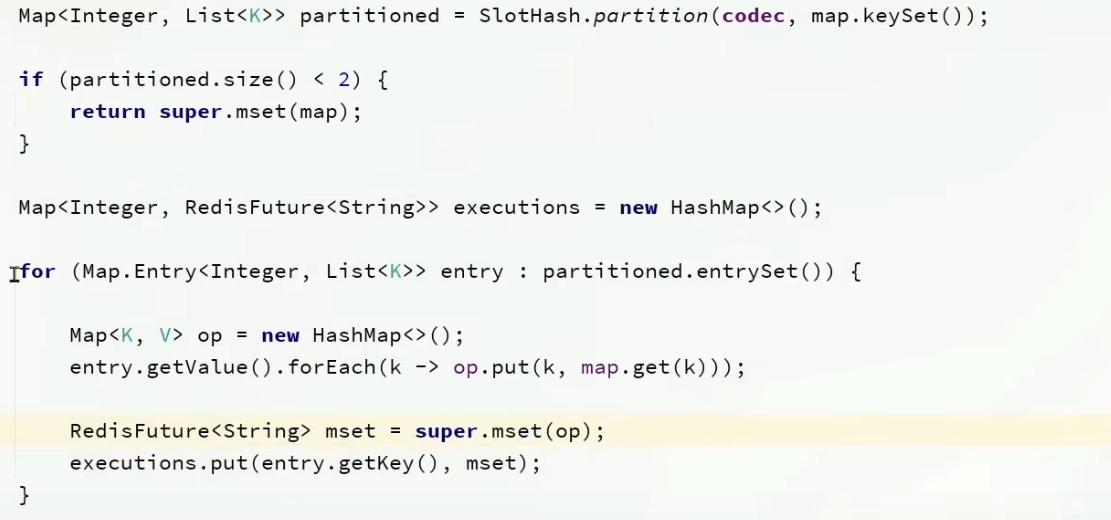
服务端优化
持久化配置
- 缓存的redis实例开启一个单独实例,不需要做持久化
- 为了安全性使用AOF,RDB定期手动进行备份

慢查询
单线程任务,慢查询会影响其他命令
1 | |
SLOWLOG GET <n> 命令来获取慢查询日志中的最近 N 条记录,或使用 SLOWLOG RESET 命令清空慢查询日志
命令及安全配置
在没有密码并且root启动redis时,修改rbd文件指向ssh文件,并设置value为公钥即可
- 上线时禁用flushdb, config set 等命令,通过
rename command - bind绑定局域网网卡
- 开启防火墙
- 不要使用root启动
- 非默认端口,设置密码
内存配置


MEMORY STATS 命令将返回以下统计数据:
peak.allocated:Redis 运行期间分配的内存峰值。total.allocated:Redis 运行期间分配的总内存量。startup.allocated:Redis 启动时分配的内存量。replication.backlog:复制积压缓冲区使用的内存量。clients.slaves:连接的从节点数量。clients.normal:连接的普通客户端数量。aof.buffer:AOF 缓冲区使用的内存量。lua.caches:Lua 脚本缓存使用的内存量。overhead.total:Redis 内部开销占用的内存量。dataset.bytes:数据集占用的内存量。dataset.keys:数据集中键的数量。
集群 or 单体
当部分插槽不可用时(master slave都宕机),默认集群宕机
cluster-require-full-coverage yes
节点中会互相ping监控状态,如果集群数量太多,ping也需要大量的带宽

原理
数据结构
SDS
1 | |
- 可以避免缓冲区溢出:C 语言中的字符串被修改(比如拼接)时,一旦没有分配足够长度的内存空间,就会造成缓冲区溢出。SDS 被修改时,会先根据 len 属性检查空间大小是否满足要求,如果不满足,则先扩展至所需大小再进行修改操作。
- 获取字符串长度的复杂度较低:C 语言中的字符串的长度通常是经过遍历计数来实现的,时间复杂度为 O(n)。SDS 的长度获取直接读取 len 属性即可,时间复杂度为 O(1)。
- 减少内存分配次数:为了避免修改(增加/减少)字符串时,每次都需要重新分配内存(C 语言的字符串是这样的),SDS 实现了空间预分配和惰性空间释放两种优化策略。当 SDS 需要增加字符串时,Redis 会为 SDS 分配好内存,并且根据特定的算法分配多余的内存,这样可以减少连续执行字符串增长操作所需的内存重分配次数。当 SDS 需要减少字符串时,这部分内存不会立即被回收,会被记录下来,等待后续使用(支持手动释放,有对应的 API)。
- 二进制安全:C 语言中的字符串以空字符
\0作为字符串结束的标识,这存在一些问题,像一些二进制文件(比如图片、视频、音频)就可能包括空字符,C 字符串无法正确保存。SDS 使用 len 属性判断字符串是否结束,不存在这个问题。
动态扩容
预分配多一点内存可以减少分配次数

IntSet
1 | |
为了方便查找,会有序、唯一存放(二分)。根据所占字节以及index索引 start + index * encoding
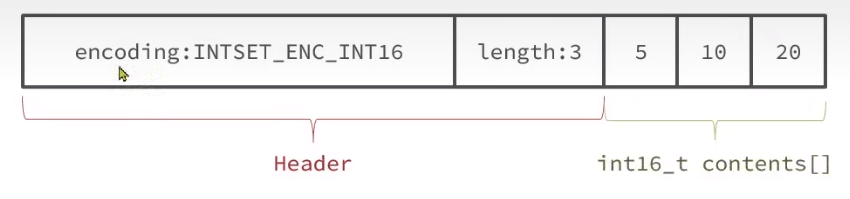
如果存放的数超过了范围,会升级。需要将元素移动到合适位置
适合数据量不大Set,有序方便查找某一个元素是否在集合中
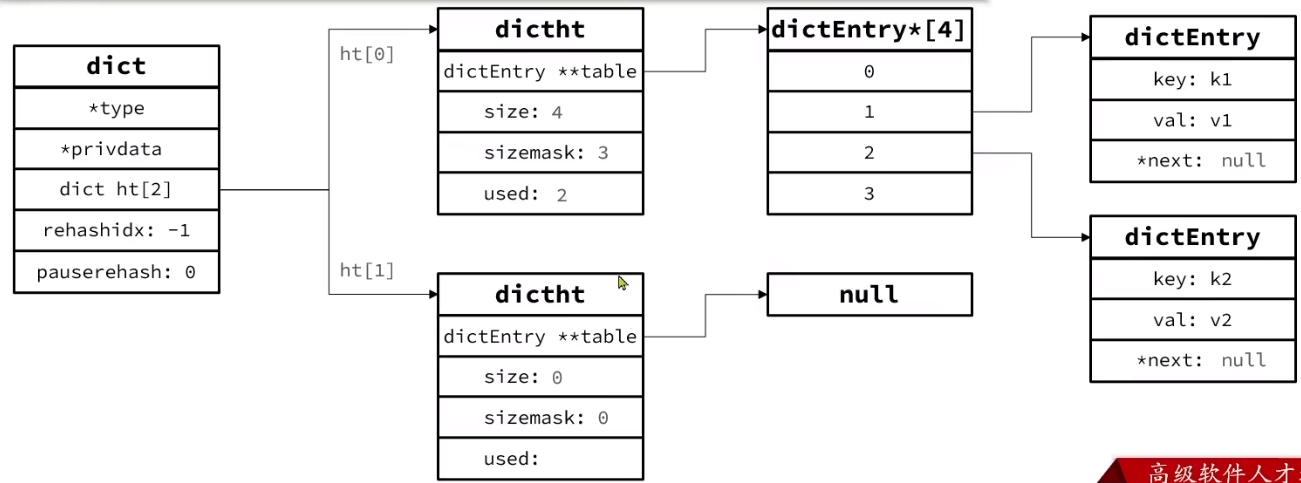
Dict
key-value pair通过Dict实现,实现原理和java的hashmap很像,同样是2^n^大小的数组+链表
扩容时触发rehash

两个ht用于扩容时存放新的hash表
渐进扩容
除了扩容,此外如果LoadFactor < 0.1会收缩

将空间申请到dict.ht[1],此外标记rehashidx=0代表迁移工作开始
渐进rehash:每次执行新增、查询、修改、删除操作时,都检查一下dict.rehashidx是否大于-1, 如果是则将dict.ht[0].table[rehashidx]的entry链表rehash到dict.ht[1](需要重新计算hash),并且将rehashidx++。直至dict.ht[0]的所有数据都rehash到dict.ht[1]
如果rehash在进行中,删改查需要在两个table中都去找,增加直接到dict.ht[1]
最后将ht[0]指向ht[1]
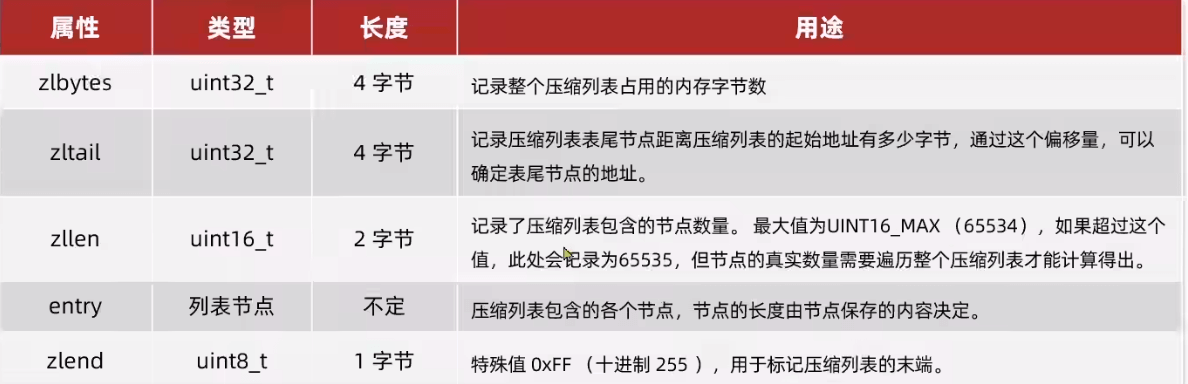
ZipList
连续空间(所以不能太大;4~64kb)的双端链表,节省内存和提供快速的顺序访问
- 指针也要占内存(8B),如何节约? 通过分配连续内存,并记录下前一个entry的长度实现前遍历,当前长度通过encoding记录。更少的内存碎片
- 不能随机读取
- 适用于顺序读取(或两端读取)操作频繁,写入操作较少 以及 小型集合(数小、数量少)
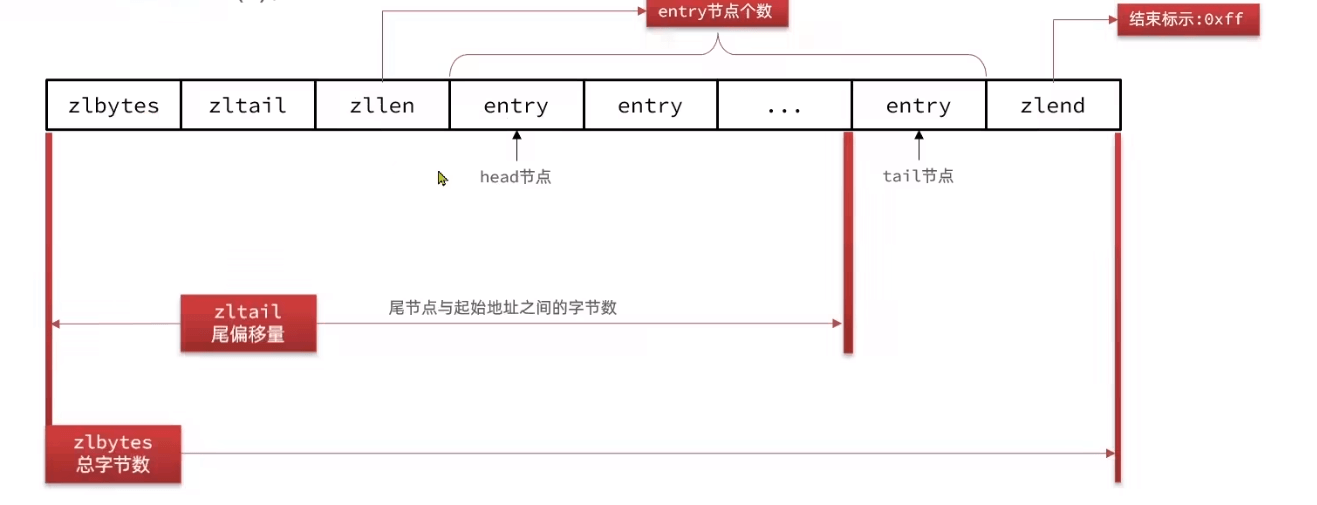
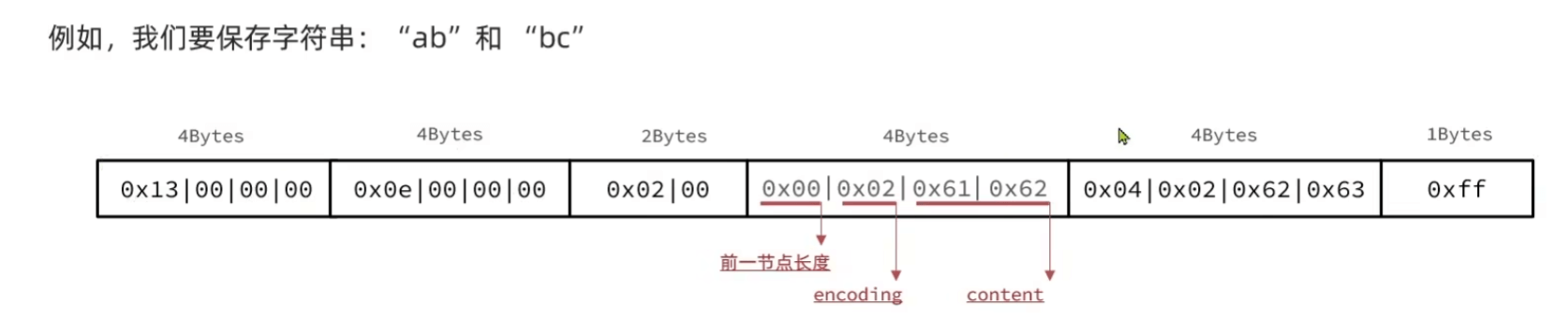
entry:previous用于向前遍历,encoding记录当前长度

encoding

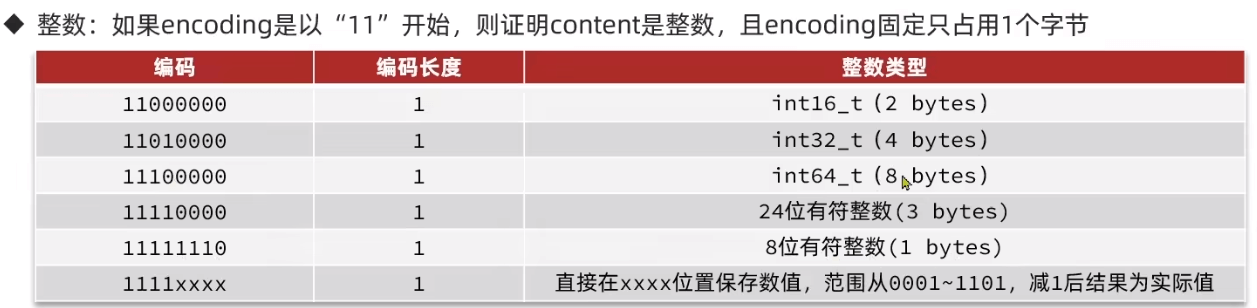
连锁更新问题
连续保存多个253B数据:长度保存字段1B或5B,如果前一个过长当前就要变成5B,导致当前entry超过254连锁更新下一个节点

QuickList
ZipList需要连续空间,找不到怎么办?
QuickList链表连接多个ZipList,兼具链表(非连续空间)数组(节约内存)的优点
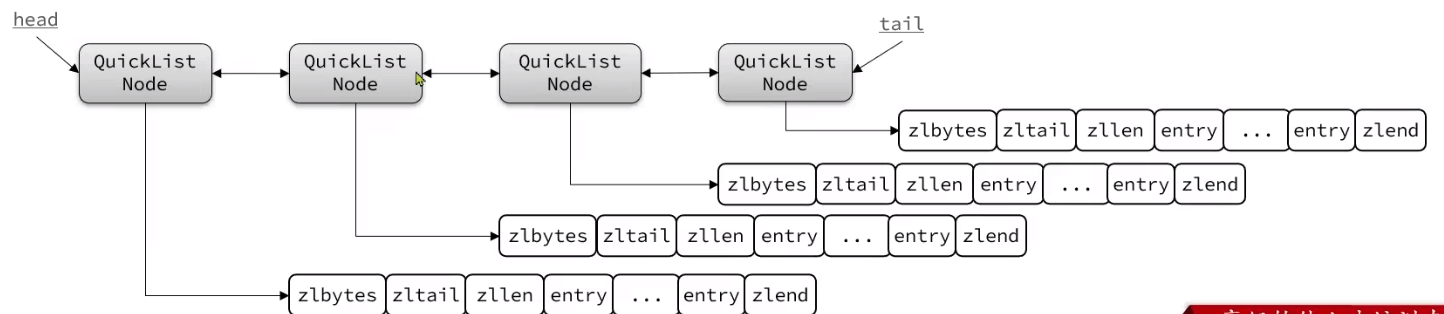
list-max-ziplist-size:限制ziplist的entry数量或内存大小list-compress-depth:是否压缩中间节点以及压缩的深度

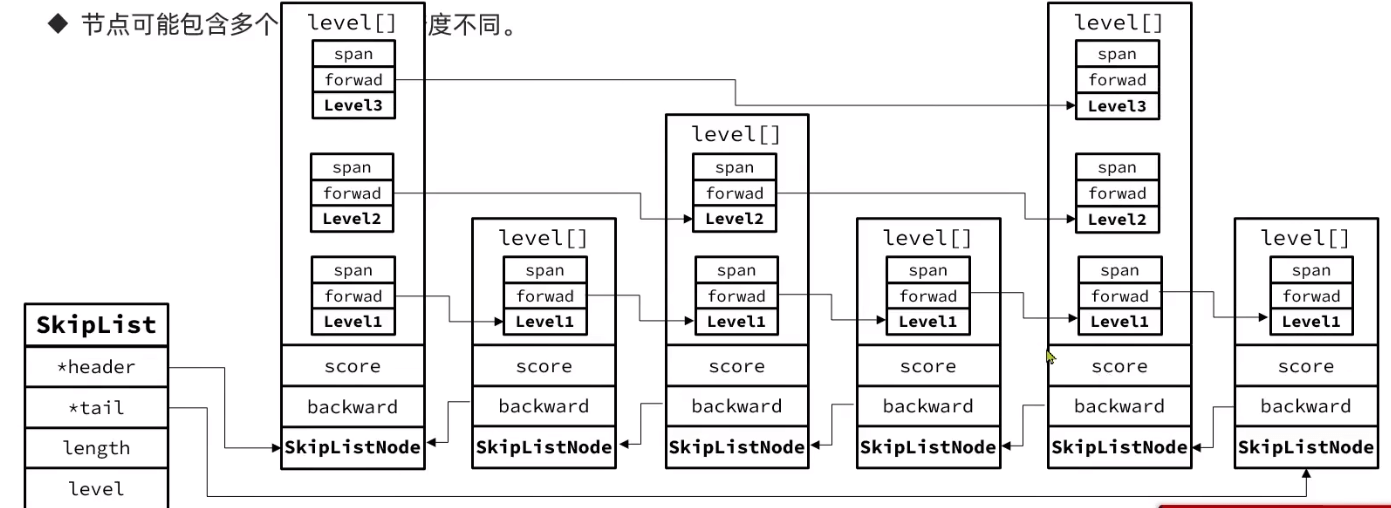
SkipList
QuickList需要全部遍历,如何实现LogN随机查询?
- 顺序存储
- 包含多个指针,指针的跨度不同(最多32级)
- 查找过程向右或向下走
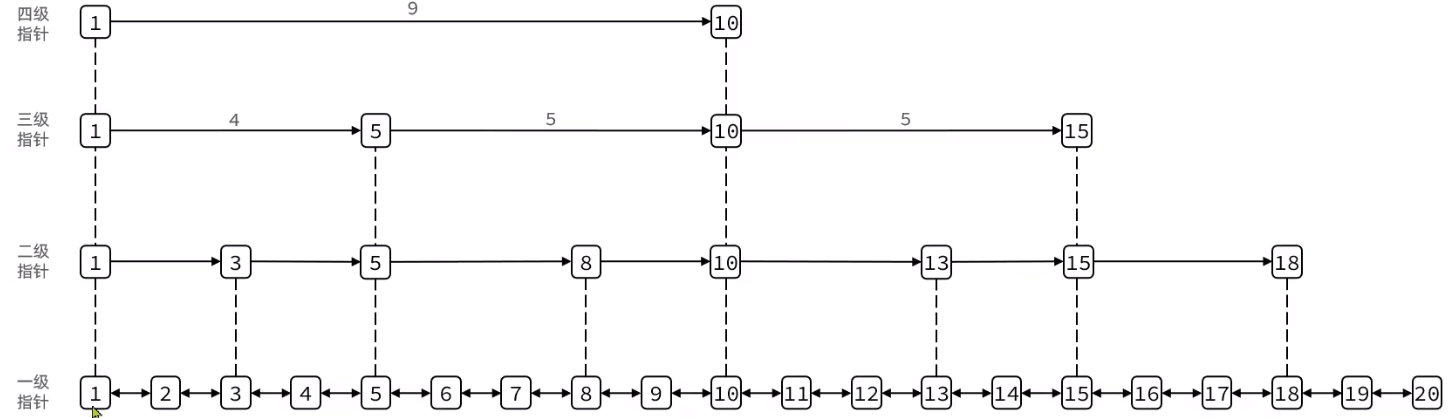
每一个节点有一个下一个节点数组,不同节点数组长度不同

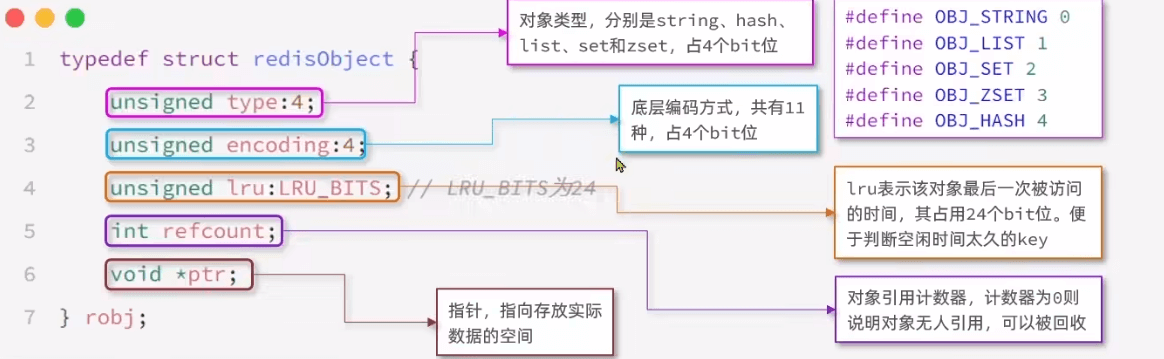
RedisObject
Redis中的键值都会被封装为RedisObject,头需要16B
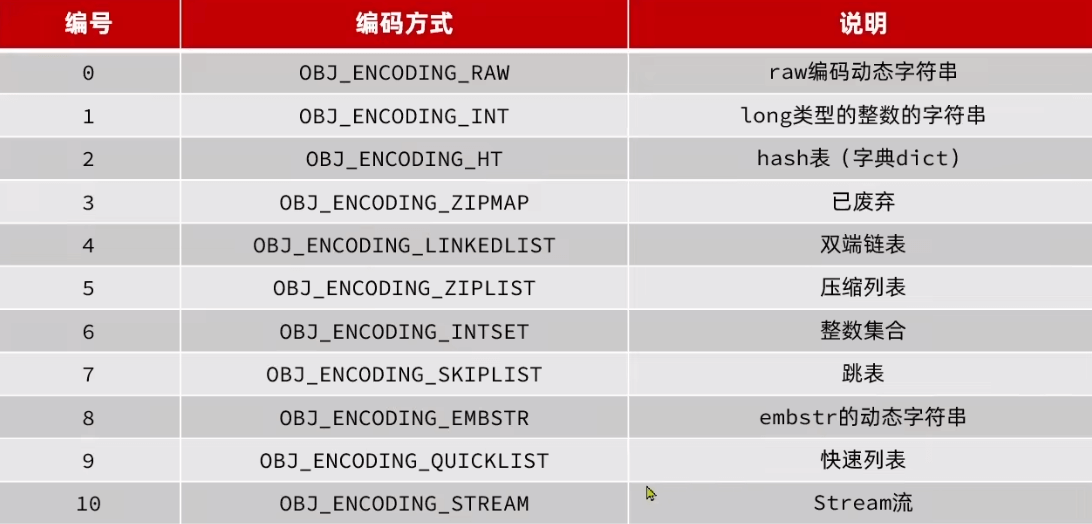

数据结构
数据量小的时候,尽量节约空间;数据量大不得不空间换时间
String
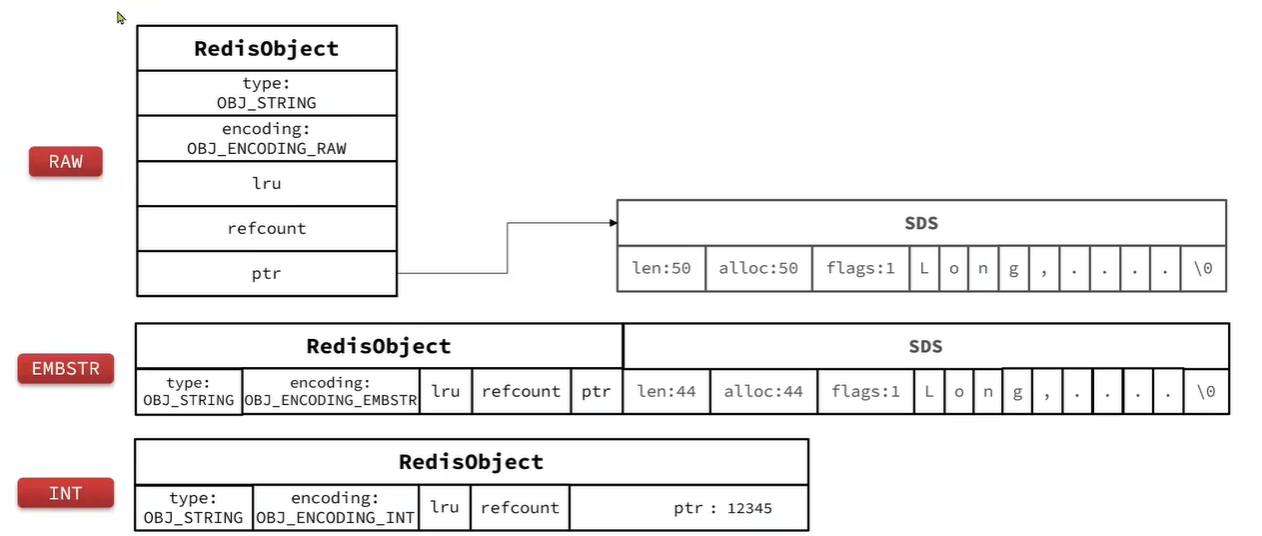
- 其基本编码方式是RAW,基于简单动态字符串(SDS)实现,存储上限为512mb。
- 如果存储的SDS长度小于44字节,则会采用EMBSTR编码,此时object head与SDS是一段连续空间。 申请内存时只
需要调用1次内存分配函数,效率更高。(小于44字节,一共分配小于64) - 如果存储的字符串是整数值,并且大小在LONG_ MAX范围内,则会采用INT编码:直接将数据保存在RedisObject的
ptr指针位置(刚好8字节) ,不再需要SDS了。
List
- LinkedList :普通链表,可以从双端访问,内存占用较高,内存碎片较多 3.2之前
- ZipList :压缩列表,可以从双端访问,内存占用低,存储上限低 3.2之前
- QuickList 3.2之后
set
- 唯一 但 不有序
- 需要求交集、并集、差集
需要高效判断元素是否存在:Hash, key来存储元素,value=null。如果都是int,会使用intset
1 | |
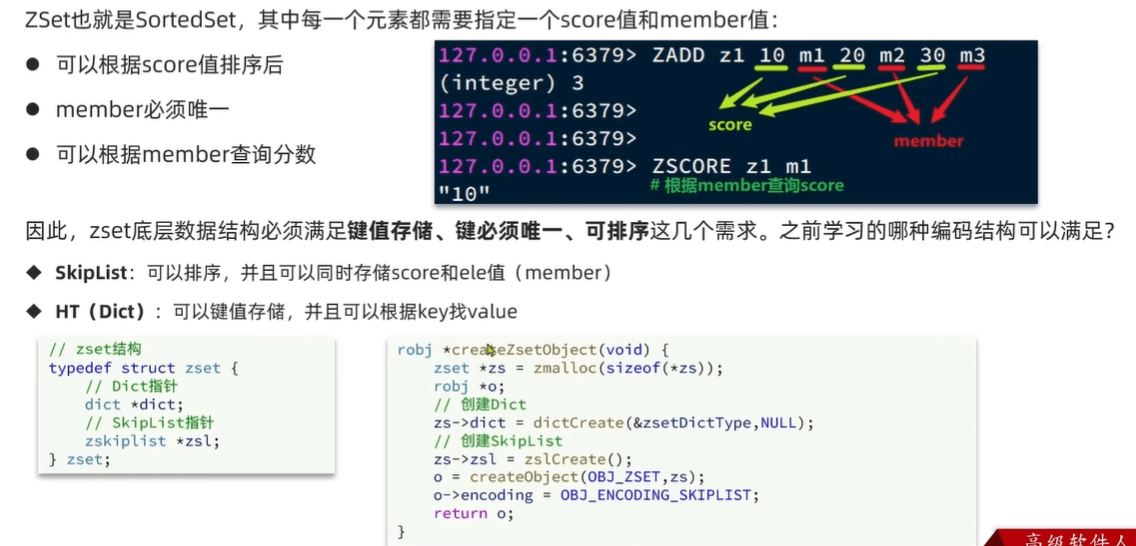
Zset
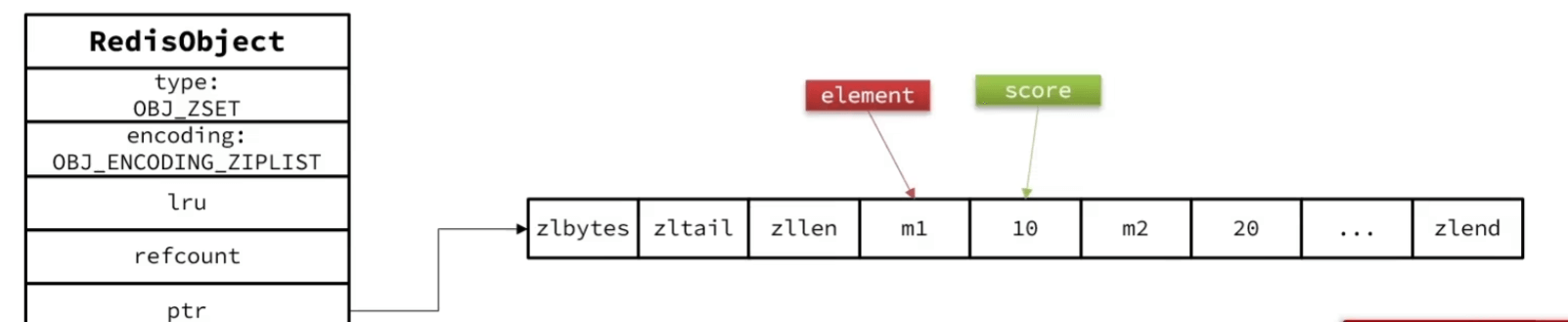
元素少直接用zipList,两个entry 分别保存element和score;score小的在前面
Hash
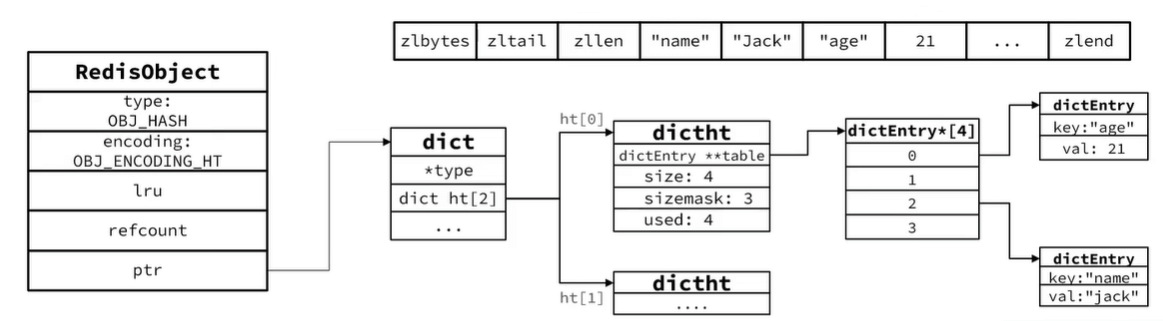
- Hash结构默认采用ZipList编码,用以节省内存。ZipList中相邻的两个entry 分别保存field和value
- 当数据量较大时,Hash结构会转为HT编码,也就是Dict, 触发条件有两个:
- ZipList中的元素 数量超过了hash-max-ziplist-entries (默认512)
- ZipList中的任意entry大小超 过了hash-max-ziplist-value ( 默认64字节)
网络模型
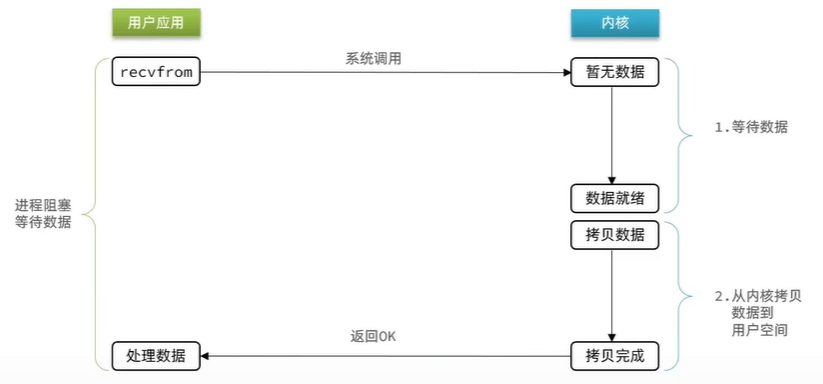
阻塞IO
一直等
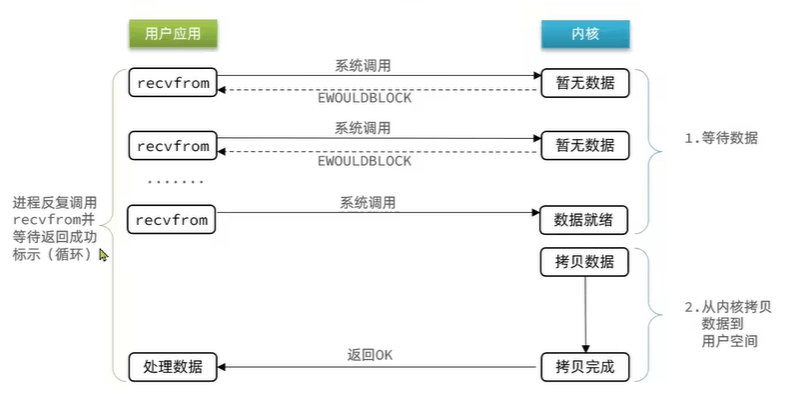
非阻塞IO
请求时,如果数据不存在,不阻塞
还是不断询问,存在大量无效的询问
优化:一个线程监听多个FD,并且在就绪时得到通知
select
linux中最早的多路复用策略
只返回数量。知道有FD就绪了,但不知道是谁,需要遍历全部FD数组,查看谁变成了1

- fd_set需要拷贝两次,用户->内核->用户
- 每次需要遍历全部获取到底哪些就绪了
- 最多1024个

poll
使用一个数组保存(实现数量不被限制了,fds在内核中会转为链表;但太长会影响性能),同样返回就绪的数量

epoll
- 使用
epoll_create创建一个epoll实例(内核中),返回一个文件描述符。 - 使用
epoll_ctl将需要监听的文件描述符注册到epoll实例中,设置关注的事件类型(比如可读、可写等)。 - 使用
epoll_wait等待事件的发生,当文件描述符上的事件状态发生变化时,epoll_wait会返回就绪的文件描述符到用户空间的events中。
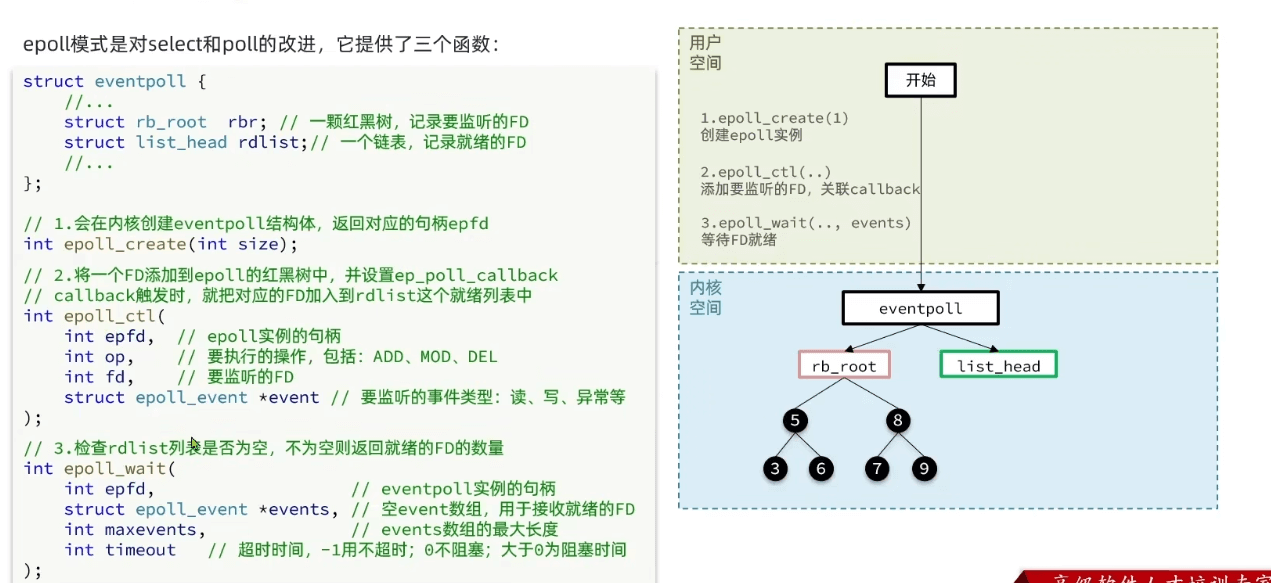
CTL添加时,只添加到红黑树一次;wait只拷贝就绪的event,减少拷贝- 只返回就绪的,不用遍历
- 使用红黑树提高CRUD性能
- LevelTriggered: 简称LT。当FD有数据可读时,会重复通知多次,直至数据处理完成。是Epoll的默认模式
- EdgeTriggered:简称ET。当FD有数据可读时,只会被通知一-次, 不管数据是否处理完成

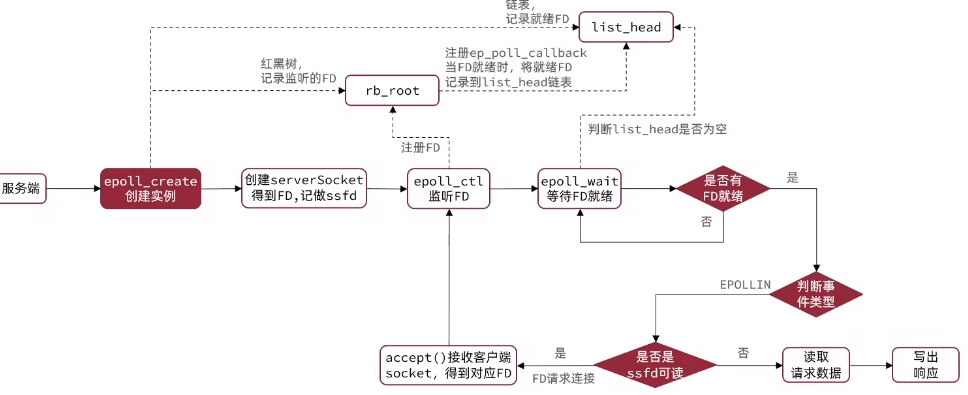
epoll服务端
信号驱动IO
在数据好了的时候通过信号通知
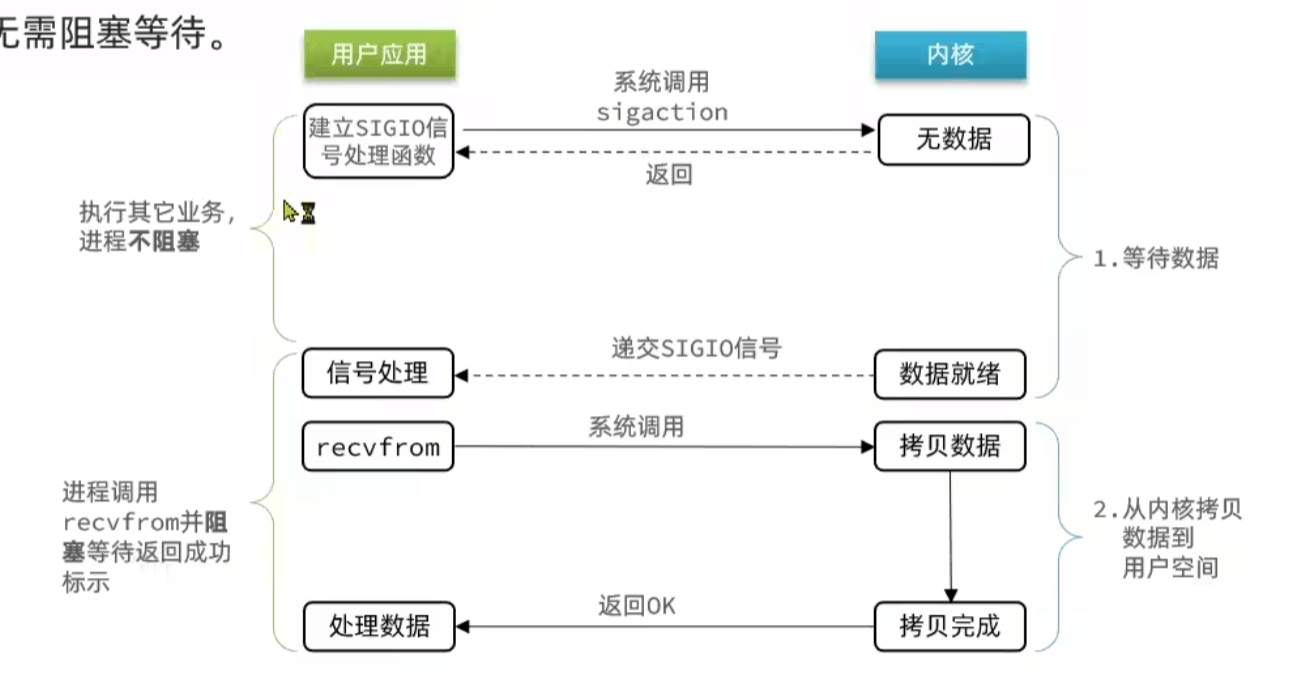
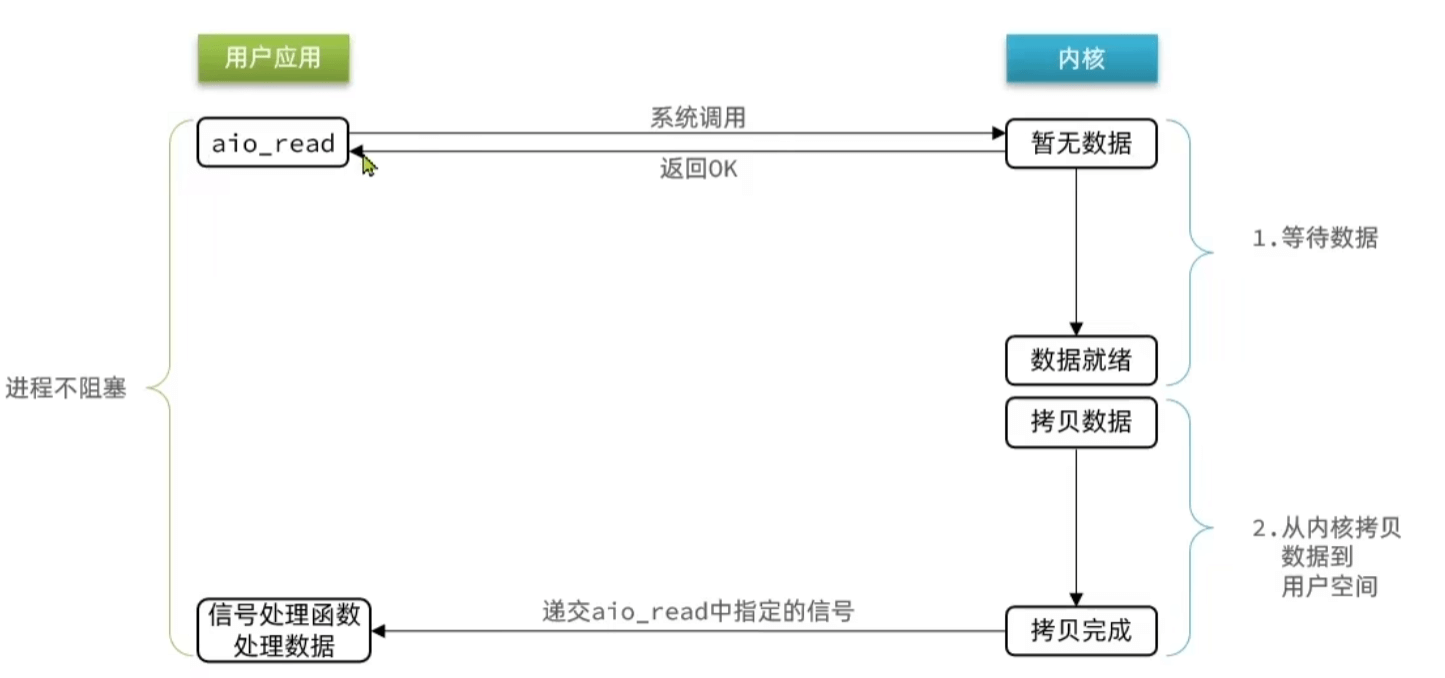
异步IO
交给内核去拷贝数据
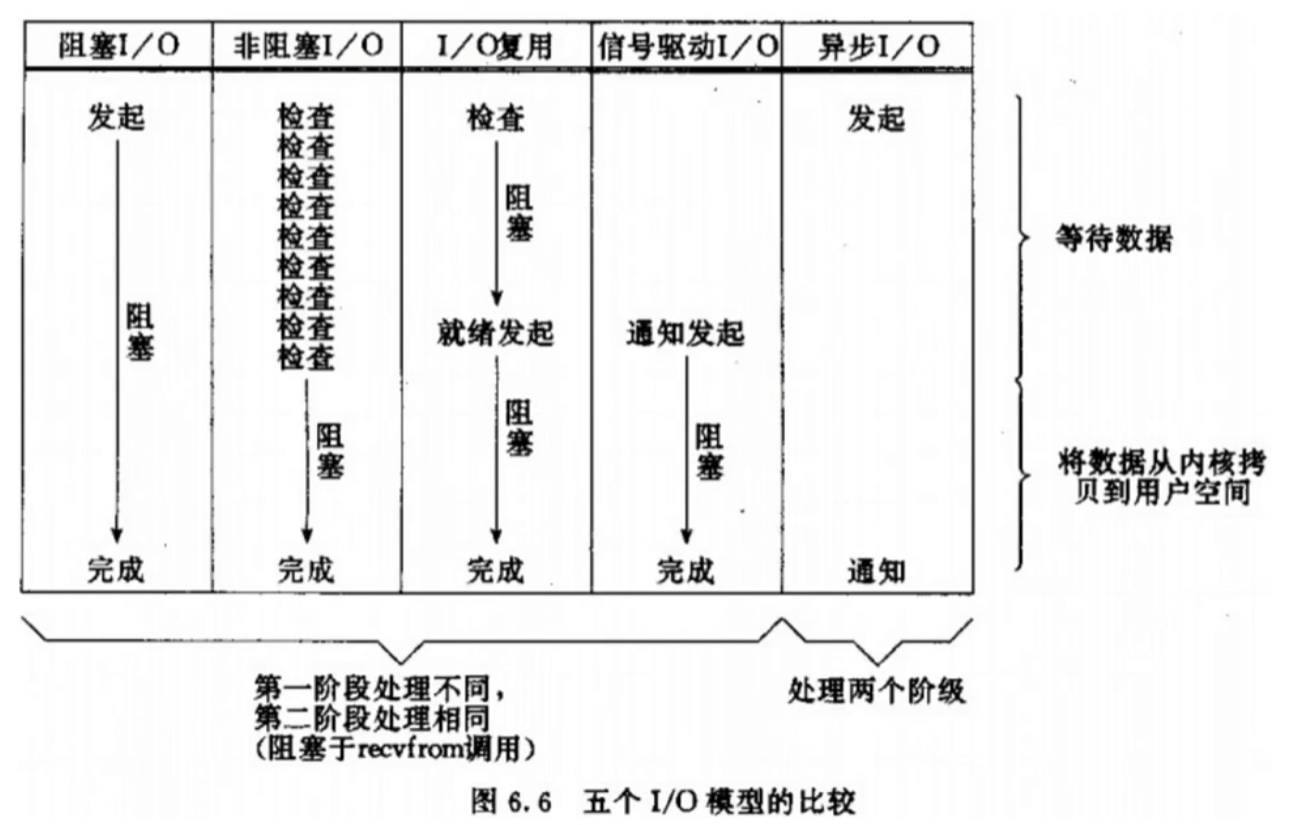
总结
都包含两个部分:等待数据就绪、拷贝数据
redis网络模型




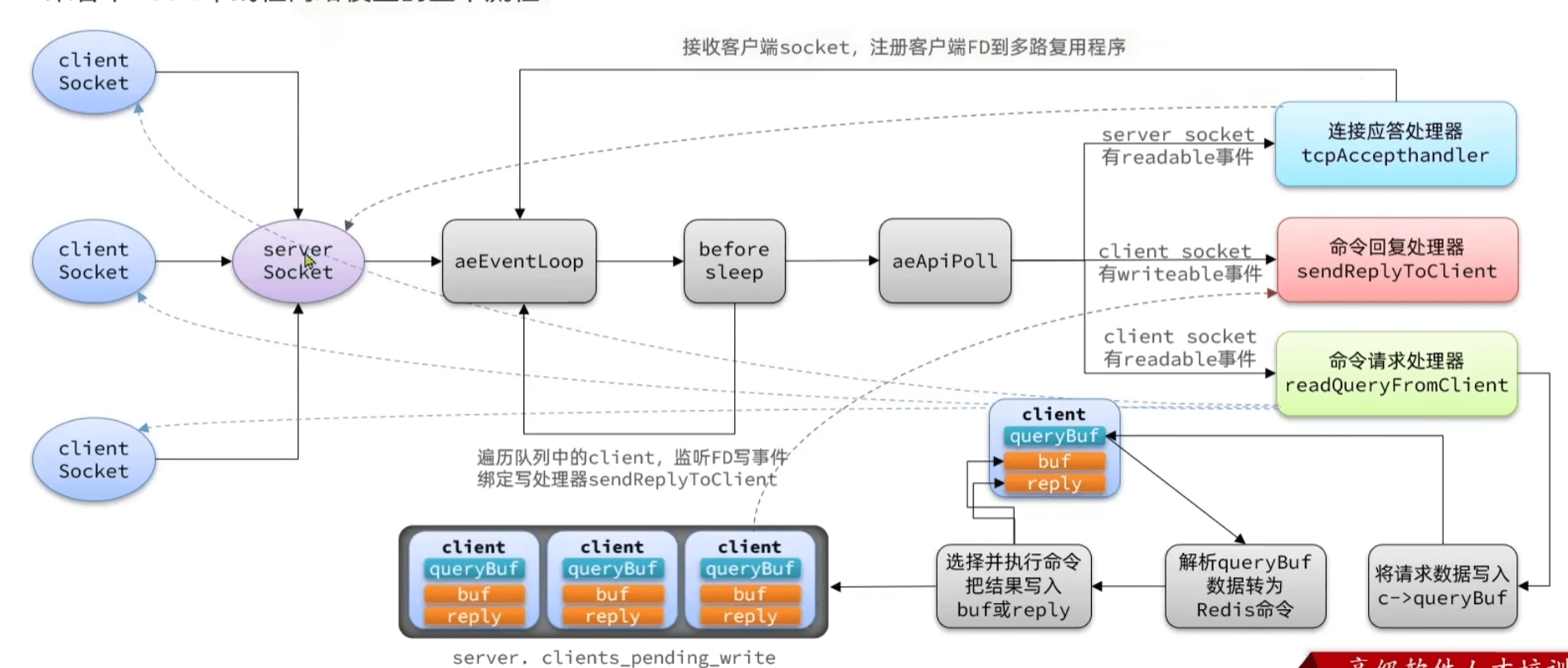
- epoll中监听包含SSFD读(接受新连接;
tcpAccepthandler)、FD读(每一个客户端来了请求;readQueryFromClient)、FD写(写返回值给客户端;sendReplyToClient) 都包含了一个回调处理器 - 瓶颈在于io,包含接受命令以及返回结果
多线程:
- 多线程读取客户端中socket数据并且解析成命令
- 多线程去clients_pending_write中取结果
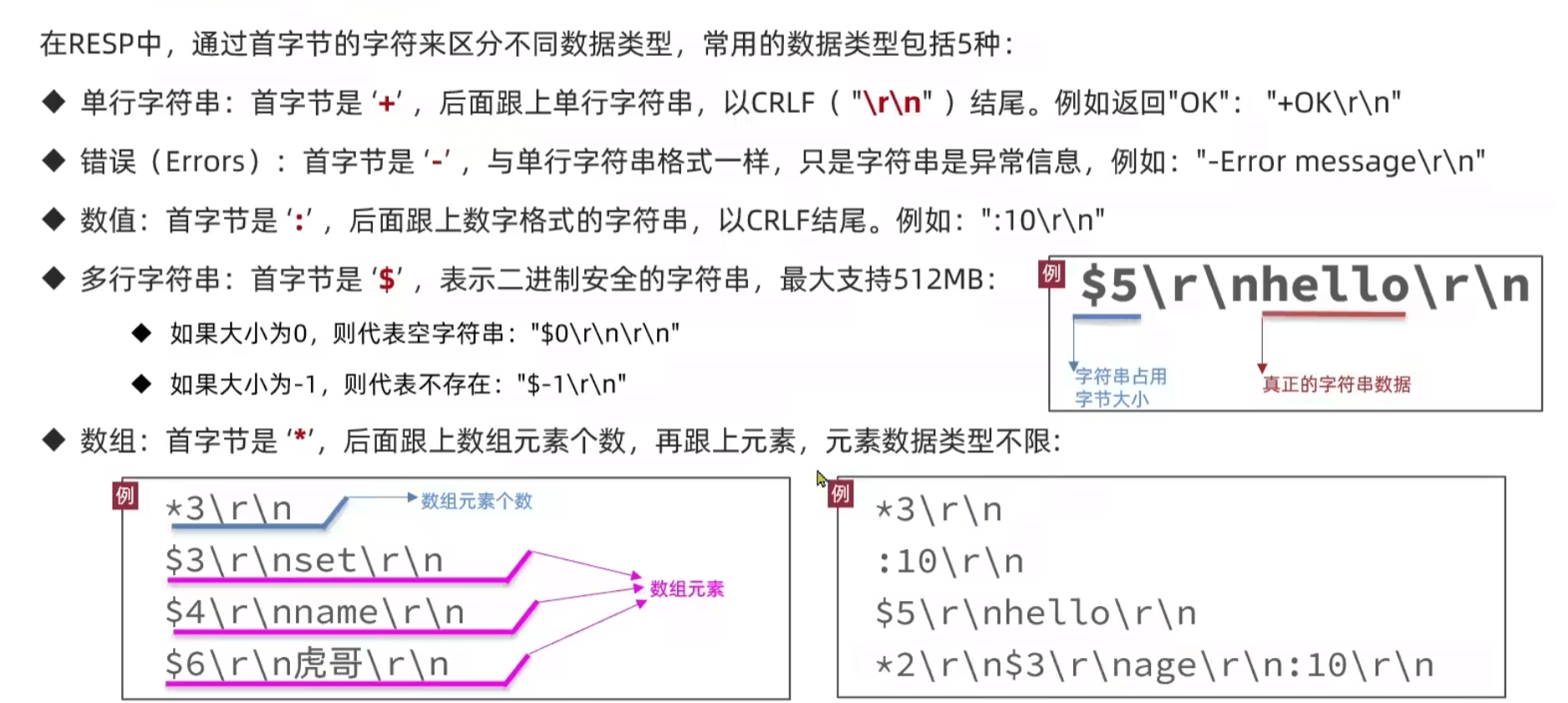
通信协议RESP
- 客户端发送请求
- 服务端接受执行命令并返回
使用socket实现发送和接收
过期策略
一个dict存key-value,另一个key-ttl

- 惰性删除:操作时才判断是否删除
- 周期删除:定时任务serverCron删除(低频大量)、fast beforeSleep在每个事件循环都会执行 (高频少量)

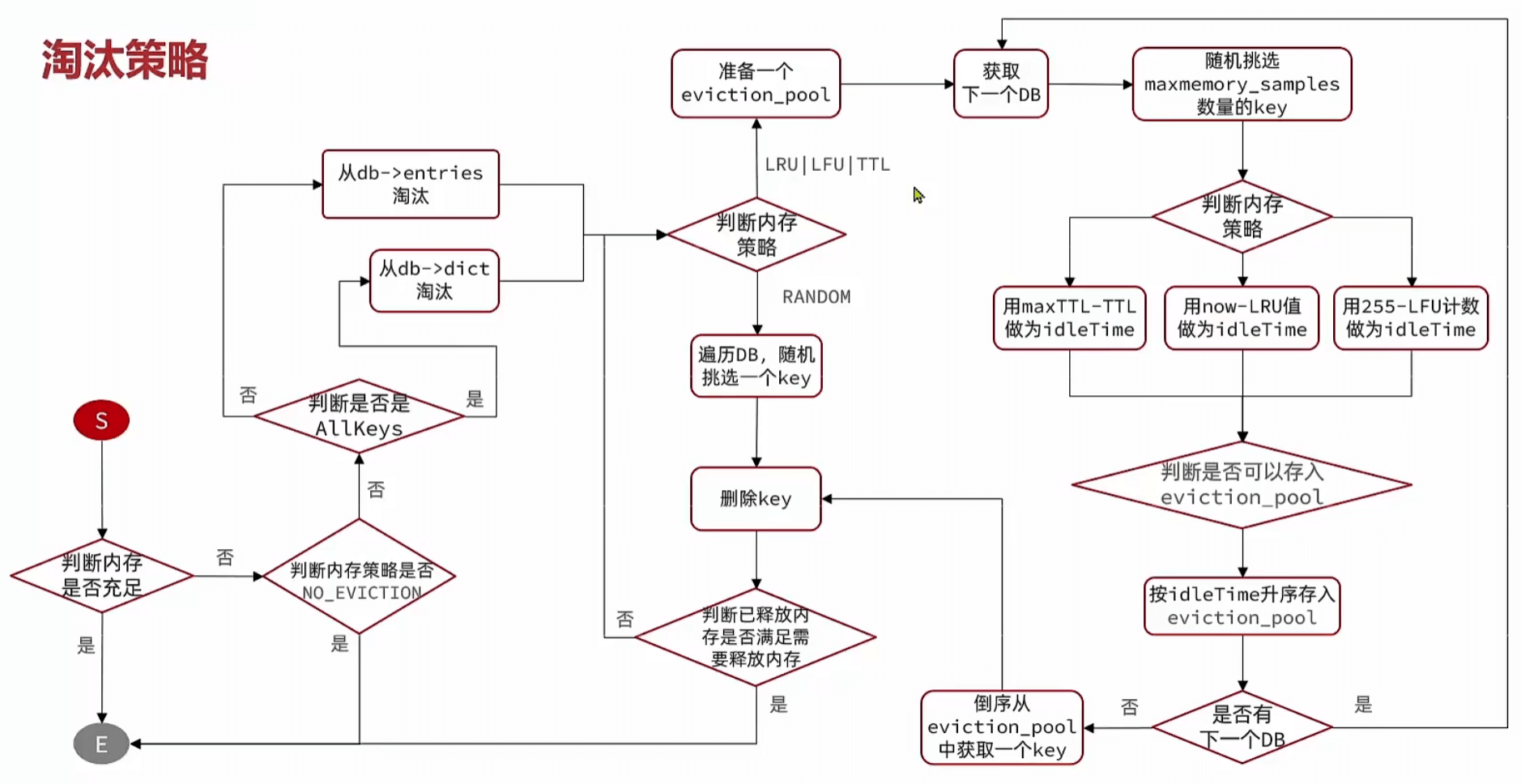
内存淘汰策略
在内存不够时,主动删除部分key, processCommand前会执行

LRU和LFU在redisObject里记录了,因此后面删除的时候其实时拉取了一些随机样本(eviction_pool)来比较,而不是所有样本的LRU
LFU记录的是一个概率统计值,并且有使用定时衰减